 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edgei-SpaSP: Structured Neural Pruning via Sparse Signal Recovery
Dec 07, 2021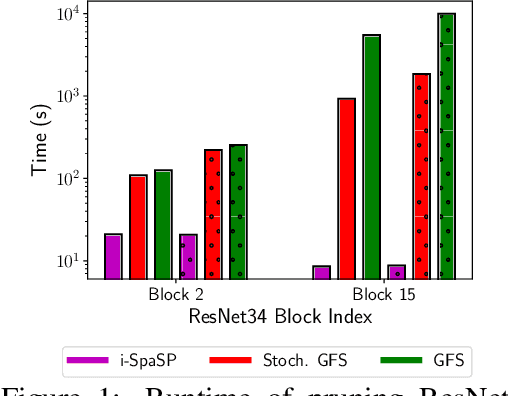
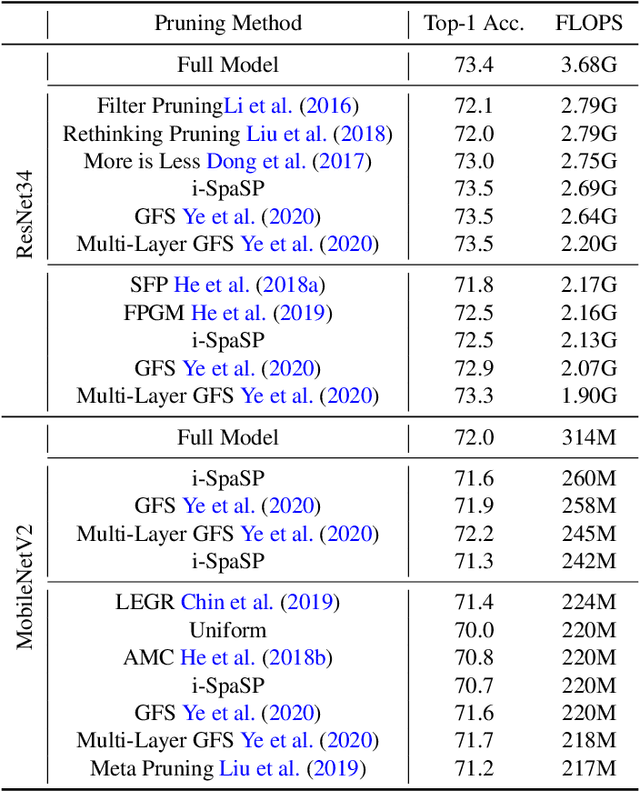
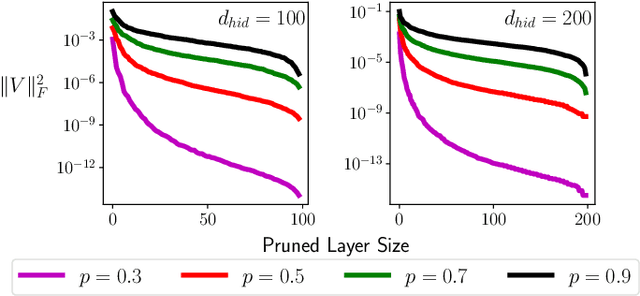
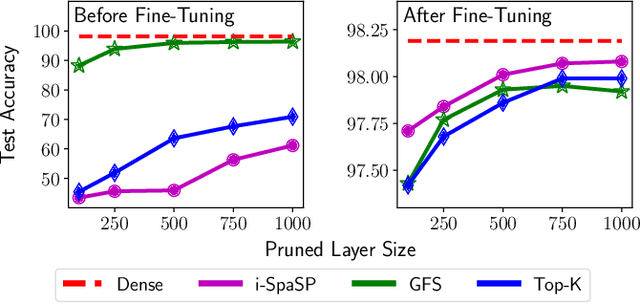
We propose a novel, structured pruning algorithm for neural networks -- the iterative, Sparse Structured Pruning algorithm, dubbed as i-SpaSP. Inspired by ideas from sparse signal recovery, i-SpaSP operates by iteratively identifying a larger set of important parameter groups (e.g., filters or neurons) within a network that contribute most to the residual between pruned and dense network output, then thresholding these groups based on a smaller, pre-defined pruning ratio. For both two-layer and multi-layer network architectures with ReLU activations, we show the error induced by pruning with i-SpaSP decays polynomially, where the degree of this polynomial becomes arbitrarily large based on the sparsity of the dense network's hidden representations. In our experiments, i-SpaSP is evaluated across a variety of datasets (i.e., MNIST and ImageNet) and architectures (i.e., feed forward networks, ResNet34, and MobileNetV2), where it is shown to discover high-performing sub-networks and improve upon the pruning efficiency of provable baseline methodologies by several orders of magnitude. Put simply, i-SpaSP is easy to implement with automatic differentiation, achieves strong empirical results, comes with theoretical convergence guarantees, and is efficient, thus distinguishing itself as one of the few computationally efficient, practical, and provable pruning algorithms.
On the Convergence of Shallow Neural Network Training with Randomly Masked Neurons
Dec 05, 2021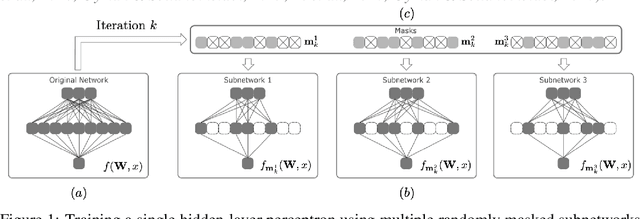
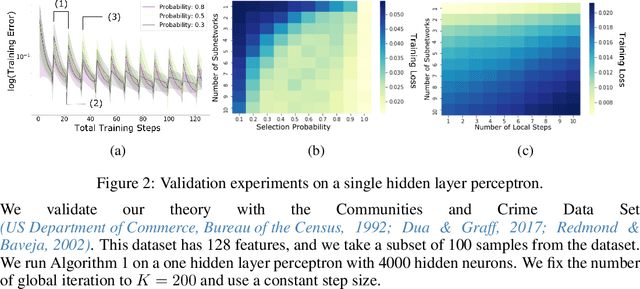
Given a dense shallow neural network, we focus on iteratively creating, training, and combining randomly selected subnetworks (surrogate functions), towards training the full model. By carefully analyzing $i)$ the subnetworks' neural tangent kernel, $ii)$ the surrogate functions' gradient, and $iii)$ how we sample and combine the surrogate functions, we prove linear convergence rate of the training error -- within an error region -- for an overparameterized single-hidden layer perceptron with ReLU activations for a regression task. Our result implies that, for fixed neuron selection probability, the error term decreases as we increase the number of surrogate models, and increases as we increase the number of local training steps for each selected subnetwork. The considered framework generalizes and provides new insights on dropout training, multi-sample dropout training, as well as Independent Subnet Training; for each case, we provide corresponding convergence results, as corollaries of our main theorem.
Convergence and Stability of the Stochastic Proximal Point Algorithm with Momentum
Dec 03, 2021

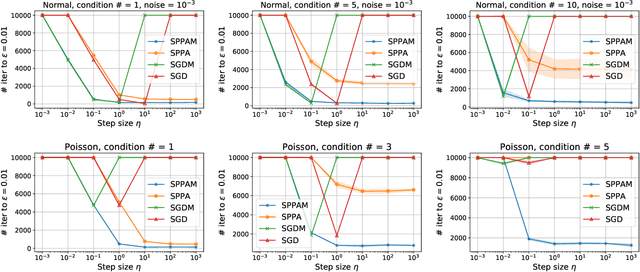
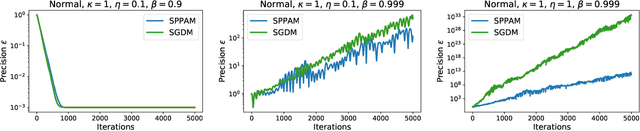
Stochastic gradient descent with momentum (SGDM) is the dominant algorithm in many optimization scenarios, including convex optimization instances and non-convex neural network training. Yet, in the stochastic setting, momentum interferes with gradient noise, often leading to specific step size and momentum choices in order to guarantee convergence, set aside acceleration. Proximal point methods, on the other hand, have gained much attention due to their numerical stability and elasticity against imperfect tuning. Their stochastic accelerated variants though have received limited attention: how momentum interacts with the stability of (stochastic) proximal point methods remains largely unstudied. To address this, we focus on the convergence and stability of the stochastic proximal point algorithm with momentum (SPPAM), and show that SPPAM allows a faster linear convergence rate compared to stochastic proximal point algorithm (SPPA) with a better contraction factor, under proper hyperparameter tuning. In terms of stability, we show that SPPAM depends on problem constants more favorably than SGDM, allowing a wider range of step size and momentum that lead to convergence.
Federated Multiple Label Hashing (FedMLH): Communication Efficient Federated Learning on Extreme Classification Tasks
Oct 23, 2021
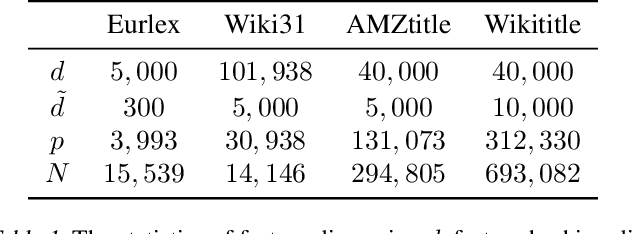
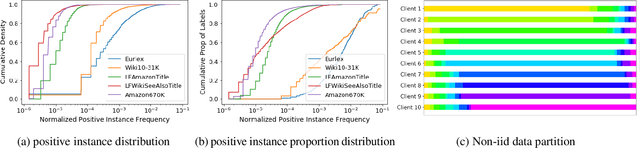
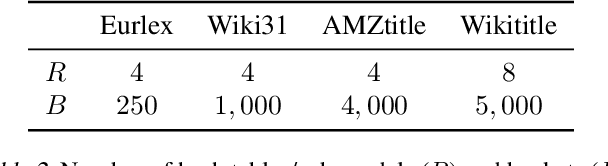
Federated learning enables many local devices to train a deep learning model jointly without sharing the local data. Currently, most of federated training schemes learns a global model by averaging the parameters of local models. However, most of these training schemes suffer from high communication cost resulted from transmitting full local model parameters. Moreover, directly averaging model parameters leads to a significant performance degradation, due to the class-imbalanced non-iid data on different devices. Especially for the real life federated learning tasks involving extreme classification, (1) communication becomes the main bottleneck since the model size increases proportionally to the number of output classes; (2) extreme classification (such as user recommendation) normally have extremely imbalanced classes and heterogeneous data on different devices. To overcome this problem, we propose federated multiple label hashing (FedMLH), which leverages label hashing to simultaneously reduce the model size (up to 3.40X decrease) with communication cost (up to 18.75X decrease) and achieves significant better accuracy (up to 35.5%} relative accuracy improvement) and faster convergence rate (up to 5.5X increase) for free on the federated extreme classification tasks compared to federated average algorithm.
Provably Efficient Lottery Ticket Discovery
Jul 31, 2021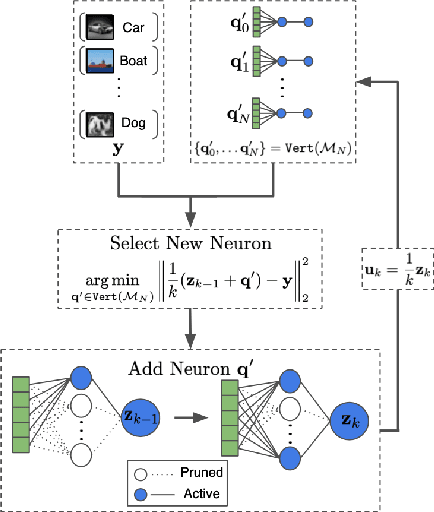
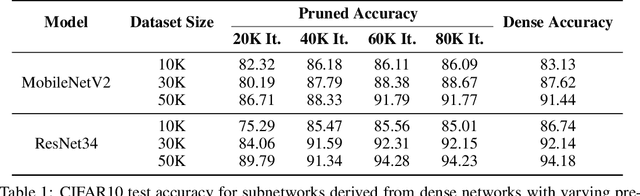
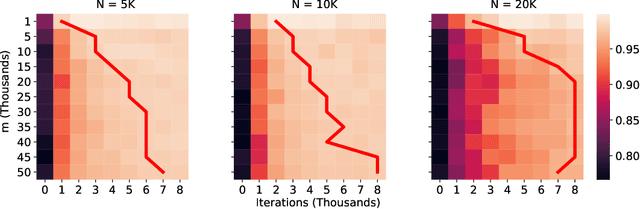
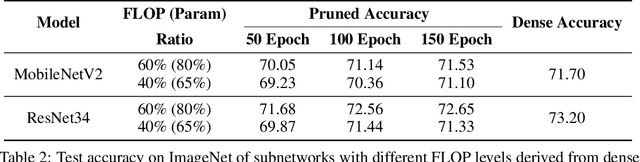
The lottery ticket hypothesis (LTH) claims that randomly-initialized, dense neural networks contain (sparse) subnetworks that, when trained an equal amount in isolation, can match the dense network's performance. Although LTH is useful for discovering efficient network architectures, its three-step process -- pre-training, pruning, and re-training -- is computationally expensive, as the dense model must be fully pre-trained. Luckily, "early-bird" tickets can be discovered within neural networks that are minimally pre-trained, allowing for the creation of efficient, LTH-inspired training procedures. Yet, no theoretical foundation of this phenomenon exists. We derive an analytical bound for the number of pre-training iterations that must be performed for a winning ticket to be discovered, thus providing a theoretical understanding of when and why such early-bird tickets exist. By adopting a greedy forward selection pruning strategy, we directly connect the pruned network's performance to the loss of the dense network from which it was derived, revealing a threshold in the number of pre-training iterations beyond which high-performing subnetworks are guaranteed to exist. We demonstrate the validity of our theoretical results across a variety of architectures and datasets, including multi-layer perceptrons (MLPs) trained on MNIST and several deep convolutional neural network (CNN) architectures trained on CIFAR10 and ImageNet.
REX: Revisiting Budgeted Training with an Improved Schedule
Jul 09, 2021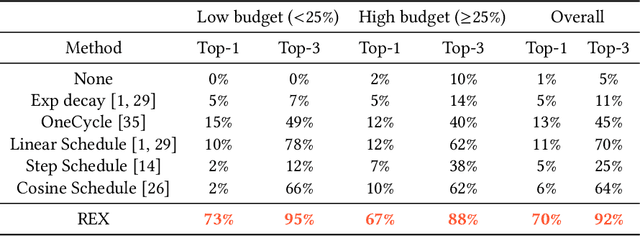

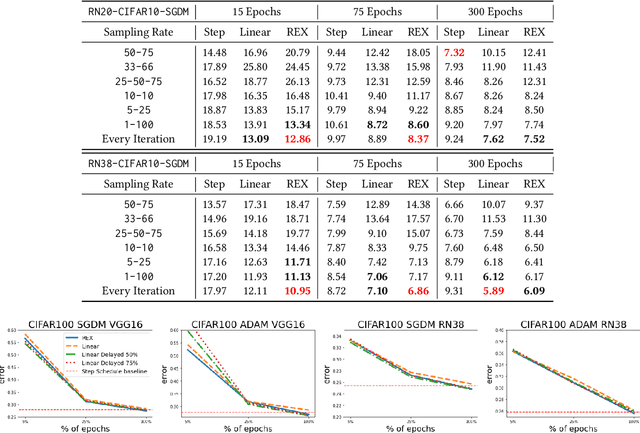
Deep learning practitioners often operate on a computational and monetary budget. Thus, it is critical to design optimization algorithms that perform well under any budget. The linear learning rate schedule is considered the best budget-aware schedule, as it outperforms most other schedules in the low budget regime. On the other hand, learning rate schedules -- such as the \texttt{30-60-90} step schedule -- are known to achieve high performance when the model can be trained for many epochs. Yet, it is often not known a priori whether one's budget will be large or small; thus, the optimal choice of learning rate schedule is made on a case-by-case basis. In this paper, we frame the learning rate schedule selection problem as a combination of $i)$ selecting a profile (i.e., the continuous function that models the learning rate schedule), and $ii)$ choosing a sampling rate (i.e., how frequently the learning rate is updated/sampled from this profile). We propose a novel profile and sampling rate combination called the Reflected Exponential (REX) schedule, which we evaluate across seven different experimental settings with both SGD and Adam optimizers. REX outperforms the linear schedule in the low budget regime, while matching or exceeding the performance of several state-of-the-art learning rate schedules (linear, step, exponential, cosine, step decay on plateau, and OneCycle) in both high and low budget regimes. Furthermore, REX requires no added computation, storage, or hyperparameters.
Momentum-inspired Low-Rank Coordinate Descent for Diagonally Constrained SDPs
Jul 03, 2021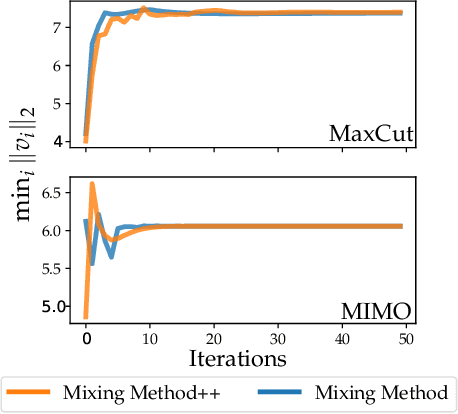
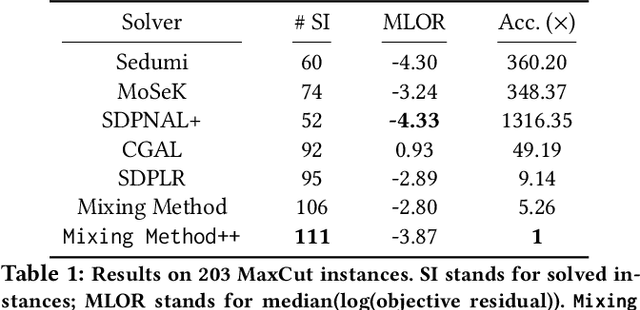
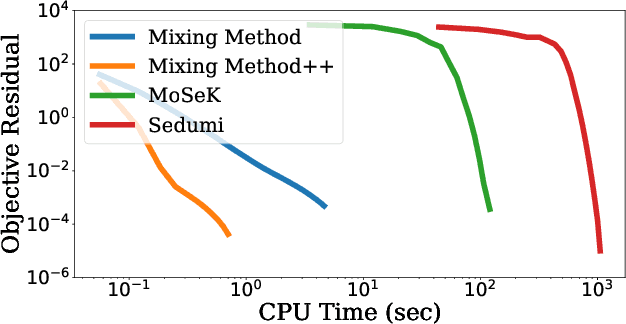

We present a novel, practical, and provable approach for solving diagonally constrained semi-definite programming (SDP) problems at scale using accelerated non-convex programming. Our algorithm non-trivially combines acceleration motions from convex optimization with coordinate power iteration and matrix factorization techniques. The algorithm is extremely simple to implement, and adds only a single extra hyperparameter -- momentum. We prove that our method admits local linear convergence in the neighborhood of the optimum and always converges to a first-order critical point. Experimentally, we showcase the merits of our method on three major application domains: MaxCut, MaxSAT, and MIMO signal detection. In all cases, our methodology provides significant speedups over non-convex and convex SDP solvers -- 5X faster than state-of-the-art non-convex solvers, and 9 to 10^3 X faster than convex SDP solvers -- with comparable or improved solution quality.
ResIST: Layer-Wise Decomposition of ResNets for Distributed Training
Jul 02, 2021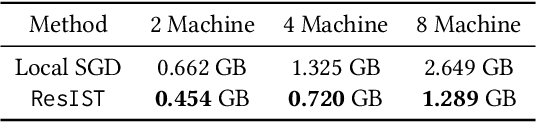
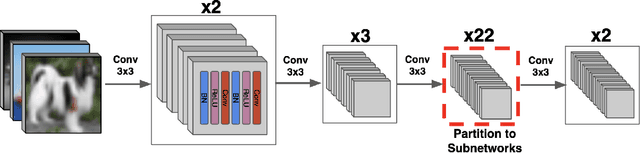
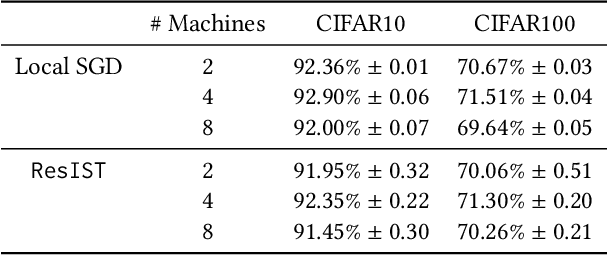
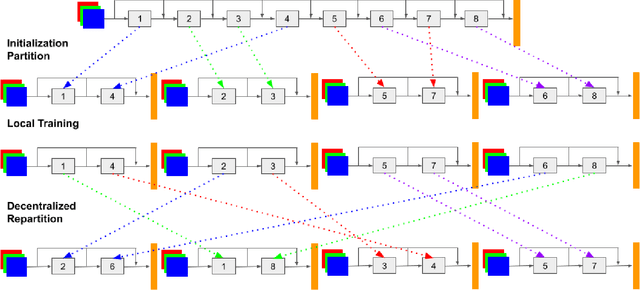
We propose {\rm \texttt{ResIST}}, a novel distributed training protocol for Residual Networks (ResNets). {\rm \texttt{ResIST}} randomly decomposes a global ResNet into several shallow sub-ResNets that are trained independently in a distributed manner for several local iterations, before having their updates synchronized and aggregated into the global model. In the next round, new sub-ResNets are randomly generated and the process repeats. By construction, per iteration, {\rm \texttt{ResIST}} communicates only a small portion of network parameters to each machine and never uses the full model during training. Thus, {\rm \texttt{ResIST}} reduces the communication, memory, and time requirements of ResNet training to only a fraction of the requirements of previous methods. In comparison to common protocols like data-parallel training and data-parallel training with local SGD, {\rm \texttt{ResIST}} yields a decrease in wall-clock training time, while being competitive with respect to model performance.
Mitigating deep double descent by concatenating inputs
Jul 02, 2021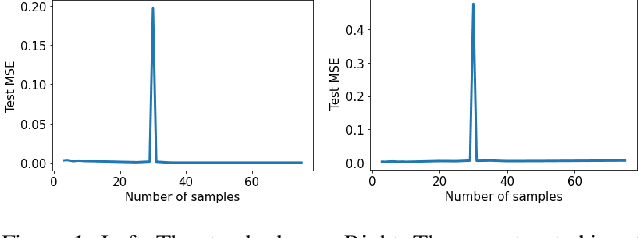
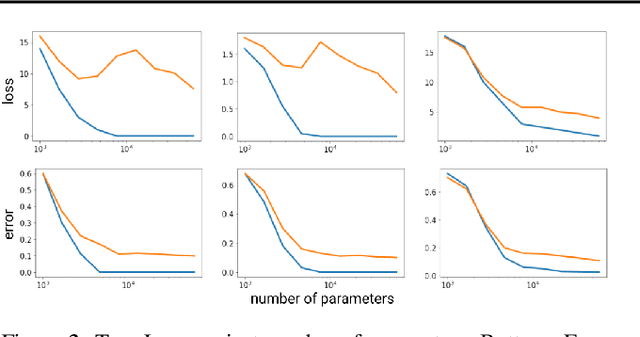
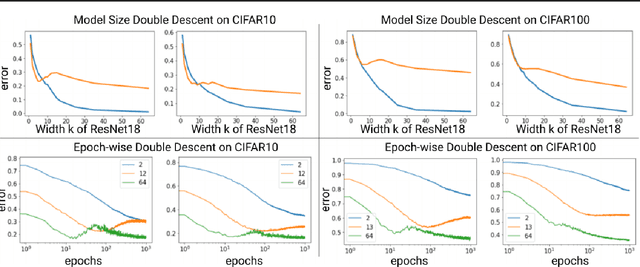
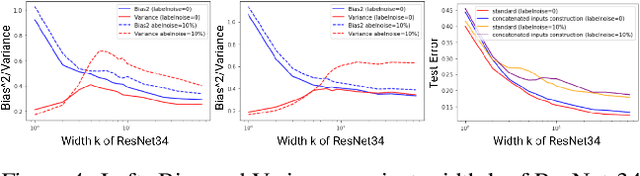
The double descent curve is one of the most intriguing properties of deep neural networks. It contrasts the classical bias-variance curve with the behavior of modern neural networks, occurring where the number of samples nears the number of parameters. In this work, we explore the connection between the double descent phenomena and the number of samples in the deep neural network setting. In particular, we propose a construction which augments the existing dataset by artificially increasing the number of samples. This construction empirically mitigates the double descent curve in this setting. We reproduce existing work on deep double descent, and observe a smooth descent into the overparameterized region for our construction. This occurs both with respect to the model size, and with respect to the number epochs.
Fast quantum state reconstruction via accelerated non-convex programming
Apr 30, 2021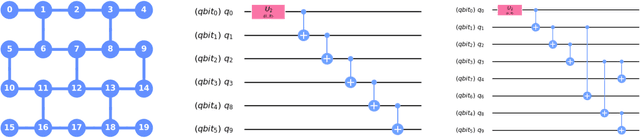

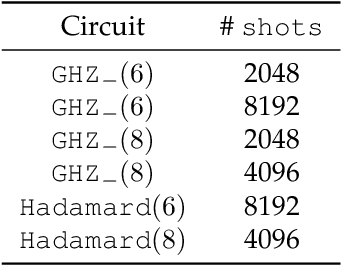
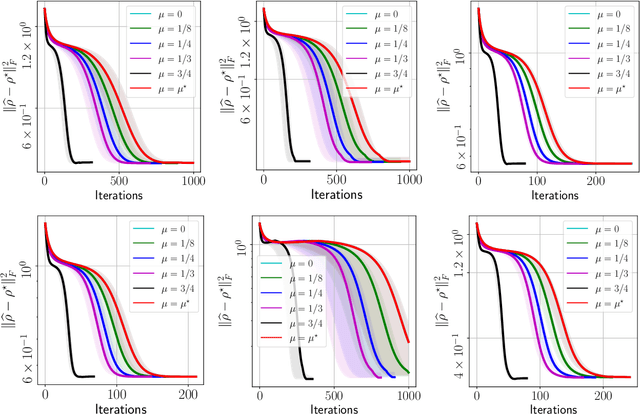
We propose a new quantum state reconstruction method that combines ideas from compressed sensing, non-convex optimization, and acceleration methods. The algorithm, called Momentum-Inspired Factored Gradient Descent (\texttt{MiFGD}), extends the applicability of quantum tomography for larger systems. Despite being a non-convex method, \texttt{MiFGD} converges \emph{provably} to the true density matrix at a linear rate, in the absence of experimental and statistical noise, and under common assumptions. With this manuscript, we present the method, prove its convergence property and provide Frobenius norm bound guarantees with respect to the true density matrix. From a practical point of view, we benchmark the algorithm performance with respect to other existing methods, in both synthetic and real experiments performed on an IBM's quantum processing unit. We find that the proposed algorithm performs orders of magnitude faster than state of the art approaches, with the same or better accuracy. In both synthetic and real experiments, we observed accurate and robust reconstruction, despite experimental and statistical noise in the tomographic data. Finally, we provide a ready-to-use code for state tomography of multi-qubit systems.