 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDelay-aware Backpressure Routing Using Graph Neural Networks
Nov 19, 2022We propose a throughput-optimal biased backpressure (BP) algorithm for routing, where the bias is learned through a graph neural network that seeks to minimize end-to-end delay. Classical BP routing provides a simple yet powerful distributed solution for resource allocation in wireless multi-hop networks but has poor delay performance. A low-cost approach to improve this delay performance is to favor shorter paths by incorporating pre-defined biases in the BP computation, such as a bias based on the shortest path (hop) distance to the destination. In this work, we improve upon the widely-used metric of hop distance (and its variants) for the shortest path bias by introducing a bias based on the link duty cycle, which we predict using a graph convolutional neural network. Numerical results show that our approach can improve the delay performance compared to classical BP and existing BP alternatives based on pre-defined bias while being adaptive to interference density. In terms of complexity, our distributed implementation only introduces a one-time overhead (linear in the number of devices in the network) compared to classical BP, and a constant overhead compared to the lowest-complexity existing bias-based BP algorithms.
Distributed Link Sparsification for Scalable Scheduling Using Graph Neural Networks
Mar 27, 2022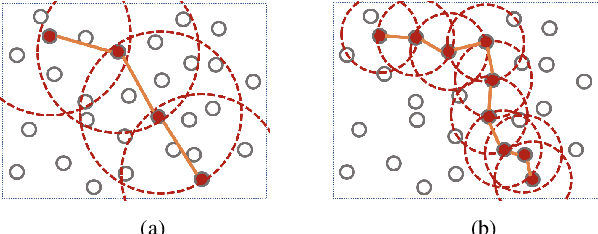
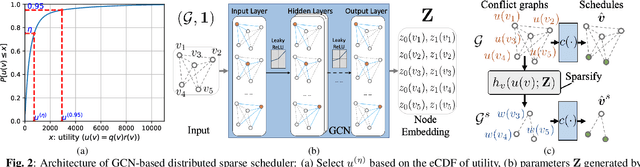
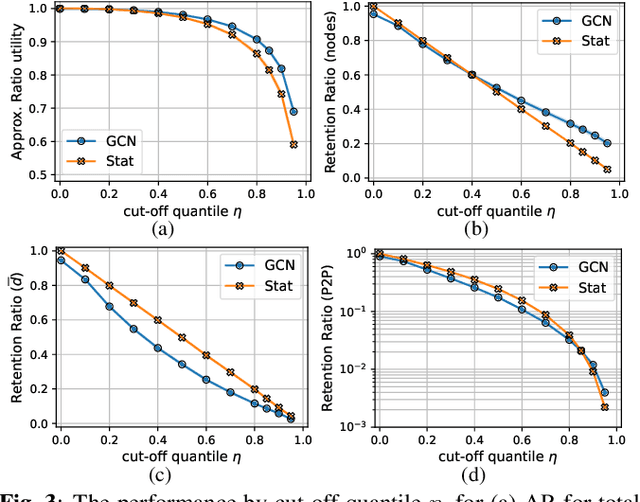
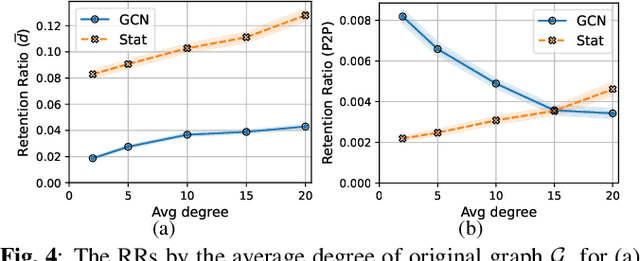
Distributed scheduling algorithms for throughput or utility maximization in dense wireless multi-hop networks can have overwhelmingly high overhead, causing increased congestion, energy consumption, radio footprint, and security vulnerability. For wireless networks with dense connectivity, we propose a distributed scheme for link sparsification with graph convolutional networks (GCNs), which can reduce the scheduling overhead while keeping most of the network capacity. In a nutshell, a trainable GCN module generates node embeddings as topology-aware and reusable parameters for a local decision mechanism, based on which a link can withdraw itself from the scheduling contention if it is not likely to win. In medium-sized wireless networks, our proposed sparse scheduler beats classical threshold-based sparsification policies by retaining almost $70\%$ of the total capacity achieved by a distributed greedy max-weight scheduler with $0.4\%$ of the point-to-point message complexity and $2.6\%$ of the average number of interfering neighbors per link.
Power Allocation for Wireless Federated Learning using Graph Neural Networks
Nov 15, 2021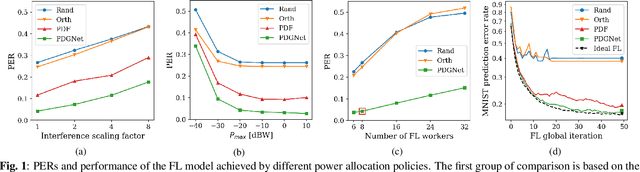
We propose a data-driven approach for power allocation in the context of federated learning (FL) over interference-limited wireless networks. The power policy is designed to maximize the transmitted information during the FL process under communication constraints, with the ultimate objective of improving the accuracy and efficiency of the global FL model being trained. The proposed power allocation policy is parameterized using a graph convolutional network and the associated constrained optimization problem is solved through a primal-dual algorithm. Numerical experiments show that the proposed method outperforms three baseline methods in both transmission success rate and FL global performance.
Delay-Oriented Distributed Scheduling Using Graph Neural Networks
Nov 13, 2021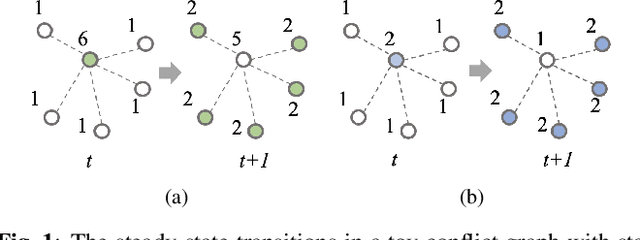
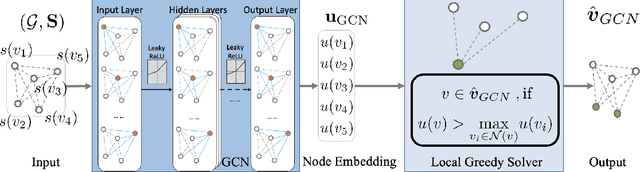
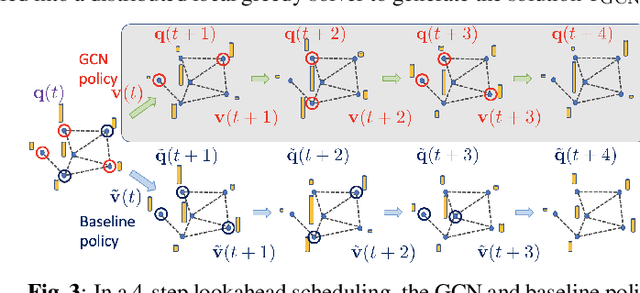
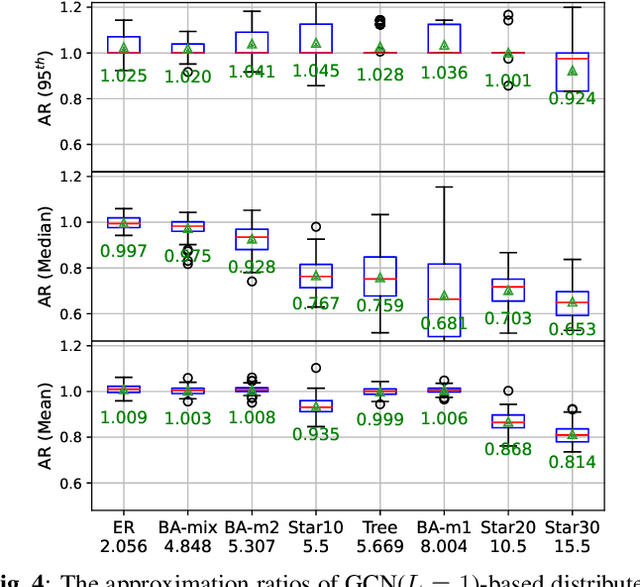
In wireless multi-hop networks, delay is an important metric for many applications. However, the max-weight scheduling algorithms in the literature typically focus on instantaneous optimality, in which the schedule is selected by solving a maximum weighted independent set (MWIS) problem on the interference graph at each time slot. These myopic policies perform poorly in delay-oriented scheduling, in which the dependency between the current backlogs of the network and the schedule of the previous time slot needs to be considered. To address this issue, we propose a delay-oriented distributed scheduler based on graph convolutional networks (GCNs). In a nutshell, a trainable GCN module generates node embeddings that capture the network topology as well as multi-step lookahead backlogs, before calling a distributed greedy MWIS solver. In small- to medium-sized wireless networks with heterogeneous transmit power, where a few central links have many interfering neighbors, our proposed distributed scheduler can outperform the myopic schedulers based on greedy and instantaneously optimal MWIS solvers, with good generalizability across graph models and minimal increase in communication complexity.
ML-aided power allocation for Tactical MIMO
Sep 14, 2021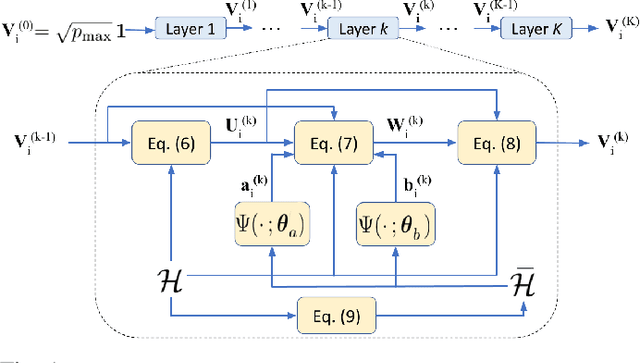
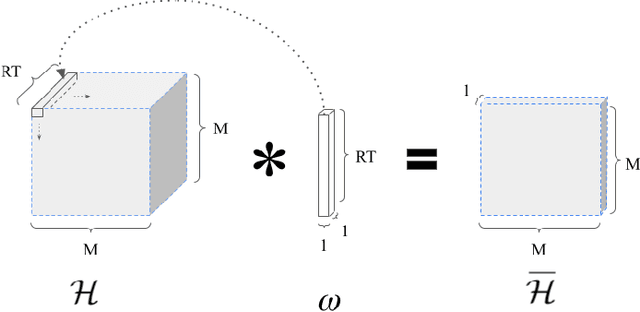
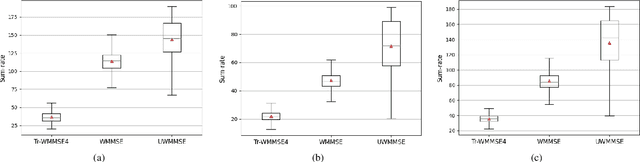
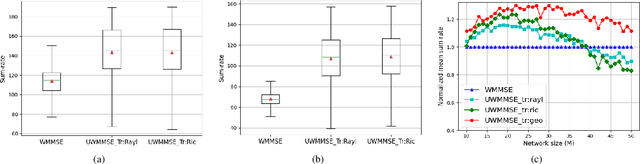
We study the problem of optimal power allocation in single-hop multi-antenna ad-hoc wireless networks. A standard technique to solve this problem involves optimizing a tri-convex function under power constraints using a block-coordinate-descent (BCD) based iterative algorithm. This approach, termed WMMSE, tends to be computationally complex and time consuming. Several learning-based approaches have been proposed to speed up the power allocation process. A recent work, UWMMSE, learns an affine transformation of a WMMSE parameter in an unfolded structure to accelerate convergence. In spite of achieving promising results, its application is limited to single-antenna wireless networks. In this work, we present a UWMMSE framework for power allocation in (multiple-input multiple-output) MIMO interference networks. Through an empirical study, we illustrate the superiority of our approach in comparison to WMMSE and also analyze its robustness to changes in channel conditions and network size.
Link Scheduling using Graph Neural Networks
Sep 12, 2021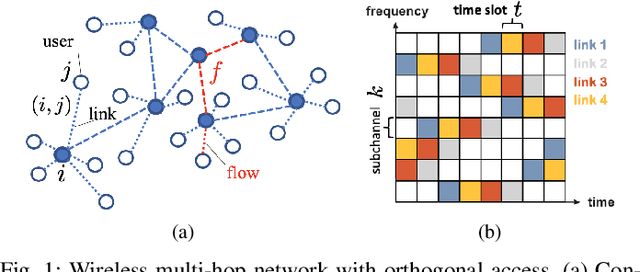
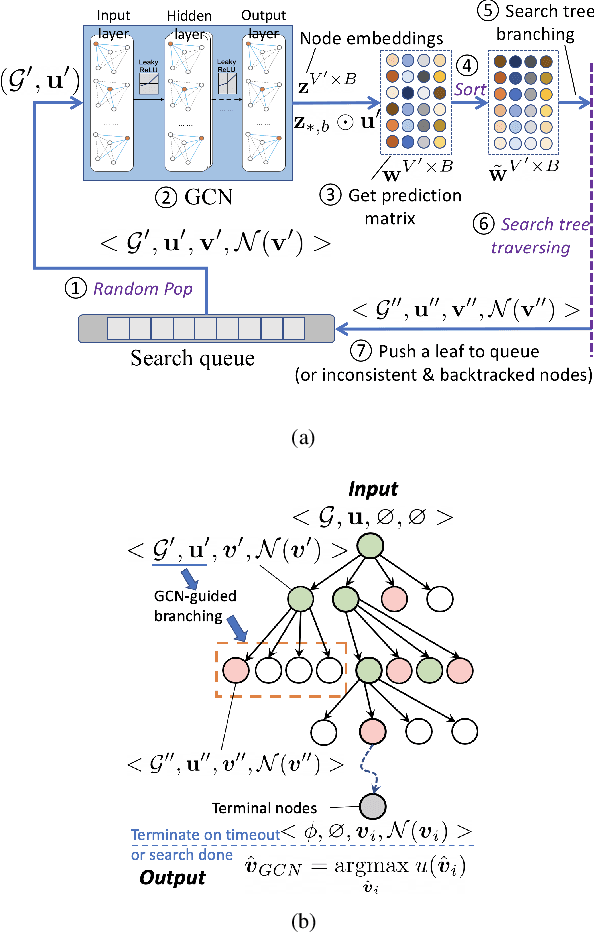
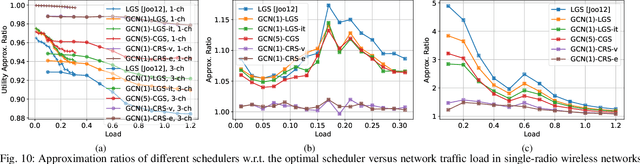
Efficient scheduling of transmissions is a key problem in wireless networks. The main challenge stems from the fact that optimal link scheduling involves solving a maximum weighted independent set (MWIS) problem, which is known to be NP-hard. For practical link scheduling schemes, centralized and distributed greedy heuristics are commonly used to approximate the solution to the MWIS problem. However, these greedy schemes mostly ignore important topological information of the wireless network. To overcome this limitation, we propose fast heuristics based on graph convolutional networks (GCNs) that can be implemented in centralized and distributed manners. Our centralized MWIS solver is based on tree search guided by a trainable GCN module and 1-step rollout. In our distributed MWIS solver, a trainable GCN module learns topology-aware node embeddings that are combined with the network weights before calling a distributed greedy solver. Test results on medium-sized wireless networks show that a GCN-based centralized MWIS solver can reach a near-optimal solution quickly. Moreover, we demonstrate that a shallow GCN-based distributed MWIS scheduler can reduce by nearly half the suboptimality gap of the distributed greedy solver with minimal increase in complexity. The proposed scheduling solutions also exhibit good generalizability across graph and weight distributions.
Free Energy Node Embedding via Generalized Skip-gram with Negative Sampling
May 19, 2021A widely established set of unsupervised node embedding methods can be interpreted as consisting of two distinctive steps: i) the definition of a similarity matrix based on the graph of interest followed by ii) an explicit or implicit factorization of such matrix. Inspired by this viewpoint, we propose improvements in both steps of the framework. On the one hand, we propose to encode node similarities based on the free energy distance, which interpolates between the shortest path and the commute time distances, thus, providing an additional degree of flexibility. On the other hand, we propose a matrix factorization method based on a loss function that generalizes that of the skip-gram model with negative sampling to arbitrary similarity matrices. Compared with factorizations based on the widely used $\ell_2$ loss, the proposed method can better preserve node pairs associated with higher similarity scores. Moreover, it can be easily implemented using advanced automatic differentiation toolkits and computed efficiently by leveraging GPU resources. Node clustering, node classification, and link prediction experiments on real-world datasets demonstrate the effectiveness of incorporating free-energy-based similarities as well as the proposed matrix factorization compared with state-of-the-art alternatives.
Distributed Scheduling using Graph Neural Networks
Nov 18, 2020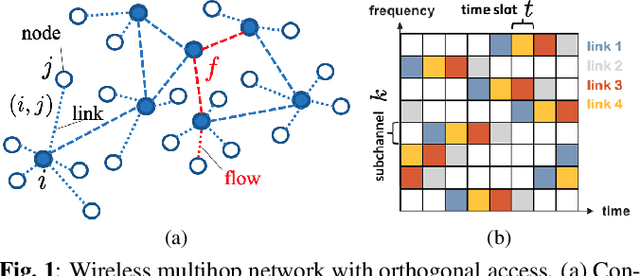
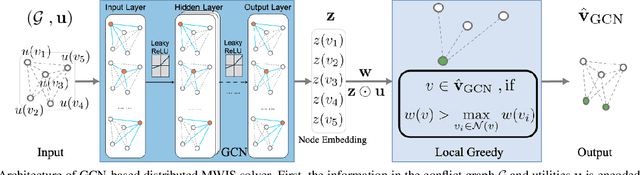
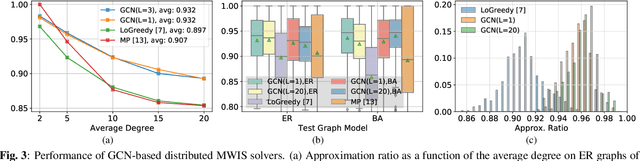
A fundamental problem in the design of wireless networks is to efficiently schedule transmission in a distributed manner. The main challenge stems from the fact that optimal link scheduling involves solving a maximum weighted independent set (MWIS) problem, which is NP-hard. For practical link scheduling schemes, distributed greedy approaches are commonly used to approximate the solution of the MWIS problem. However, these greedy schemes mostly ignore important topological information of the wireless networks. To overcome this limitation, we propose a distributed MWIS solver based on graph convolutional networks (GCNs). In a nutshell, a trainable GCN module learns topology-aware node embeddings that are combined with the network weights before calling a greedy solver. In small- to middle-sized wireless networks with tens of links, even a shallow GCN-based MWIS scheduler can leverage the topological information of the graph to reduce in half the suboptimality gap of the distributed greedy solver with good generalizability across graphs and minimal increase in complexity.
Adaptive Contention Window Design using Deep Q-learning
Nov 18, 2020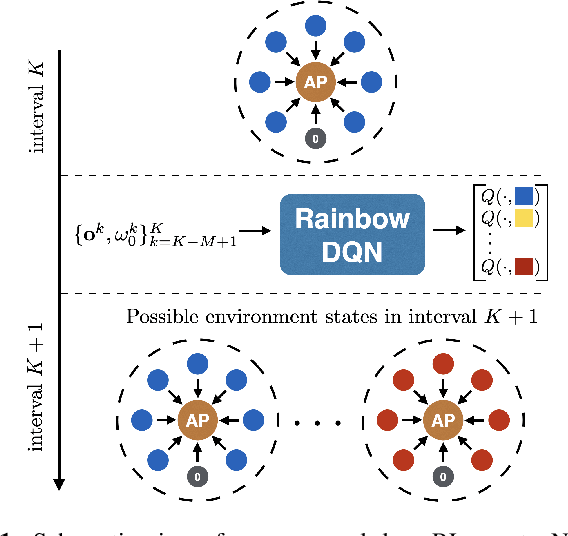
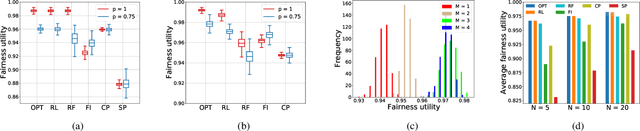
We study the problem of adaptive contention window (CW) design for random-access wireless networks. More precisely, our goal is to design an intelligent node that can dynamically adapt its minimum CW (MCW) parameter to maximize a network-level utility knowing neither the MCWs of other nodes nor how these change over time. To achieve this goal, we adopt a reinforcement learning (RL) framework where we circumvent the lack of system knowledge with local channel observations and we reward actions that lead to high utilities. To efficiently learn these preferred actions, we follow a deep Q-learning approach, where the Q-value function is parametrized using a multi-layer perception. In particular, we implement a rainbow agent, which incorporates several empirical improvements over the basic deep Q-network. Numerical experiments based on the NS3 simulator reveal that the proposed RL agent performs close to optimal and markedly improves upon existing learning and non-learning based alternatives.
Efficient power allocation using graph neural networks and deep algorithm unfolding
Nov 18, 2020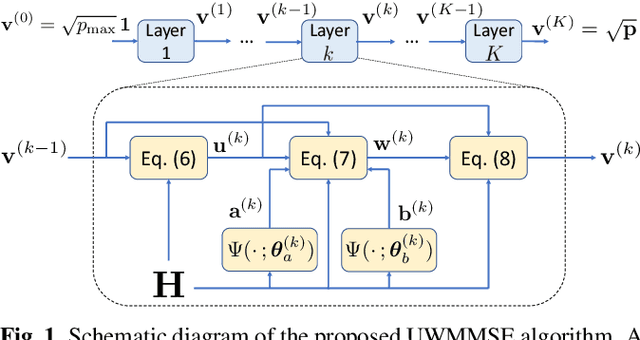
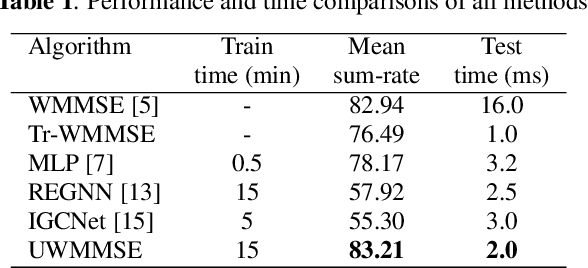
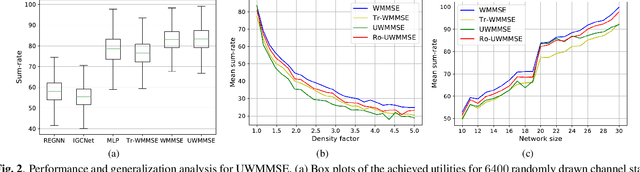
We study the problem of optimal power allocation in a single-hop ad hoc wireless network. In solving this problem, we propose a hybrid neural architecture inspired by the algorithmic unfolding of the iterative weighted minimum mean squared error (WMMSE) method, that we denote as unfolded WMMSE (UWMMSE). The learnable weights within UWMMSE are parameterized using graph neural networks (GNNs), where the time-varying underlying graphs are given by the fading interference coefficients in the wireless network. These GNNs are trained through a gradient descent approach based on multiple instances of the power allocation problem. Once trained, UWMMSE achieves performance comparable to that of WMMSE while significantly reducing the computational complexity. This phenomenon is illustrated through numerical experiments along with the robustness and generalization to wireless networks of different densities and sizes.