 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBig Bird: Transformers for Longer Sequences
Jul 28, 2020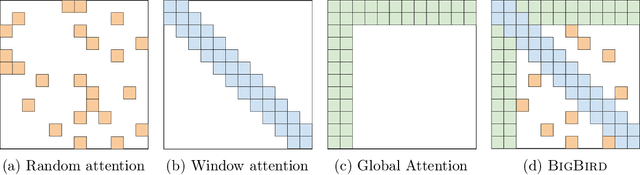
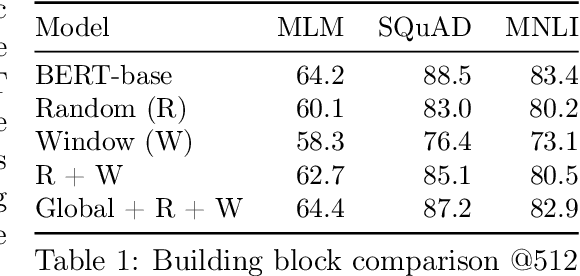

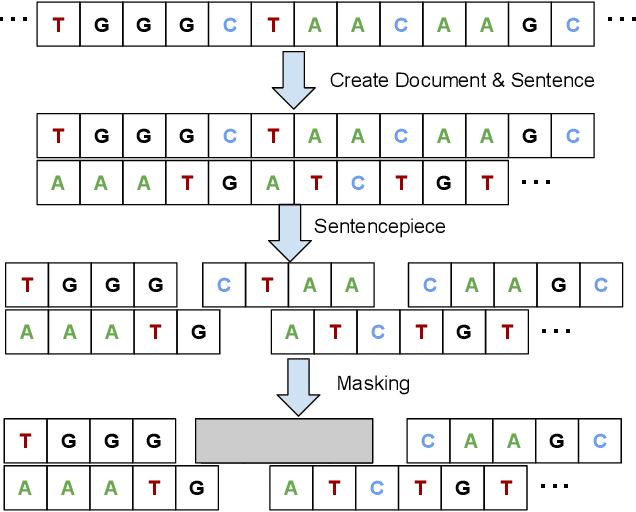
Transformers-based models, such as BERT, have been one of the most successful deep learning models for NLP. Unfortunately, one of their core limitations is the quadratic dependency (mainly in terms of memory) on the sequence length due to their full attention mechanism. To remedy this, we propose, BigBird, a sparse attention mechanism that reduces this quadratic dependency to linear. We show that BigBird is a universal approximator of sequence functions and is Turing complete, thereby preserving these properties of the quadratic, full attention model. Along the way, our theoretical analysis reveals some of the benefits of having $O(1)$ global tokens (such as CLS), that attend to the entire sequence as part of the sparse attention mechanism. The proposed sparse attention can handle sequences of length up to 8x of what was previously possible using similar hardware. As a consequence of the capability to handle longer context, BigBird drastically improves performance on various NLP tasks such as question answering and summarization. We also propose novel applications to genomics data.
Latent Bandits Revisited
Jun 15, 2020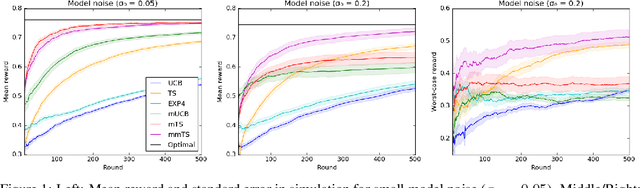
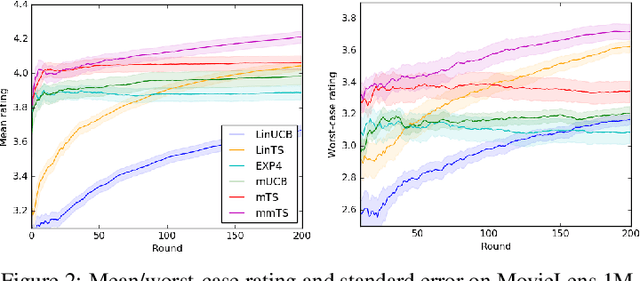
A latent bandit problem is one in which the learning agent knows the arm reward distributions conditioned on an unknown discrete latent state. The primary goal of the agent is to identify the latent state, after which it can act optimally. This setting is a natural midpoint between online and offline learning---complex models can be learned offline with the agent identifying latent state online---of practical relevance in, say, recommender systems. In this work, we propose general algorithms for this setting, based on both upper confidence bounds (UCBs) and Thompson sampling. Our methods are contextual and aware of model uncertainty and misspecification. We provide a unified theoretical analysis of our algorithms, which have lower regret than classic bandit policies when the number of latent states is smaller than actions. A comprehensive empirical study showcases the advantages of our approach.
Piecewise-Stationary Off-Policy Optimization
Jun 15, 2020
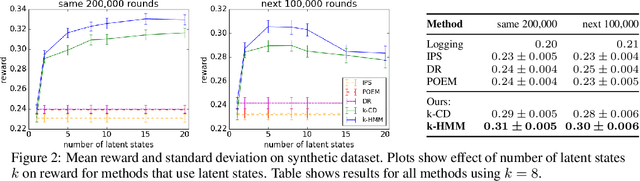
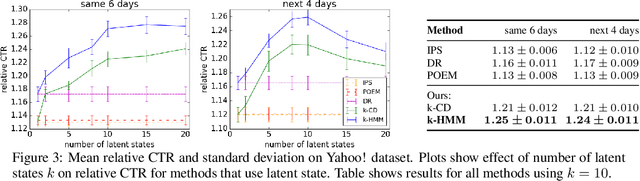
Off-policy learning is a framework for evaluating and optimizing policies without deploying them, from data collected by another policy. Real-world environments are typically non-stationary and the offline learned policies should adapt to these changes. To address this challenge, we study the novel problem of off-policy optimization in piecewise-stationary contextual bandits. Our proposed solution has two phases. In the offline learning phase, we partition logged data into categorical latent states and learn a near-optimal sub-policy for each state. In the online deployment phase, we adaptively switch between the learned sub-policies based on their performance. This approach is practical and analyzable, and we provide guarantees on both the quality of off-policy optimization and the regret during online deployment. To show the effectiveness of our approach, we compare it to state-of-the-art baselines on both synthetic and real-world datasets. Our approach outperforms methods that act only on observed context.
Anchor & Transform: Learning Sparse Representations of Discrete Objects
Mar 18, 2020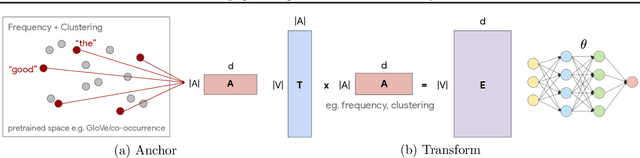
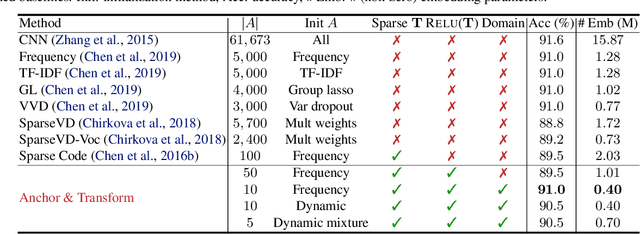

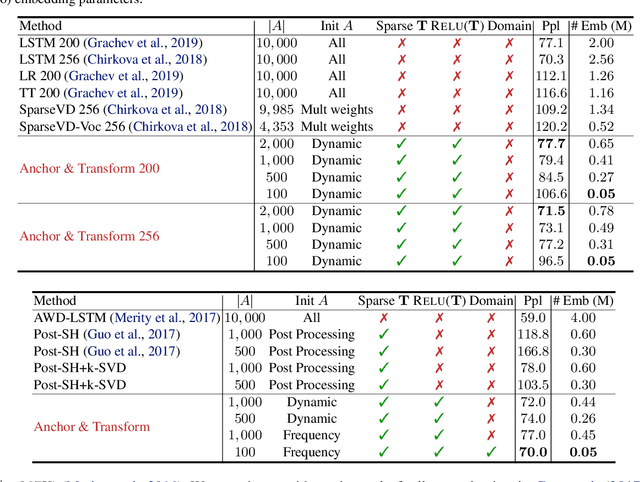
Learning continuous representations of discrete objects such as text, users, and URLs lies at the heart of many applications including language and user modeling. When using discrete objects as input to neural networks, we often ignore the underlying structures (e.g. natural groupings and similarities) and embed the objects independently into individual vectors. As a result, existing methods do not scale to large vocabulary sizes. In this paper, we design a Bayesian nonparametric prior for embeddings that encourages sparsity and leverages natural groupings among objects. We derive an approximate inference algorithm based on Small Variance Asymptotics which yields a simple and natural algorithm for learning a small set of anchor embeddings and a sparse transformation matrix. We call our method Anchor & Transform (ANT) as the embeddings of discrete objects are a sparse linear combination of the anchors, weighted according to the transformation matrix. ANT is scalable, flexible, end-to-end trainable, and allows the user to incorporate domain knowledge about object relationships. On text classification and language modeling benchmarks, ANT demonstrates stronger performance with fewer parameters as compared to existing compression baselines.
State Space LSTM Models with Particle MCMC Inference
Nov 30, 2017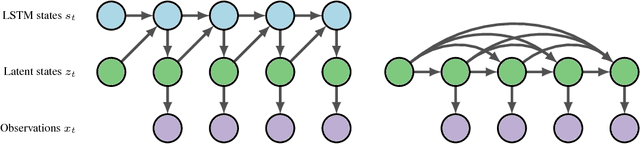
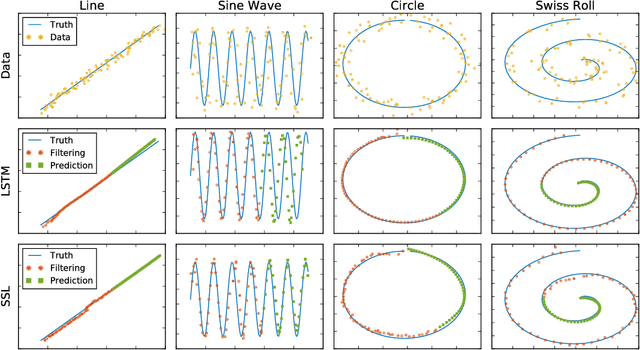
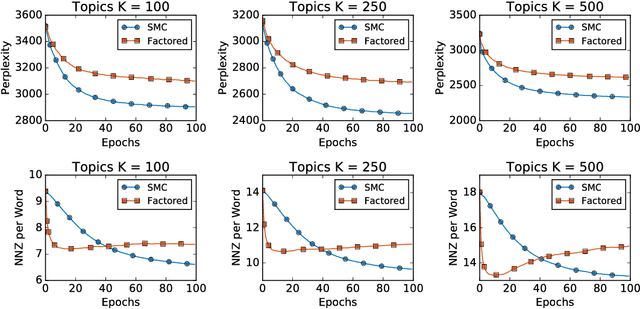
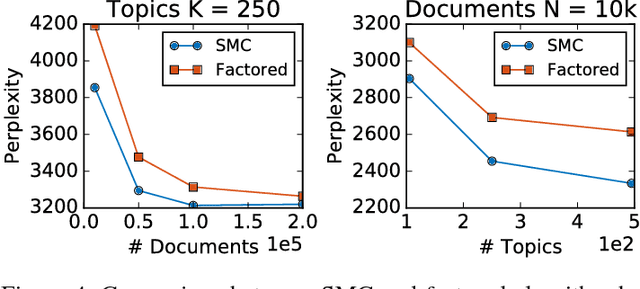
Long Short-Term Memory (LSTM) is one of the most powerful sequence models. Despite the strong performance, however, it lacks the nice interpretability as in state space models. In this paper, we present a way to combine the best of both worlds by introducing State Space LSTM (SSL) models that generalizes the earlier work \cite{zaheer2017latent} of combining topic models with LSTM. However, unlike \cite{zaheer2017latent}, we do not make any factorization assumptions in our inference algorithm. We present an efficient sampler based on sequential Monte Carlo (SMC) method that draws from the joint posterior directly. Experimental results confirms the superiority and stability of this SMC inference algorithm on a variety of domains.
Explaining reviews and ratings with PACO: Poisson Additive Co-Clustering
Dec 06, 2015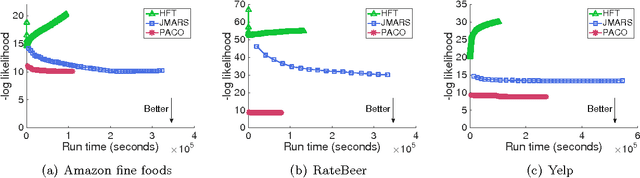
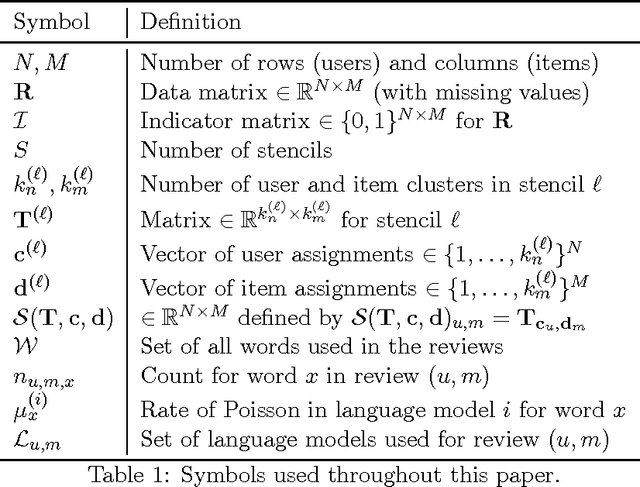
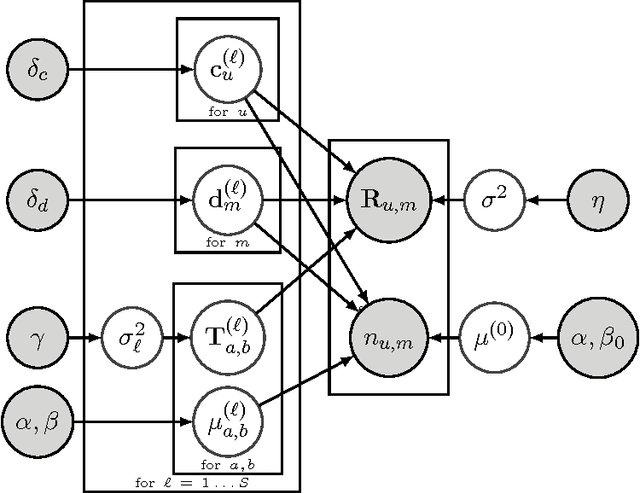
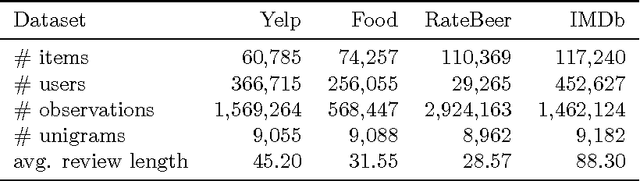
Understanding a user's motivations provides valuable information beyond the ability to recommend items. Quite often this can be accomplished by perusing both ratings and review texts, since it is the latter where the reasoning for specific preferences is explicitly expressed. Unfortunately matrix factorization approaches to recommendation result in large, complex models that are difficult to interpret and give recommendations that are hard to clearly explain to users. In contrast, in this paper, we attack this problem through succinct additive co-clustering. We devise a novel Bayesian technique for summing co-clusterings of Poisson distributions. With this novel technique we propose a new Bayesian model for joint collaborative filtering of ratings and text reviews through a sum of simple co-clusterings. The simple structure of our model yields easily interpretable recommendations. Even with a simple, succinct structure, our model outperforms competitors in terms of predicting ratings with reviews.
High Performance Latent Variable Models
Nov 11, 2015
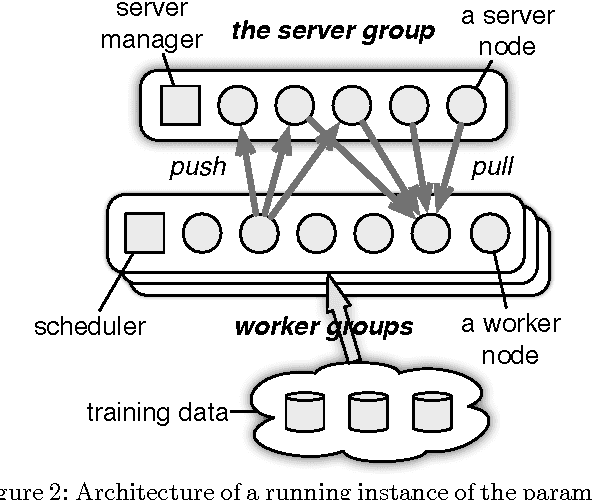
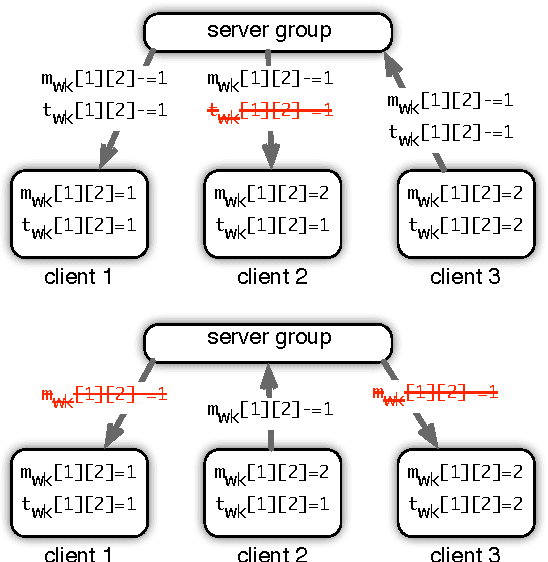
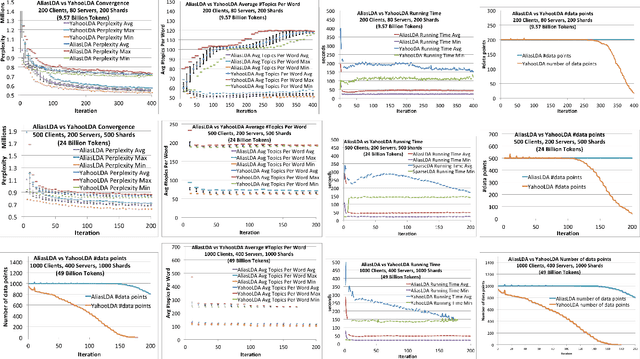
Latent variable models have accumulated a considerable amount of interest from the industry and academia for their versatility in a wide range of applications. A large amount of effort has been made to develop systems that is able to extend the systems to a large scale, in the hope to make use of them on industry scale data. In this paper, we describe a system that operates at a scale orders of magnitude higher than previous works, and an order of magnitude faster than state-of-the-art system at the same scale, at the same time showing more robustness and more accurate results. Our system uses a number of advances in distributed inference: high performance in synchronization of sufficient statistics with relaxed consistency model; fast sampling, using the Metropolis-Hastings-Walker method to overcome dense generative models; statistical modeling, moving beyond Latent Dirichlet Allocation (LDA) to Pitman-Yor distributions (PDP) and Hierarchical Dirichlet Process (HDP) models; sophisticated parameter projection schemes, to resolve the conflicts within the constraint between parameters arising from the relaxed consistency model. This work significantly extends the domain of applicability of what is commonly known as the Parameter Server. We obtain results with up to hundreds billion oftokens, thousands of topics, and a vocabulary of a few million token-types, using up to 60,000 processor cores operating on a production cluster of a large Internet company. This demonstrates the feasibility to scale to problems orders of magnitude larger than any previously published work.
ACCAMS: Additive Co-Clustering to Approximate Matrices Succinctly
Dec 31, 2014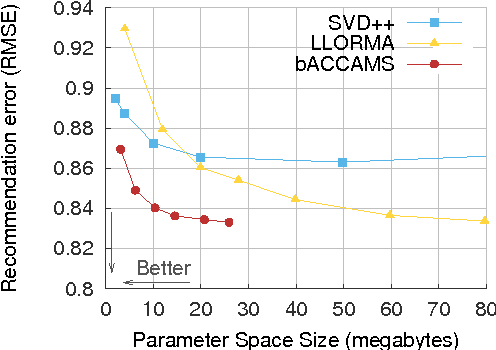
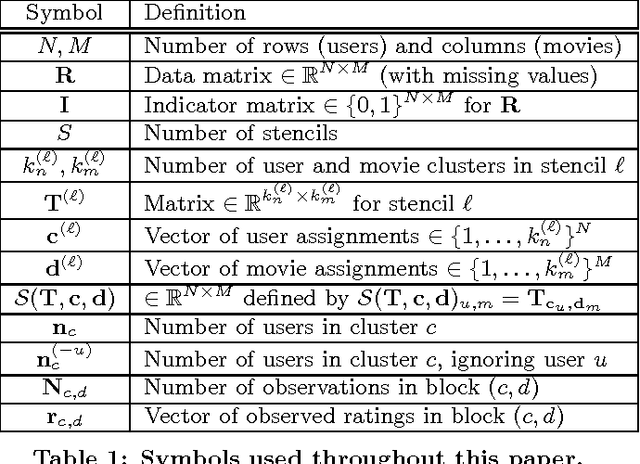
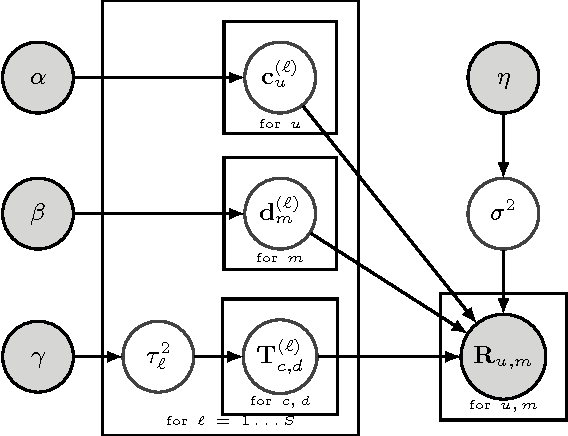
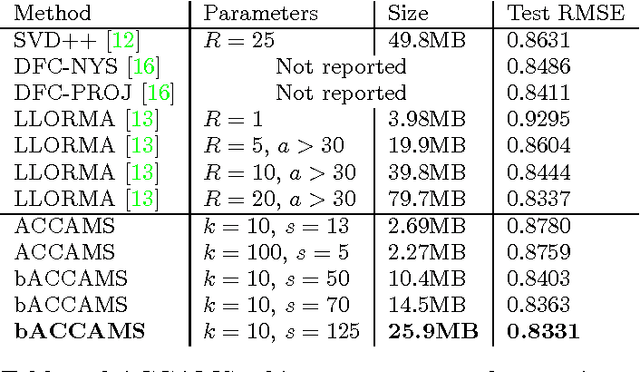
Matrix completion and approximation are popular tools to capture a user's preferences for recommendation and to approximate missing data. Instead of using low-rank factorization we take a drastically different approach, based on the simple insight that an additive model of co-clusterings allows one to approximate matrices efficiently. This allows us to build a concise model that, per bit of model learned, significantly beats all factorization approaches to matrix approximation. Even more surprisingly, we find that summing over small co-clusterings is more effective in modeling matrices than classic co-clustering, which uses just one large partitioning of the matrix. Following Occam's razor principle suggests that the simple structure induced by our model better captures the latent preferences and decision making processes present in the real world than classic co-clustering or matrix factorization. We provide an iterative minimization algorithm, a collapsed Gibbs sampler, theoretical guarantees for matrix approximation, and excellent empirical evidence for the efficacy of our approach. We achieve state-of-the-art results on the Netflix problem with a fraction of the model complexity.
Timeline: A Dynamic Hierarchical Dirichlet Process Model for Recovering Birth/Death and Evolution of Topics in Text Stream
Mar 15, 2012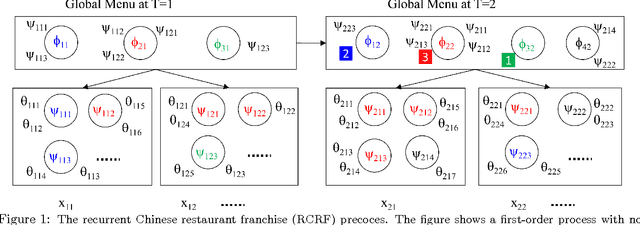
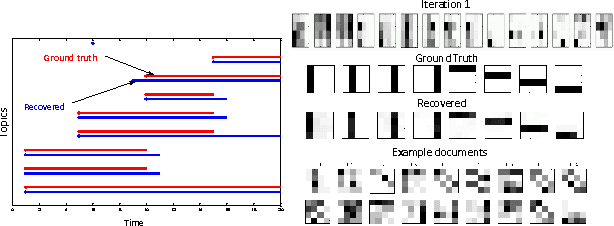
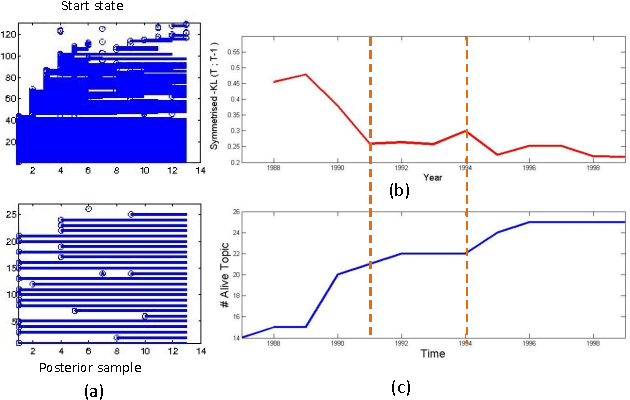
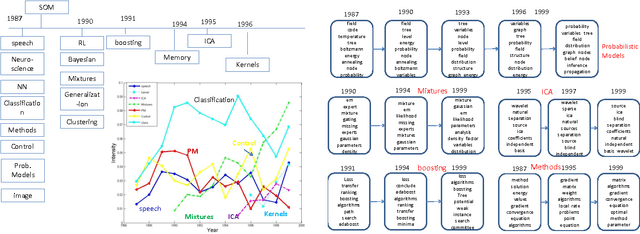
Topic models have proven to be a useful tool for discovering latent structures in document collections. However, most document collections often come as temporal streams and thus several aspects of the latent structure such as the number of topics, the topics' distribution and popularity are time-evolving. Several models exist that model the evolution of some but not all of the above aspects. In this paper we introduce infinite dynamic topic models, iDTM, that can accommodate the evolution of all the aforementioned aspects. Our model assumes that documents are organized into epochs, where the documents within each epoch are exchangeable but the order between the documents is maintained across epochs. iDTM allows for unbounded number of topics: topics can die or be born at any epoch, and the representation of each topic can evolve according to a Markovian dynamics. We use iDTM to analyze the birth and evolution of topics in the NIPS community and evaluated the efficacy of our model on both simulated and real datasets with favorable outcome.
Estimating time-varying networks
Oct 20, 2010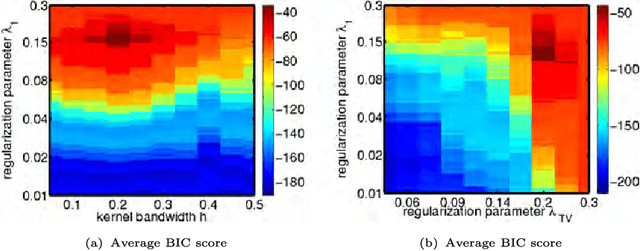
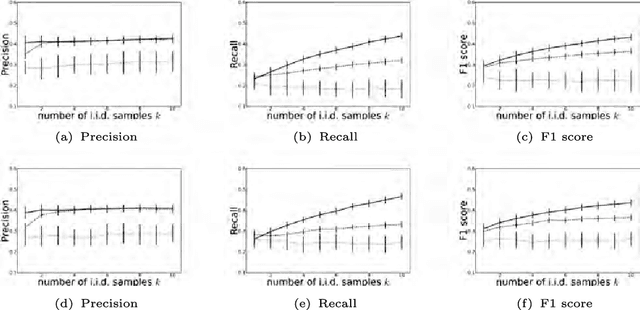
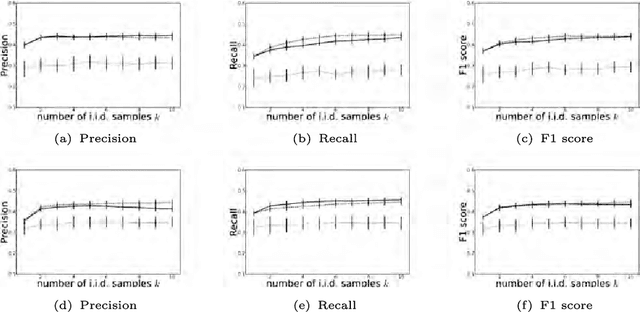
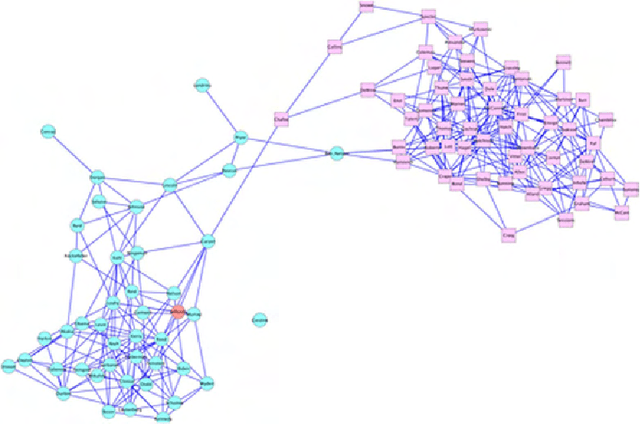
Stochastic networks are a plausible representation of the relational information among entities in dynamic systems such as living cells or social communities. While there is a rich literature in estimating a static or temporally invariant network from observation data, little has been done toward estimating time-varying networks from time series of entity attributes. In this paper we present two new machine learning methods for estimating time-varying networks, which both build on a temporally smoothed $l_1$-regularized logistic regression formalism that can be cast as a standard convex-optimization problem and solved efficiently using generic solvers scalable to large networks. We report promising results on recovering simulated time-varying networks. For real data sets, we reverse engineer the latent sequence of temporally rewiring political networks between Senators from the US Senate voting records and the latent evolving regulatory networks underlying 588 genes across the life cycle of Drosophila melanogaster from the microarray time course.
* Published in at http://dx.doi.org/10.1214/09-AOAS308 the Annals of Applied Statistics (http://www.imstat.org/aoas/) by the Institute of Mathematical Statistics (http://www.imstat.org)