 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBetter Training using Weight-Constrained Stochastic Dynamics
Jun 20, 2021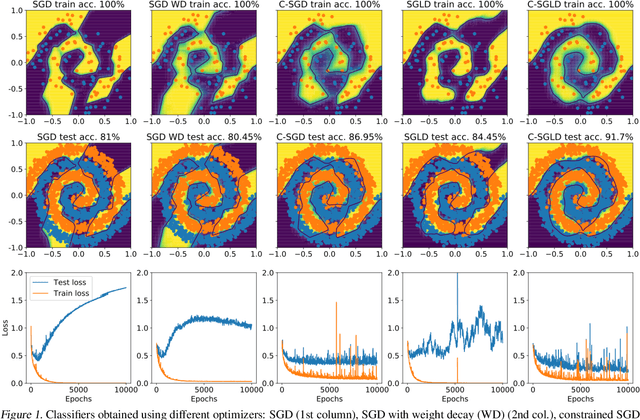
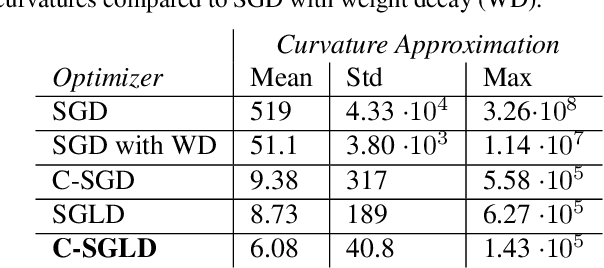
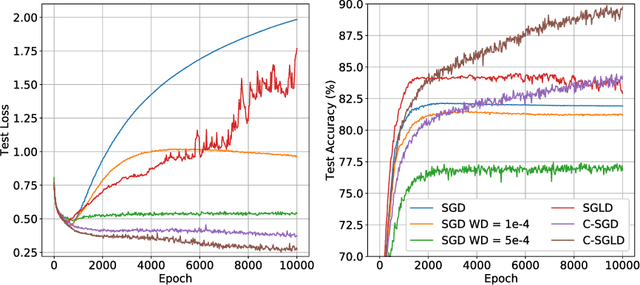
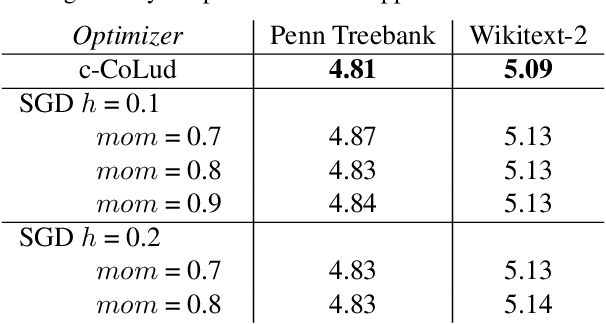
We employ constraints to control the parameter space of deep neural networks throughout training. The use of customized, appropriately designed constraints can reduce the vanishing/exploding gradients problem, improve smoothness of classification boundaries, control weight magnitudes and stabilize deep neural networks, and thus enhance the robustness of training algorithms and the generalization capabilities of neural networks. We provide a general approach to efficiently incorporate constraints into a stochastic gradient Langevin framework, allowing enhanced exploration of the loss landscape. We also present specific examples of constrained training methods motivated by orthogonality preservation for weight matrices and explicit weight normalizations. Discretization schemes are provided both for the overdamped formulation of Langevin dynamics and the underdamped form, in which momenta further improve sampling efficiency. These optimization schemes can be used directly, without needing to adapt neural network architecture design choices or to modify the objective with regularization terms, and see performance improvements in classification tasks.
* ICML 2021 camera-ready. arXiv admin note: substantial text overlap with arXiv:2006.10114
How Sensitive are Meta-Learners to Dataset Imbalance?
Apr 12, 2021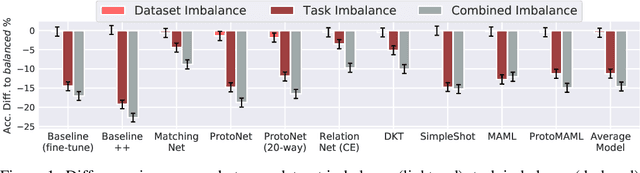
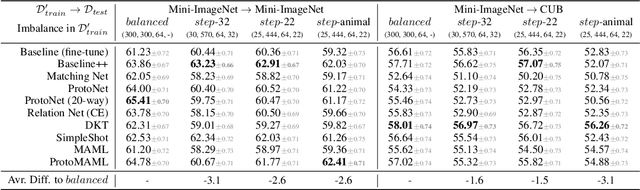
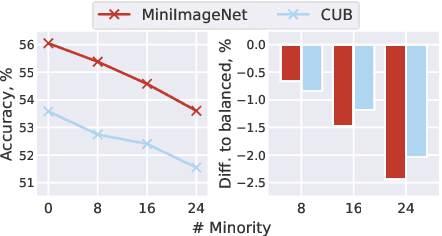
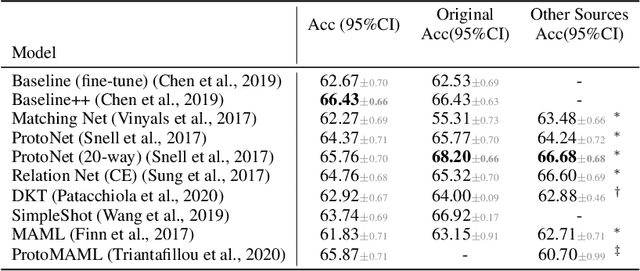
Meta-Learning (ML) has proven to be a useful tool for training Few-Shot Learning (FSL) algorithms by exposure to batches of tasks sampled from a meta-dataset. However, the standard training procedure overlooks the dynamic nature of the real-world where object classes are likely to occur at different frequencies. While it is generally understood that imbalanced tasks harm the performance of supervised methods, there is no significant research examining the impact of imbalanced meta-datasets on the FSL evaluation task. This study exposes the magnitude and extent of this problem. Our results show that ML methods are more robust against meta-dataset imbalance than imbalance at the task-level with a similar imbalance ratio ($\rho<20$), with the effect holding even in long-tail datasets under a larger imbalance ($\rho=65$). Overall, these results highlight an implicit strength of ML algorithms, capable of learning generalizable features under dataset imbalance and domain-shift. The code to reproduce the experiments is released under an open-source license.
Few-Shot Learning with Class Imbalance
Jan 07, 2021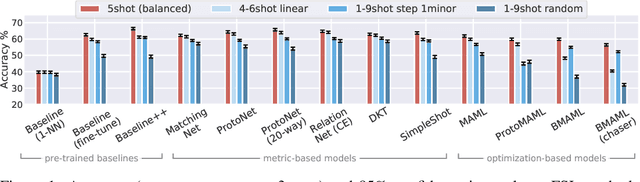
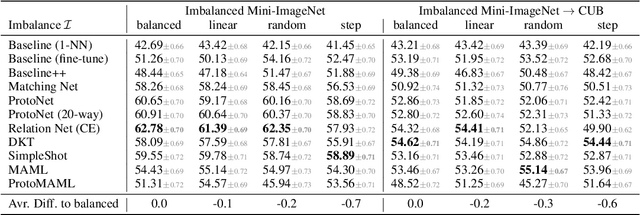
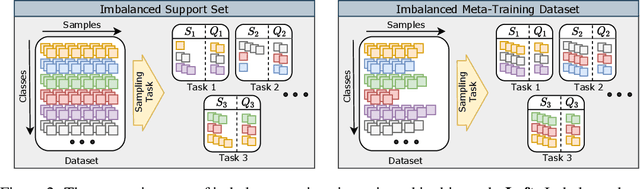
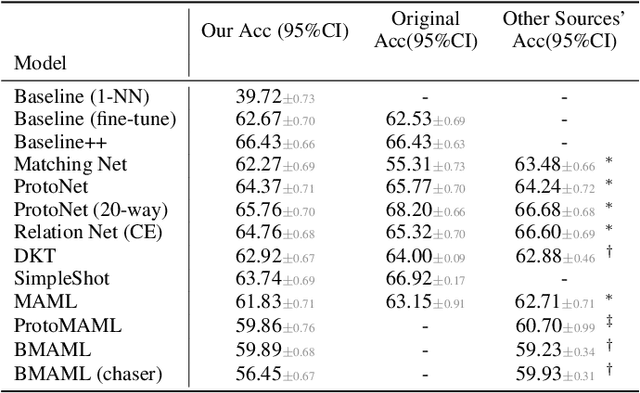
Few-shot learning aims to train models on a limited number of labeled samples given in a support set in order to generalize to unseen samples from a query set. In the standard setup, the support set contains an equal amount of data points for each class. However, this assumption overlooks many practical considerations arising from the dynamic nature of the real world, such as class-imbalance. In this paper, we present a detailed study of few-shot class-imbalance along three axes: meta-dataset vs. task imbalance, effect of different imbalance distributions (linear, step, random), and effect of rebalancing techniques. We extensively compare over 10 state-of-the-art few-shot learning and meta-learning methods using unbalanced tasks and meta-datasets. Our analysis using Mini-ImageNet reveals that 1) compared to the balanced task, the performances on class-imbalance tasks counterparts always drop, by up to $18.0\%$ for optimization-based methods, and up to $8.4$ for metric-based methods, 2) contrary to popular belief, meta-learning algorithms, such as MAML, do not automatically learn to balance by being exposed to imbalanced tasks during (meta-)training time, 3) strategies used to mitigate imbalance in supervised learning, such as oversampling, can offer a stronger solution to the class imbalance problem, 4) the effect of imbalance at the meta-dataset level is less significant than the effect at the task level with similar imbalance magnitude. The code to reproduce the experiments is released under an open-source license.
Latent Adversarial Debiasing: Mitigating Collider Bias in Deep Neural Networks
Nov 19, 2020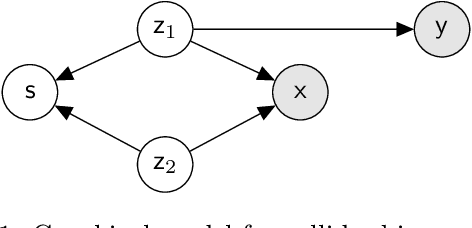
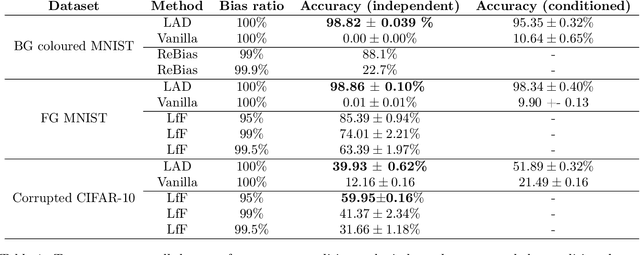
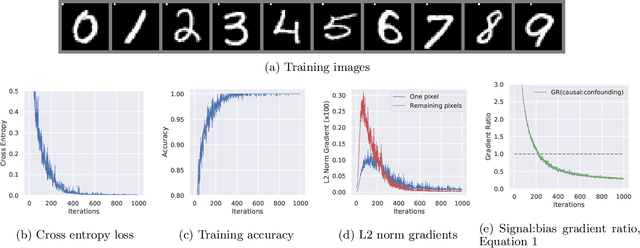
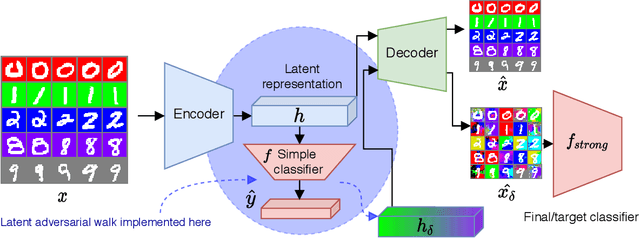
Collider bias is a harmful form of sample selection bias that neural networks are ill-equipped to handle. This bias manifests itself when the underlying causal signal is strongly correlated with other confounding signals due to the training data collection procedure. In the situation where the confounding signal is easy-to-learn, deep neural networks will latch onto this and the resulting model will generalise poorly to in-the-wild test scenarios. We argue herein that the cause of failure is a combination of the deep structure of neural networks and the greedy gradient-driven learning process used - one that prefers easy-to-compute signals when available. We show it is possible to mitigate against this by generating bias-decoupled training data using latent adversarial debiasing (LAD), even when the confounding signal is present in 100% of the training data. By training neural networks on these adversarial examples,we can improve their generalisation in collider bias settings. Experiments show state-of-the-art performance of LAD in label-free debiasing with gains of 76.12% on background coloured MNIST, 35.47% on fore-ground coloured MNIST, and 8.27% on corrupted CIFAR-10.
Non-greedy Gradient-based Hyperparameter Optimization Over Long Horizons
Jul 15, 2020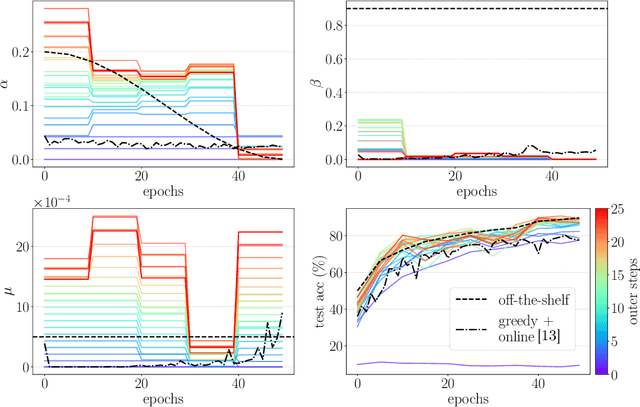
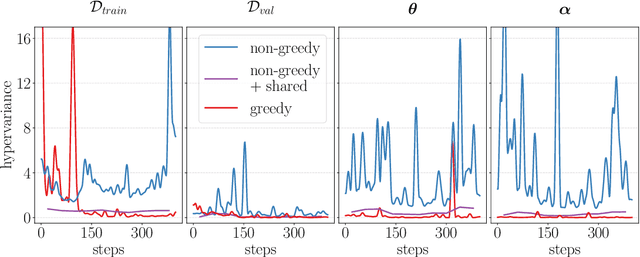
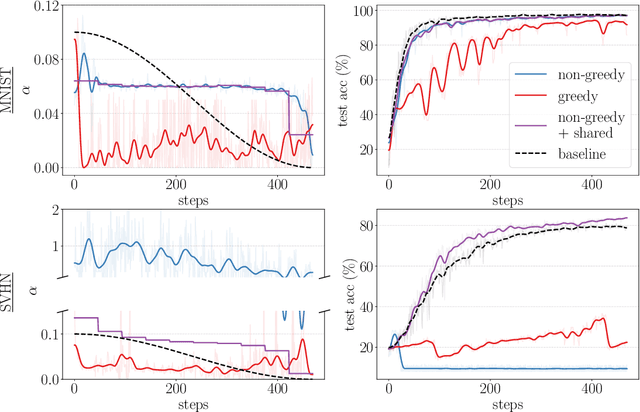
Gradient-based hyperparameter optimization is an attractive way to perform meta-learning across a distribution of tasks, or improve the performance of an optimizer on a single task. However, this approach has been unpopular for tasks requiring long horizons (many gradient steps), due to memory scaling and gradient degradation issues. A common workaround is to learn hyperparameters online or split the horizon into smaller chunks. However, this introduces greediness which comes with a large performance drop, since the best local hyperparameters can make for poor global solutions. In this work, we enable non-greediness over long horizons with a two-fold solution. First, we share hyperparameters that are contiguous in time, and show that this drastically mitigates gradient degradation issues. Then, we derive a forward-mode differentiation algorithm for the popular momentum-based SGD optimizer, which allows for a memory cost that is constant with horizon size. When put together, these solutions allow us to learn hyperparameters without any prior knowledge. Compared to the baseline of hand-tuned off-the-shelf hyperparameters, our method compares favorably on simple datasets like SVHN. On CIFAR-10 we match the baseline performance, and demonstrate for the first time that learning rate, momentum and weight decay schedules can be learned with gradients on a dataset of this size. Code is available at https://github.com/polo5/NonGreedyGradientHPO
Constraint-Based Regularization of Neural Networks
Jun 17, 2020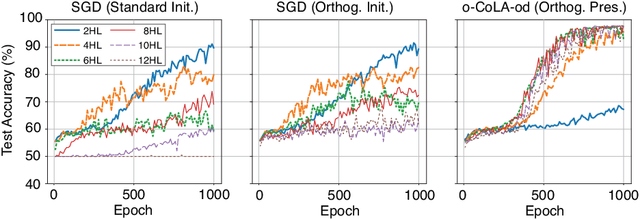


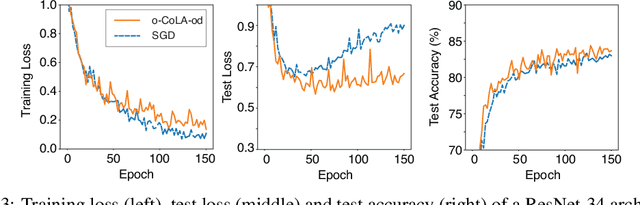
We propose a method for efficiently incorporating constraints into a stochastic gradient Langevin framework for the training of deep neural networks. Constraints allow direct control of the parameter space of the model. Appropriately designed, they reduce the vanishing/exploding gradient problem, control weight magnitudes and stabilize deep neural networks and thus improve the robustness of training algorithms and the generalization capabilities of the trained neural network. We present examples of constrained training methods motivated by orthogonality preservation for weight matrices and explicit weight normalizations. We describe the methods in the overdamped formulation of Langevin dynamics and the underdamped form, in which momenta help to improve sampling efficiency. The methods are explored in test examples in image classification and natural language processing.
Optimizing Grouped Convolutions on Edge Devices
Jun 17, 2020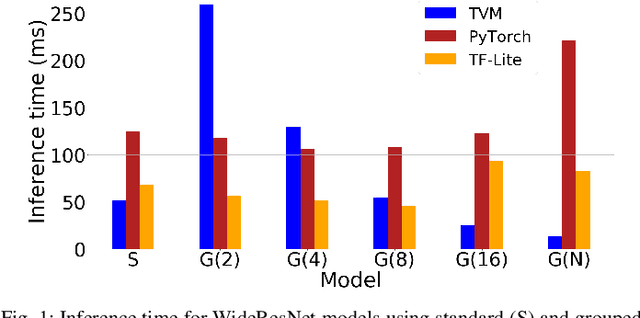
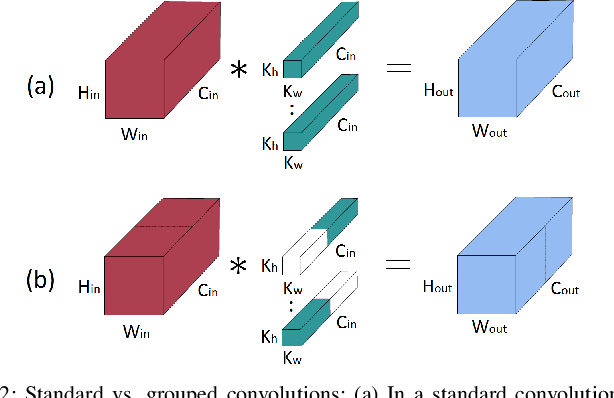
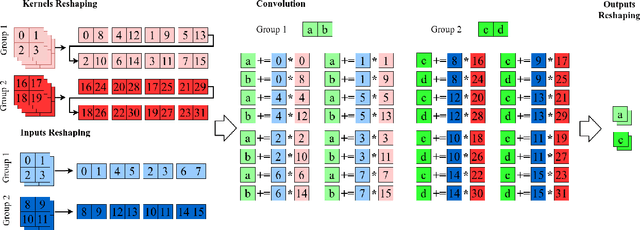
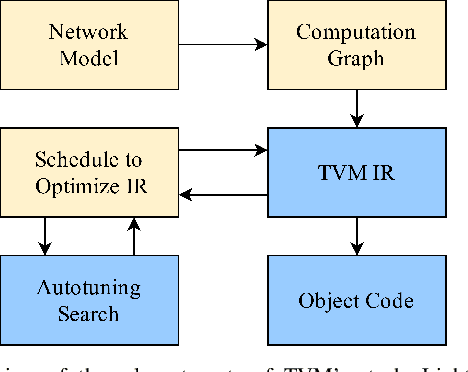
When deploying a deep neural network on constrained hardware, it is possible to replace the network's standard convolutions with grouped convolutions. This allows for substantial memory savings with minimal loss of accuracy. However, current implementations of grouped convolutions in modern deep learning frameworks are far from performing optimally in terms of speed. In this paper we propose Grouped Spatial Pack Convolutions (GSPC), a new implementation of grouped convolutions that outperforms existing solutions. We implement GSPC in TVM, which provides state-of-the-art performance on edge devices. We analyze a set of networks utilizing different types of grouped convolutions and evaluate their performance in terms of inference time on several edge devices. We observe that our new implementation scales well with the number of groups and provides the best inference times in all settings, improving the existing implementations of grouped convolutions in TVM, PyTorch and TensorFlow Lite by 3.4x, 8x and 4x on average respectively. Code is available at https://github.com/gecLAB/tvm-GSPC/
Self-Supervised Relational Reasoning for Representation Learning
Jun 10, 2020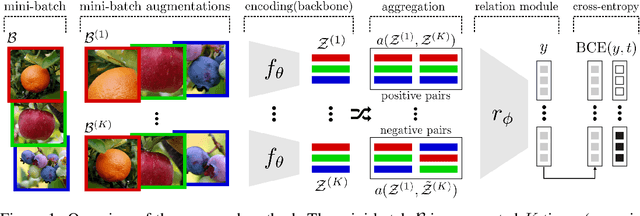
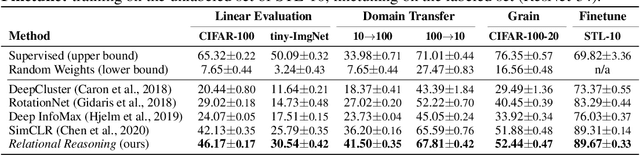
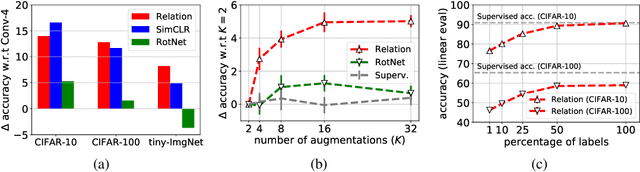
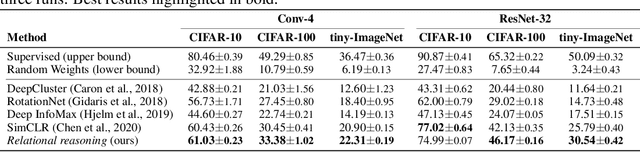
In self-supervised learning, a system is tasked with achieving a surrogate objective by defining alternative targets on a set of unlabeled data. The aim is to build useful representations that can be used in downstream tasks, without costly manual annotation. In this work, we propose a novel self-supervised formulation of relational reasoning that allows a learner to bootstrap a signal from information implicit in unlabeled data. Training a relation head to discriminate how entities relate to themselves (intra-reasoning) and other entities (inter-reasoning), results in rich and descriptive representations in the underlying neural network backbone, which can be used in downstream tasks such as classification and image retrieval. We evaluate the proposed method following a rigorous experimental procedure, using standard datasets, protocols, and backbones. Self-supervised relational reasoning outperforms the best competitor in all conditions by an average 14% in accuracy, and the most recent state-of-the-art model by 3%. We link the effectiveness of the method to the maximization of a Bernoulli log-likelihood, which can be considered as a proxy for maximizing the mutual information, resulting in a more efficient objective with respect to the commonly used contrastive losses.
Neural Architecture Search without Training
Jun 08, 2020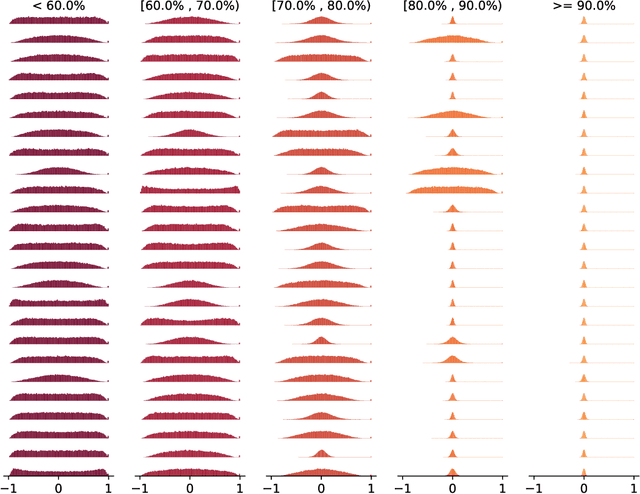
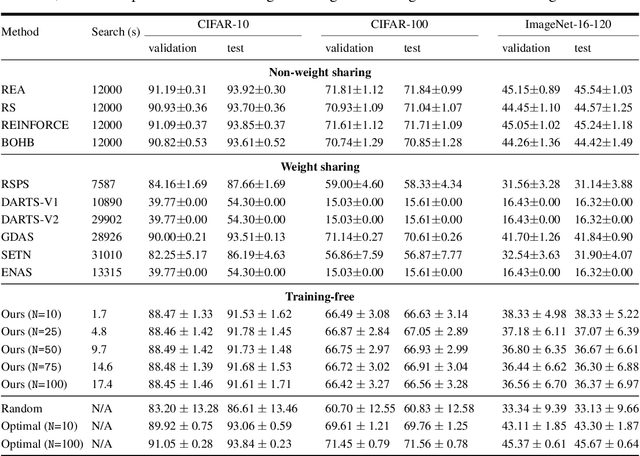

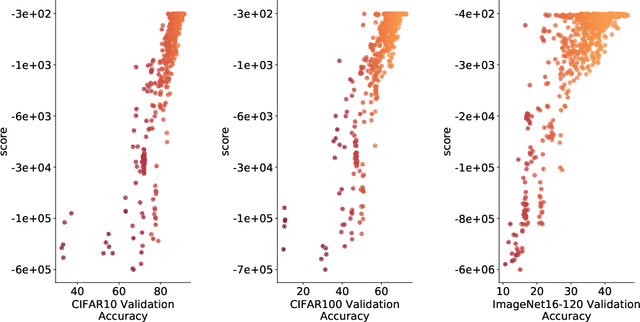
The time and effort involved in hand-designing deep neural networks is immense. This has prompted the development of Neural Architecture Search (NAS) techniques to automate this design. However, NAS algorithms tend to be extremely slow and expensive; they need to train vast numbers of candidate networks to inform the search process. This could be remedied if we could infer a network's trained accuracy from its initial state. In this work, we examine how the linear maps induced by data points correlate for untrained network architectures in the NAS-Bench-201 search space, and motivate how this can be used to give a measure of modelling flexibility which is highly indicative of a network's trained performance. We incorporate this measure into a simple algorithm that allows us to search for powerful networks without any training in a matter of seconds on a single GPU. Code to reproduce our experiments is available at https://github.com/BayesWatch/nas-without-training.
Defining Benchmarks for Continual Few-Shot Learning
Apr 15, 2020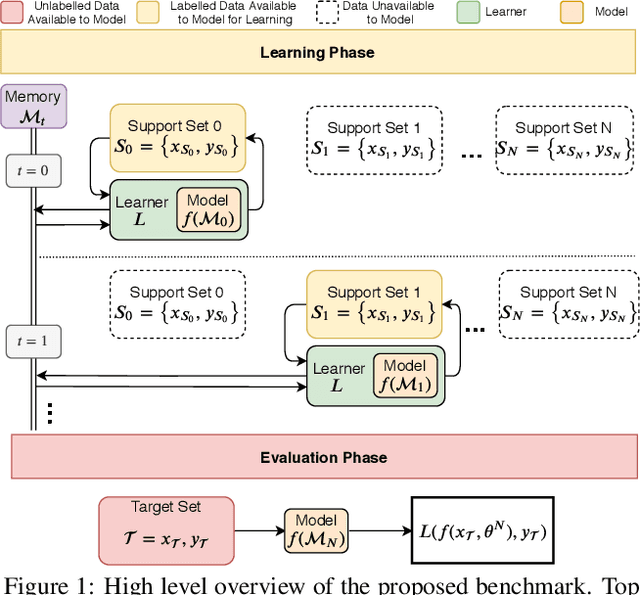
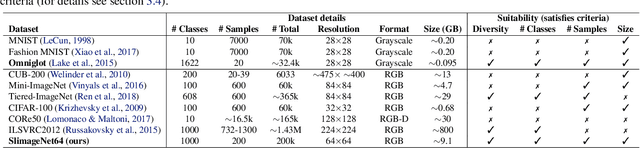
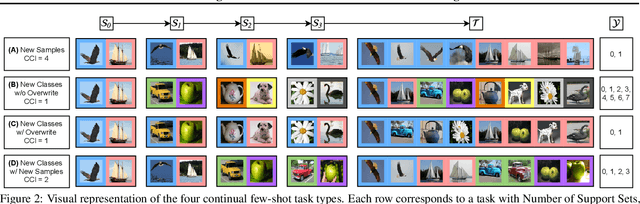
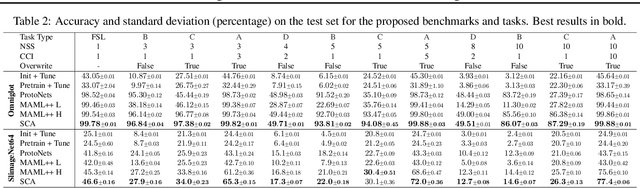
Both few-shot and continual learning have seen substantial progress in the last years due to the introduction of proper benchmarks. That being said, the field has still to frame a suite of benchmarks for the highly desirable setting of continual few-shot learning, where the learner is presented a number of few-shot tasks, one after the other, and then asked to perform well on a validation set stemming from all previously seen tasks. Continual few-shot learning has a small computational footprint and is thus an excellent setting for efficient investigation and experimentation. In this paper we first define a theoretical framework for continual few-shot learning, taking into account recent literature, then we propose a range of flexible benchmarks that unify the evaluation criteria and allows exploring the problem from multiple perspectives. As part of the benchmark, we introduce a compact variant of ImageNet, called SlimageNet64, which retains all original 1000 classes but only contains 200 instances of each one (a total of 200K data-points) downscaled to 64 x 64 pixels. We provide baselines for the proposed benchmarks using a number of popular few-shot learning algorithms, as a result, exposing previously unknown strengths and weaknesses of those algorithms in continual and data-limited settings.