 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePOSTURE: Pose Guided Unsupervised Domain Adaptation for Human Body Part Segmentation
Jul 04, 2024



Existing algorithms for human body part segmentation have shown promising results on challenging datasets, primarily relying on end-to-end supervision. However, these algorithms exhibit severe performance drops in the face of domain shifts, leading to inaccurate segmentation masks. To tackle this issue, we introduce POSTURE: \underline{Po}se Guided Un\underline{s}upervised Domain Adap\underline{t}ation for H\underline{u}man Body Pa\underline{r}t S\underline{e}gmentation - an innovative pseudo-labelling approach designed to improve segmentation performance on the unlabeled target data. Distinct from conventional domain adaptive methods for general semantic segmentation, POSTURE stands out by considering the underlying structure of the human body and uses anatomical guidance from pose keypoints to drive the adaptation process. This strong inductive prior translates to impressive performance improvements, averaging 8\% over existing state-of-the-art domain adaptive semantic segmentation methods across three benchmark datasets. Furthermore, the inherent flexibility of our proposed approach facilitates seamless extension to source-free settings (SF-POSTURE), effectively mitigating potential privacy and computational concerns, with negligible drop in performance.
Cross-Modal Safety Alignment: Is textual unlearning all you need?
May 27, 2024



Recent studies reveal that integrating new modalities into Large Language Models (LLMs), such as Vision-Language Models (VLMs), creates a new attack surface that bypasses existing safety training techniques like Supervised Fine-tuning (SFT) and Reinforcement Learning with Human Feedback (RLHF). While further SFT and RLHF-based safety training can be conducted in multi-modal settings, collecting multi-modal training datasets poses a significant challenge. Inspired by the structural design of recent multi-modal models, where, regardless of the combination of input modalities, all inputs are ultimately fused into the language space, we aim to explore whether unlearning solely in the textual domain can be effective for cross-modality safety alignment. Our evaluation across six datasets empirically demonstrates the transferability -- textual unlearning in VLMs significantly reduces the Attack Success Rate (ASR) to less than 8\% and in some cases, even as low as nearly 2\% for both text-based and vision-text-based attacks, alongside preserving the utility. Moreover, our experiments show that unlearning with a multi-modal dataset offers no potential benefits but incurs significantly increased computational demands, possibly up to 6 times higher.
FLASH: Federated Learning Across Simultaneous Heterogeneities
Feb 13, 2024



The key premise of federated learning (FL) is to train ML models across a diverse set of data-owners (clients), without exchanging local data. An overarching challenge to this date is client heterogeneity, which may arise not only from variations in data distribution, but also in data quality, as well as compute/communication latency. An integrated view of these diverse and concurrent sources of heterogeneity is critical; for instance, low-latency clients may have poor data quality, and vice versa. In this work, we propose FLASH(Federated Learning Across Simultaneous Heterogeneities), a lightweight and flexible client selection algorithm that outperforms state-of-the-art FL frameworks under extensive sources of heterogeneity, by trading-off the statistical information associated with the client's data quality, data distribution, and latency. FLASH is the first method, to our knowledge, for handling all these heterogeneities in a unified manner. To do so, FLASH models the learning dynamics through contextual multi-armed bandits (CMAB) and dynamically selects the most promising clients. Through extensive experiments, we demonstrate that FLASH achieves substantial and consistent improvements over state-of-the-art baselines -- as much as 10% in absolute accuracy -- thanks to its unified approach. Importantly, FLASH also outperforms federated aggregation methods that are designed to handle highly heterogeneous settings and even enjoys a performance boost when integrated with them.
Plug-and-Play Transformer Modules for Test-Time Adaptation
Jan 10, 2024



Parameter-efficient tuning (PET) methods such as LoRA, Adapter, and Visual Prompt Tuning (VPT) have found success in enabling adaptation to new domains by tuning small modules within a transformer model. However, the number of domains encountered during test time can be very large, and the data is usually unlabeled. Thus, adaptation to new domains is challenging; it is also impractical to generate customized tuned modules for each such domain. Toward addressing these challenges, this work introduces PLUTO: a Plug-and-pLay modUlar Test-time domain adaptatiOn strategy. We pre-train a large set of modules, each specialized for different source domains, effectively creating a ``module store''. Given a target domain with few-shot unlabeled data, we introduce an unsupervised test-time adaptation (TTA) method to (1) select a sparse subset of relevant modules from this store and (2) create a weighted combination of selected modules without tuning their weights. This plug-and-play nature enables us to harness multiple most-relevant source domains in a single inference call. Comprehensive evaluations demonstrate that PLUTO uniformly outperforms alternative TTA methods and that selecting $\leq$5 modules suffice to extract most of the benefit. At a high level, our method equips pre-trained transformers with the capability to dynamically adapt to new domains, motivating a new paradigm for efficient and scalable domain adaptation.
MeTA: Multi-source Test Time Adaptation
Jan 04, 2024



Test time adaptation is the process of adapting, in an unsupervised manner, a pre-trained source model to each incoming batch of the test data (i.e., without requiring a substantial portion of the test data to be available, as in traditional domain adaptation) and without access to the source data. Since it works with each batch of test data, it is well-suited for dynamic environments where decisions need to be made as the data is streaming in. Current test time adaptation methods are primarily focused on a single source model. We propose the first completely unsupervised Multi-source Test Time Adaptation (MeTA) framework that handles multiple source models and optimally combines them to adapt to the test data. MeTA has two distinguishing features. First, it efficiently obtains the optimal combination weights to combine the source models to adapt to the test data distribution. Second, it identifies which of the source model parameters to update so that only the model which is most correlated to the target data is adapted, leaving the less correlated ones untouched; this mitigates the issue of "forgetting" the source model parameters by focusing only on the source model that exhibits the strongest correlation with the test batch distribution. Experiments on diverse datasets demonstrate that the combination of multiple source models does at least as well as the best source (with hindsight knowledge), and performance does not degrade as the test data distribution changes over time (robust to forgetting).
TEMP3D: Temporally Continuous 3D Human Pose Estimation Under Occlusions
Dec 24, 2023
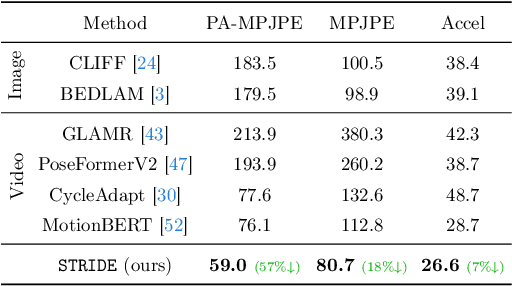
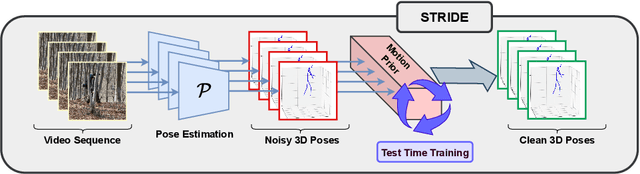
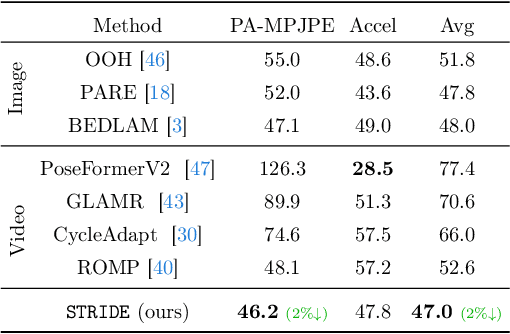
Existing 3D human pose estimation methods perform remarkably well in both monocular and multi-view settings. However, their efficacy diminishes significantly in the presence of heavy occlusions, which limits their practical utility. For video sequences, temporal continuity can help infer accurate poses, especially in heavily occluded frames. In this paper, we aim to leverage this potential of temporal continuity through human motion priors, coupled with large-scale pre-training on 3D poses and self-supervised learning, to enhance 3D pose estimation in a given video sequence. This leads to a temporally continuous 3D pose estimate on unlabelled in-the-wild videos, which may contain occlusions, while exclusively relying on pre-trained 3D pose models. We propose an unsupervised method named TEMP3D that aligns a motion prior model on a given in-the-wild video using existing SOTA single image-based 3D pose estimation methods to give temporally continuous output under occlusions. To evaluate our method, we test it on the Occluded Human3.6M dataset, our custom-built dataset which contains significantly large (up to 100%) human body occlusions incorporated into the Human3.6M dataset. We achieve SOTA results on Occluded Human3.6M and the OcMotion dataset while maintaining competitive performance on non-occluded data. URL: https://sites.google.com/ucr.edu/temp3d
Active Learning Guided Federated Online Adaptation: Applications in Medical Image Segmentation
Dec 08, 2023Data privacy, storage, and distribution shifts are major bottlenecks in medical image analysis. Data cannot be shared across patients, physicians, and facilities due to privacy concerns, usually requiring each patient's data to be analyzed in a discreet setting at a near real-time pace. However, one would like to take advantage of the accumulated knowledge across healthcare facilities as the computational systems analyze data of more and more patients while incorporating feedback provided by physicians to improve accuracy. Motivated by these, we propose a method for medical image segmentation that adapts to each incoming data batch (online adaptation), incorporates physician feedback through active learning, and assimilates knowledge across facilities in a federated setup. Combining an online adaptation scheme at test time with an efficient sampling strategy with budgeted annotation helps bridge the gap between the source and the incoming stream of target domain data. A federated setup allows collaborative aggregation of knowledge across distinct distributed models without needing to share the data across different models. This facilitates the improvement of performance over time by accumulating knowledge across users. Towards achieving these goals, we propose a computationally amicable, privacy-preserving image segmentation technique \textbf{DrFRODA} that uses federated learning to adapt the model in an online manner with feedback from doctors in the loop. Our experiments on publicly available datasets show that the proposed distributed active learning-based online adaptation method outperforms unsupervised online adaptation methods and shows competitive results with offline active learning-based adaptation methods.
Towards Granularity-adjusted Pixel-level Semantic Annotation
Dec 05, 2023



Recent advancements in computer vision predominantly rely on learning-based systems, leveraging annotations as the driving force to develop specialized models. However, annotating pixel-level information, particularly in semantic segmentation, presents a challenging and labor-intensive task, prompting the need for autonomous processes. In this work, we propose GranSAM which distinguishes itself by providing semantic segmentation at the user-defined granularity level on unlabeled data without the need for any manual supervision, offering a unique contribution in the realm of semantic mask annotation method. Specifically, we propose an approach to enable the Segment Anything Model (SAM) with semantic recognition capability to generate pixel-level annotations for images without any manual supervision. For this, we accumulate semantic information from synthetic images generated by the Stable Diffusion model or web crawled images and employ this data to learn a mapping function between SAM mask embeddings and object class labels. As a result, SAM, enabled with granularity-adjusted mask recognition, can be used for pixel-level semantic annotation purposes. We conducted experiments on the PASCAL VOC 2012 and COCO-80 datasets and observed a +17.95% and +5.17% increase in mIoU, respectively, compared to existing state-of-the-art methods when evaluated under our problem setting.
POISE: Pose Guided Human Silhouette Extraction under Occlusions
Nov 09, 2023



Human silhouette extraction is a fundamental task in computer vision with applications in various downstream tasks. However, occlusions pose a significant challenge, leading to incomplete and distorted silhouettes. To address this challenge, we introduce POISE: Pose Guided Human Silhouette Extraction under Occlusions, a novel self-supervised fusion framework that enhances accuracy and robustness in human silhouette prediction. By combining initial silhouette estimates from a segmentation model with human joint predictions from a 2D pose estimation model, POISE leverages the complementary strengths of both approaches, effectively integrating precise body shape information and spatial information to tackle occlusions. Furthermore, the self-supervised nature of \POISE eliminates the need for costly annotations, making it scalable and practical. Extensive experimental results demonstrate its superiority in improving silhouette extraction under occlusions, with promising results in downstream tasks such as gait recognition. The code for our method is available https://github.com/take2rohit/poise.
Effective Restoration of Source Knowledge in Continual Test Time Adaptation
Nov 08, 2023Traditional test-time adaptation (TTA) methods face significant challenges in adapting to dynamic environments characterized by continuously changing long-term target distributions. These challenges primarily stem from two factors: catastrophic forgetting of previously learned valuable source knowledge and gradual error accumulation caused by miscalibrated pseudo labels. To address these issues, this paper introduces an unsupervised domain change detection method that is capable of identifying domain shifts in dynamic environments and subsequently resets the model parameters to the original source pre-trained values. By restoring the knowledge from the source, it effectively corrects the negative consequences arising from the gradual deterioration of model parameters caused by ongoing shifts in the domain. Our method involves progressive estimation of global batch-norm statistics specific to each domain, while keeping track of changes in the statistics triggered by domain shifts. Importantly, our method is agnostic to the specific adaptation technique employed and thus, can be incorporated to existing TTA methods to enhance their performance in dynamic environments. We perform extensive experiments on benchmark datasets to demonstrate the superior performance of our method compared to state-of-the-art adaptation methods.