 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCAR-Net: Clairvoyant Attentive Recurrent Network
Jul 31, 2018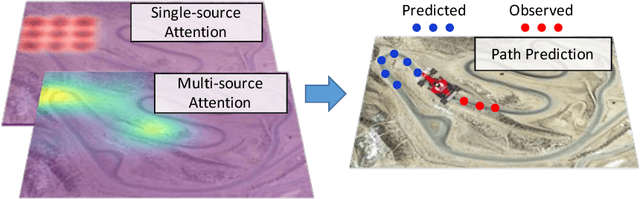

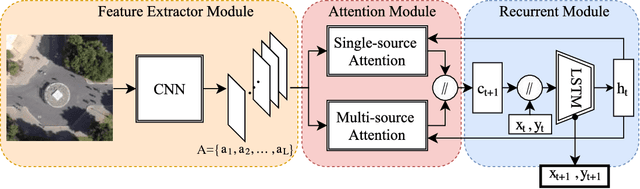
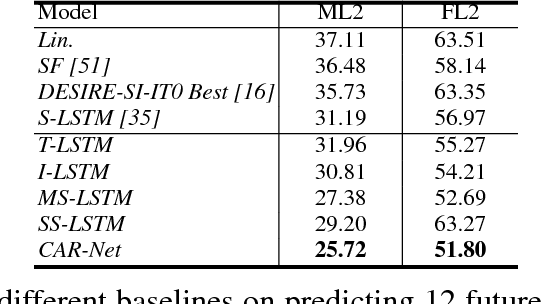
We present an interpretable framework for path prediction that leverages dependencies between agents' behaviors and their spatial navigation environment. We exploit two sources of information: the past motion trajectory of the agent of interest and a wide top-view image of the navigation scene. We propose a Clairvoyant Attentive Recurrent Network (CAR-Net) that learns where to look in a large image of the scene when solving the path prediction task. Our method can attend to any area, or combination of areas, within the raw image (e.g., road intersections) when predicting the trajectory of the agent. This allows us to visualize fine-grained semantic elements of navigation scenes that influence the prediction of trajectories. To study the impact of space on agents' trajectories, we build a new dataset made of top-view images of hundreds of scenes (Formula One racing tracks) where agents' behaviors are heavily influenced by known areas in the images (e.g., upcoming turns). CAR-Net successfully attends to these salient regions. Additionally, CAR-Net reaches state-of-the-art accuracy on the standard trajectory forecasting benchmark, Stanford Drone Dataset (SDD). Finally, we show CAR-Net's ability to generalize to unseen scenes.
* The 2nd and 3rd authors contributed equally
GONet: A Semi-Supervised Deep Learning Approach For Traversability Estimation
Mar 08, 2018
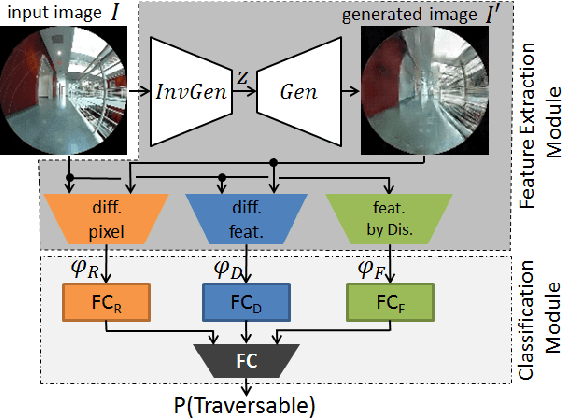

We present semi-supervised deep learning approaches for traversability estimation from fisheye images. Our method, GONet, and the proposed extensions leverage Generative Adversarial Networks (GANs) to effectively predict whether the area seen in the input image(s) is safe for a robot to traverse. These methods are trained with many positive images of traversable places, but just a small set of negative images depicting blocked and unsafe areas. This makes the proposed methods practical. Positive examples can be collected easily by simply operating a robot through traversable spaces, while obtaining negative examples is time consuming, costly, and potentially dangerous. Through extensive experiments and several demonstrations, we show that the proposed traversability estimation approaches are robust and can generalize to unseen scenarios. Further, we demonstrate that our methods are memory efficient and fast, allowing for real-time operation on a mobile robot with single or stereo fisheye cameras. As part of our contributions, we open-source two new datasets for traversability estimation. These datasets are composed of approximately 24h of videos from more than 25 indoor environments. Our methods outperform baseline approaches for traversability estimation on these new datasets.
To Go or Not To Go? A Near Unsupervised Learning Approach For Robot Navigation
Sep 16, 2017


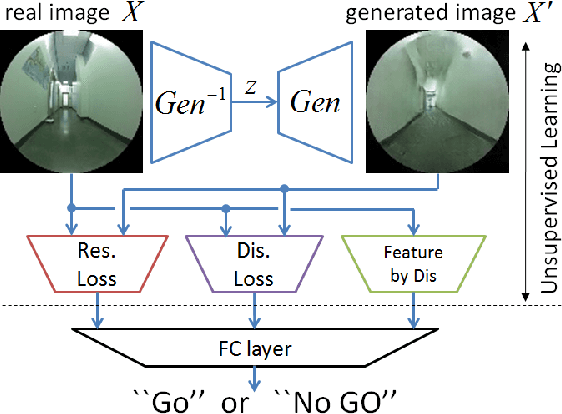
It is important for robots to be able to decide whether they can go through a space or not, as they navigate through a dynamic environment. This capability can help them avoid injury or serious damage, e.g., as a result of running into people and obstacles, getting stuck, or falling off an edge. To this end, we propose an unsupervised and a near-unsupervised method based on Generative Adversarial Networks (GAN) to classify scenarios as traversable or not based on visual data. Our method is inspired by the recent success of data-driven approaches on computer vision problems and anomaly detection, and reduces the need for vast amounts of negative examples at training time. Collecting negative data indicating that a robot should not go through a space is typically hard and dangerous because of collisions, whereas collecting positive data can be automated and done safely based on the robot's own traveling experience. We verify the generality and effectiveness of the proposed approach on a test dataset collected in a previously unseen environment with a mobile robot. Furthermore, we show that our method can be used to build costmaps (we call as "GoNoGo" costmaps) for robot path planning using visual data only.
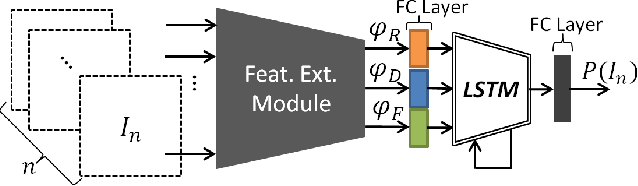
Tracking The Untrackable: Learning To Track Multiple Cues with Long-Term Dependencies
Apr 03, 2017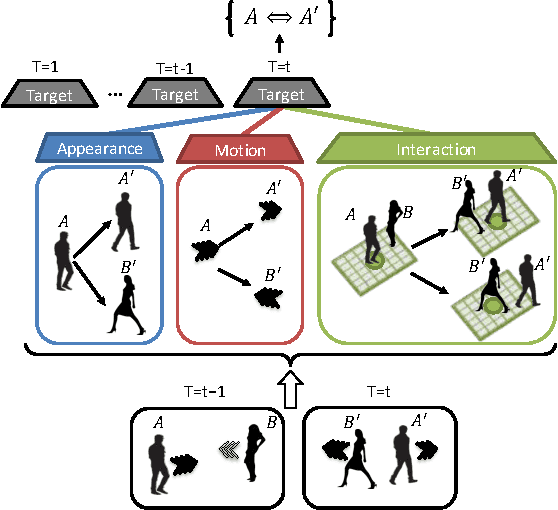

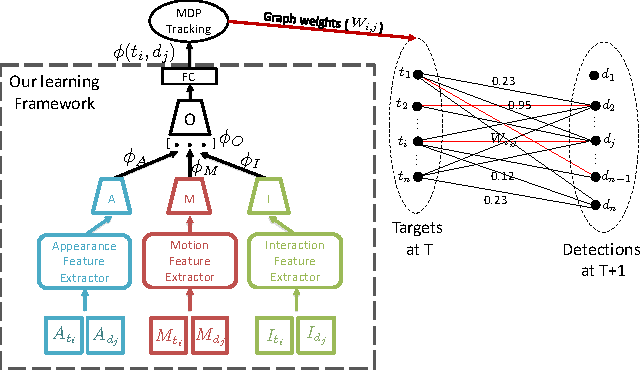
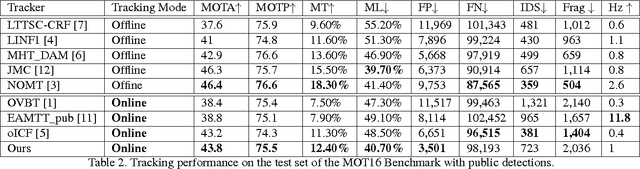
The majority of existing solutions to the Multi-Target Tracking (MTT) problem do not combine cues in a coherent end-to-end fashion over a long period of time. However, we present an online method that encodes long-term temporal dependencies across multiple cues. One key challenge of tracking methods is to accurately track occluded targets or those which share similar appearance properties with surrounding objects. To address this challenge, we present a structure of Recurrent Neural Networks (RNN) that jointly reasons on multiple cues over a temporal window. We are able to correct many data association errors and recover observations from an occluded state. We demonstrate the robustness of our data-driven approach by tracking multiple targets using their appearance, motion, and even interactions. Our method outperforms previous works on multiple publicly available datasets including the challenging MOT benchmark.
Forecasting Social Navigation in Crowded Complex Scenes
Jan 05, 2016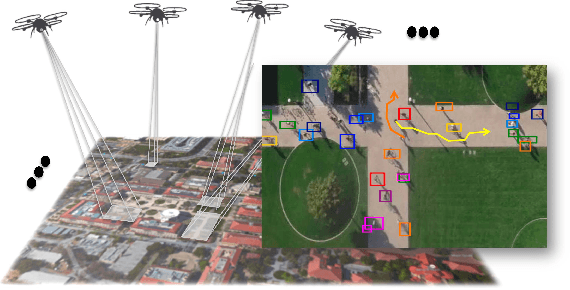
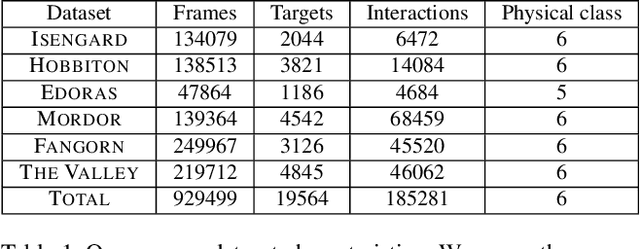
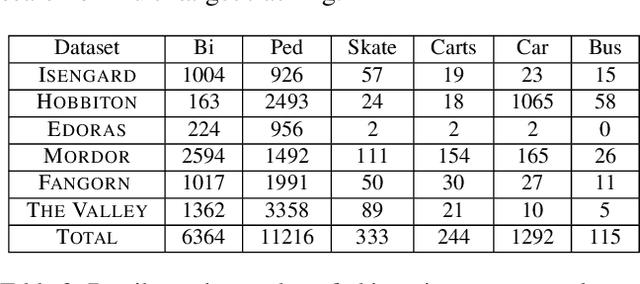
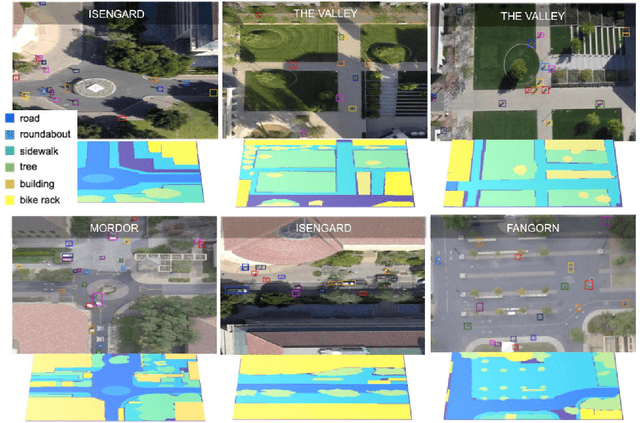
When humans navigate a crowed space such as a university campus or the sidewalks of a busy street, they follow common sense rules based on social etiquette. In this paper, we argue that in order to enable the design of new algorithms that can take fully advantage of these rules to better solve tasks such as target tracking or trajectory forecasting, we need to have access to better data in the first place. To that end, we contribute the very first large scale dataset (to the best of our knowledge) that collects images and videos of various types of targets (not just pedestrians, but also bikers, skateboarders, cars, buses, golf carts) that navigate in a real-world outdoor environment such as a university campus. We present an extensive evaluation where different methods for trajectory forecasting are evaluated and compared. Moreover, we present a new algorithm for trajectory prediction that exploits the complexity of our new dataset and allows to: i) incorporate inter-class interactions into trajectory prediction models (e.g, pedestrian vs bike) as opposed to just intra-class interactions (e.g., pedestrian vs pedestrian); ii) model the degree to which the social forces are regulating an interaction. We call the latter "social sensitivity"and it captures the sensitivity to which a target is responding to a certain interaction. An extensive experimental evaluation demonstrates the effectiveness of our novel approach.