 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVersatile Scene-Consistent Traffic Scenario Generation as Optimization with Diffusion
Apr 03, 2024Generating realistic and controllable agent behaviors in traffic simulation is crucial for the development of autonomous vehicles. This problem is often formulated as imitation learning (IL) from real-world driving data by either directly predicting future trajectories or inferring cost functions with inverse optimal control. In this paper, we draw a conceptual connection between IL and diffusion-based generative modeling and introduce a novel framework Versatile Behavior Diffusion (VBD) to simulate interactive scenarios with multiple traffic participants. Our model not only generates scene-consistent multi-agent interactions but also enables scenario editing through multi-step guidance and refinement. Experimental evaluations show that VBD achieves state-of-the-art performance on the Waymo Sim Agents benchmark. In addition, we illustrate the versatility of our model by adapting it to various applications. VBD is capable of producing scenarios conditioning on priors, integrating with model-based optimization, sampling multi-modal scene-consistent scenarios by fusing marginal predictions, and generating safety-critical scenarios when combined with a game-theoretic solver.
Empirical Analysis of Multi-Task Learning for Reducing Model Bias in Toxic Comment Detection
Sep 26, 2019
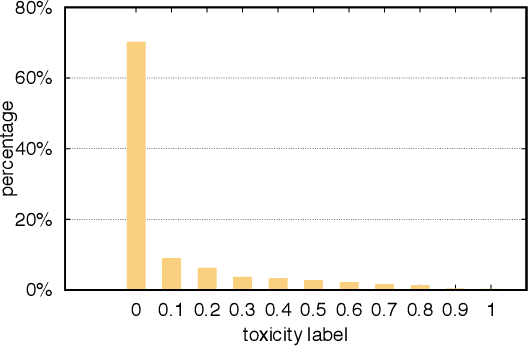

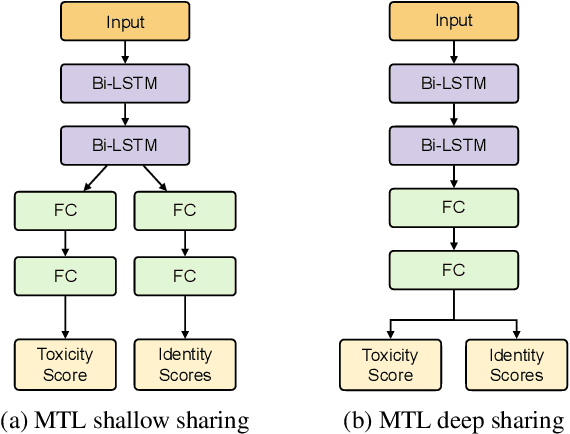
With the recent rise of toxicity in online conversations on social media platforms, using modern machine learning algorithms for toxic comment detection has become a central focus of many online applications. Researchers and companies have developed a variety of shallow and deep learning models to identify toxicity in online conversations, reviews, or comments with mixed successes. However, these existing approaches have learned to incorrectly associate non-toxic comments that have certain trigger-words (e.g. gay, lesbian, black, muslim) as a potential source of toxicity. In this paper, we evaluate dozens of state-of-the-art models with the specific focus of reducing model bias towards these commonly-attacked identity groups. We propose a multi-task learning model with an attention layer that jointly learns to predict the toxicity of a comment as well as the identities present in the comments in order to reduce this bias. We then compare our model to an array of shallow and deep-learning models using metrics designed especially to test for unintended model bias within these identity groups.