 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCSTS: Conditional Semantic Textual Similarity
May 24, 2023



Semantic textual similarity (STS) has been a cornerstone task in NLP that measures the degree of similarity between a pair of sentences, with applications in information retrieval, question answering, and embedding methods. However, it is an inherently ambiguous task, with the sentence similarity depending on the specific aspect of interest. We resolve this ambiguity by proposing a novel task called conditional STS (C-STS) which measures similarity conditioned on an aspect elucidated in natural language (hereon, condition). As an example, the similarity between the sentences "The NBA player shoots a three-pointer." and "A man throws a tennis ball into the air to serve." is higher for the condition "The motion of the ball." (both upward) and lower for "The size of the ball." (one large and one small). C-STS's advantages are two-fold: (1) it reduces the subjectivity and ambiguity of STS, and (2) enables fine-grained similarity evaluation using diverse conditions. C-STS contains almost 20,000 instances from diverse domains and we evaluate several state-of-the-art models to demonstrate that even the most performant fine-tuning and in-context learning models (GPT-4, Flan, SimCSE) find it challenging, with Spearman correlation scores of <50. We encourage the community to evaluate their models on C-STS to provide a more holistic view of semantic similarity and natural language understanding.
Anthropomorphization of AI: Opportunities and Risks
May 24, 2023Anthropomorphization is the tendency to attribute human-like traits to non-human entities. It is prevalent in many social contexts -- children anthropomorphize toys, adults do so with brands, and it is a literary device. It is also a versatile tool in science, with behavioral psychology and evolutionary biology meticulously documenting its consequences. With widespread adoption of AI systems, and the push from stakeholders to make it human-like through alignment techniques, human voice, and pictorial avatars, the tendency for users to anthropomorphize it increases significantly. We take a dyadic approach to understanding this phenomenon with large language models (LLMs) by studying (1) the objective legal implications, as analyzed through the lens of the recent blueprint of AI bill of rights and the (2) subtle psychological aspects customization and anthropomorphization. We find that anthropomorphized LLMs customized for different user bases violate multiple provisions in the legislative blueprint. In addition, we point out that anthropomorphization of LLMs affects the influence they can have on their users, thus having the potential to fundamentally change the nature of human-AI interaction, with potential for manipulation and negative influence. With LLMs being hyper-personalized for vulnerable groups like children and patients among others, our work is a timely and important contribution. We propose a conservative strategy for the cautious use of anthropomorphization to improve trustworthiness of AI systems.
Toxicity in ChatGPT: Analyzing Persona-assigned Language Models
Apr 11, 2023



Large language models (LLMs) have shown incredible capabilities and transcended the natural language processing (NLP) community, with adoption throughout many services like healthcare, therapy, education, and customer service. Since users include people with critical information needs like students or patients engaging with chatbots, the safety of these systems is of prime importance. Therefore, a clear understanding of the capabilities and limitations of LLMs is necessary. To this end, we systematically evaluate toxicity in over half a million generations of ChatGPT, a popular dialogue-based LLM. We find that setting the system parameter of ChatGPT by assigning it a persona, say that of the boxer Muhammad Ali, significantly increases the toxicity of generations. Depending on the persona assigned to ChatGPT, its toxicity can increase up to 6x, with outputs engaging in incorrect stereotypes, harmful dialogue, and hurtful opinions. This may be potentially defamatory to the persona and harmful to an unsuspecting user. Furthermore, we find concerning patterns where specific entities (e.g., certain races) are targeted more than others (3x more) irrespective of the assigned persona, that reflect inherent discriminatory biases in the model. We hope that our findings inspire the broader AI community to rethink the efficacy of current safety guardrails and develop better techniques that lead to robust, safe, and trustworthy AI systems.
MUX-PLMs: Pre-training Language Models with Data Multiplexing
Feb 24, 2023



Data multiplexing is a recently proposed method for improving a model's inference efficiency by processing multiple instances simultaneously using an ordered representation mixture. Prior work on data multiplexing only used task-specific Transformers without any pre-training, which limited their accuracy and generality. In this paper, we develop pre-trained multiplexed language models (MUX-PLMs) that can be widely finetuned on any downstream task. Our approach includes a three-stage training procedure and novel multiplexing and demultiplexing modules for improving throughput and downstream task accuracy. We demonstrate our method on BERT and ELECTRA pre-training objectives, with our MUX-BERT and MUX-ELECTRA models achieving 2x/5x inference speedup with a 2-4 \% drop in absolute performance on GLUE and 1-2 \% drop on token-level tasks.
SemSup-XC: Semantic Supervision for Zero and Few-shot Extreme Classification
Jan 26, 2023



Extreme classification (XC) involves predicting over large numbers of classes (thousands to millions), with real-world applications like news article classification and e-commerce product tagging. The zero-shot version of this task requires generalization to novel classes without additional supervision. In this paper, we develop SemSup-XC, a model that achieves state-of-the-art zero-shot and few-shot performance on three XC datasets derived from legal, e-commerce, and Wikipedia data. To develop SemSup-XC, we use automatically collected semantic class descriptions to represent classes and facilitate generalization through a novel hybrid matching module that matches input instances to class descriptions using a combination of semantic and lexical similarity. Trained with contrastive learning, SemSup-XC significantly outperforms baselines and establishes state-of-the-art performance on all three datasets considered, gaining up to 12 precision points on zero-shot and more than 10 precision points on one-shot tests, with similar gains for recall@10. Our ablation studies highlight the relative importance of our hybrid matching module and automatically collected class descriptions.
SPARTAN: Sparse Hierarchical Memory for Parameter-Efficient Transformers
Nov 29, 2022



Fine-tuning pre-trained language models (PLMs) achieves impressive performance on a range of downstream tasks, and their sizes have consequently been getting bigger. Since a different copy of the model is required for each task, this paradigm is infeasible for storage-constrained edge devices like mobile phones. In this paper, we propose SPARTAN, a parameter efficient (PE) and computationally fast architecture for edge devices that adds hierarchically organized sparse memory after each Transformer layer. SPARTAN freezes the PLM parameters and fine-tunes only its memory, thus significantly reducing storage costs by re-using the PLM backbone for different tasks. SPARTAN contains two levels of memory, with only a sparse subset of parents being chosen in the first level for each input, and children cells corresponding to those parents being used to compute an output representation. This sparsity combined with other architecture optimizations improves SPARTAN's throughput by over 90% during inference on a Raspberry Pi 4 when compared to PE baselines (adapters) while also outperforming the latter by 0.1 points on the GLUE benchmark. Further, it can be trained 34% faster in a few-shot setting, while performing within 0.9 points of adapters. Qualitative analysis shows that different parent cells in SPARTAN specialize in different topics, thus dividing responsibility efficiently.
ALIGN-MLM: Word Embedding Alignment is Crucial for Multilingual Pre-training
Nov 15, 2022Multilingual pre-trained models exhibit zero-shot cross-lingual transfer, where a model fine-tuned on a source language achieves surprisingly good performance on a target language. While studies have attempted to understand transfer, they focus only on MLM, and the large number of differences between natural languages makes it hard to disentangle the importance of different properties. In this work, we specifically highlight the importance of word embedding alignment by proposing a pre-training objective (ALIGN-MLM) whose auxiliary loss guides similar words in different languages to have similar word embeddings. ALIGN-MLM either outperforms or matches three widely adopted objectives (MLM, XLM, DICT-MLM) when we evaluate transfer between pairs of natural languages and their counterparts created by systematically modifying specific properties like the script. In particular, ALIGN-MLM outperforms XLM and MLM by 35 and 30 F1 points on POS-tagging for transfer between languages that differ both in their script and word order (left-to-right v.s. right-to-left). We also show a strong correlation between alignment and transfer for all objectives (e.g., rho=0.727 for XNLI), which together with ALIGN-MLM's strong performance calls for explicitly aligning word embeddings for multilingual models.
Semantic Supervision: Enabling Generalization over Output Spaces
Mar 15, 2022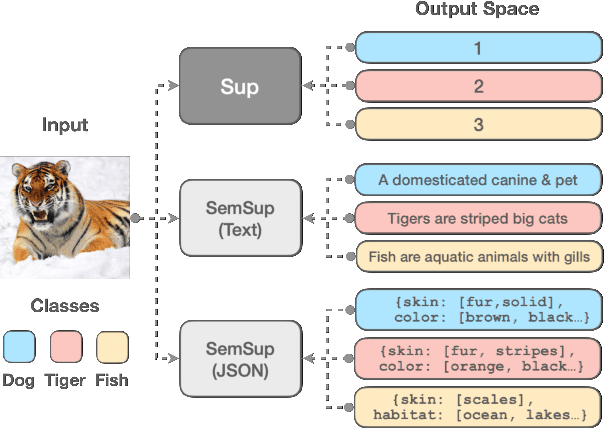
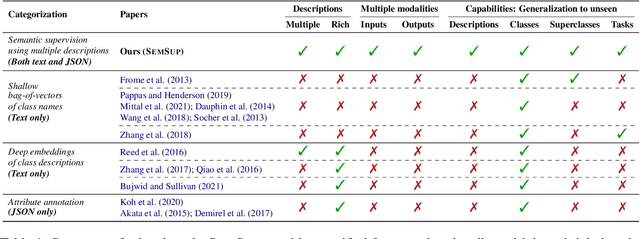
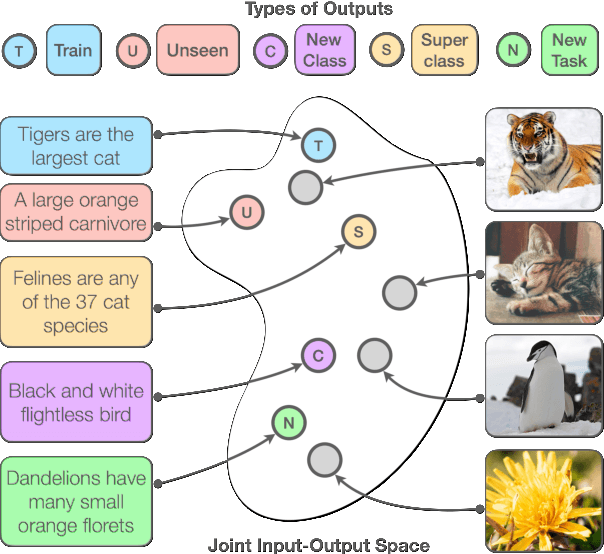
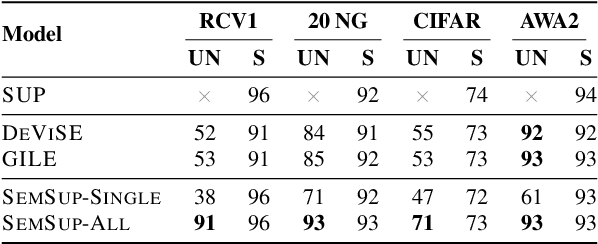
In this paper, we propose Semantic Supervision (SemSup) - a unified paradigm for training classifiers that generalize over output spaces. In contrast to standard classification, which treats classes as discrete symbols, SemSup represents them as dense vector features obtained from descriptions of classes (e.g., "The cat is a small carnivorous mammal"). This allows the output space to be unbounded (in the space of descriptions) and enables models to generalize both over unseen inputs and unseen outputs (e.g. "The aardvark is a nocturnal burrowing mammal with long ears"). Specifically, SemSup enables four types of generalization, to -- (1) unseen class descriptions, (2) unseen classes, (3) unseen super-classes, and (4) unseen tasks. Through experiments on four classification datasets across two variants (multi-class and multi-label), two input modalities (text and images), and two output description modalities (text and JSON), we show that our SemSup models significantly outperform standard supervised models and existing models that leverage word embeddings over class names. For instance, our model outperforms baselines by 40% and 15% precision points on unseen descriptions and classes, respectively, on a news categorization dataset (RCV1). SemSup can serve as a pathway for scaling neural models to large unbounded output spaces and enabling better generalization and model reuse for unseen tasks and domains.
When is BERT Multilingual? Isolating Crucial Ingredients for Cross-lingual Transfer
Nov 05, 2021
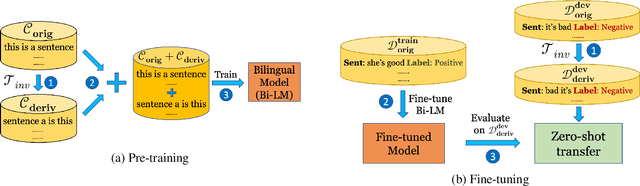

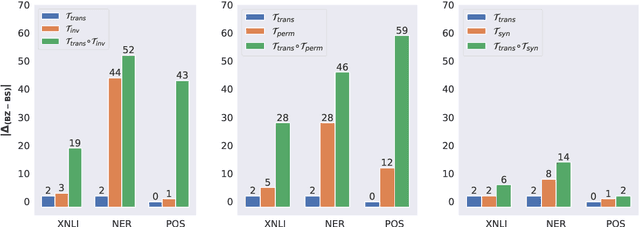
While recent work on multilingual language models has demonstrated their capacity for cross-lingual zero-shot transfer on downstream tasks, there is a lack of consensus in the community as to what shared properties between languages enable such transfer. Analyses involving pairs of natural languages are often inconclusive and contradictory since languages simultaneously differ in many linguistic aspects. In this paper, we perform a large-scale empirical study to isolate the effects of various linguistic properties by measuring zero-shot transfer between four diverse natural languages and their counterparts constructed by modifying aspects such as the script, word order, and syntax. Among other things, our experiments show that the absence of sub-word overlap significantly affects zero-shot transfer when languages differ in their word order, and there is a strong correlation between transfer performance and word embedding alignment between languages (e.g., R=0.94 on the task of NLI). Our results call for focus in multilingual models on explicitly improving word embedding alignment between languages rather than relying on its implicit emergence.
Guiding Attention for Self-Supervised Learning with Transformers
Oct 06, 2020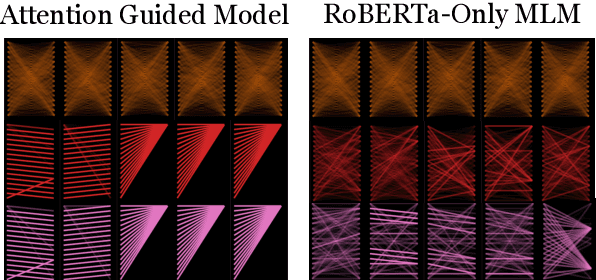
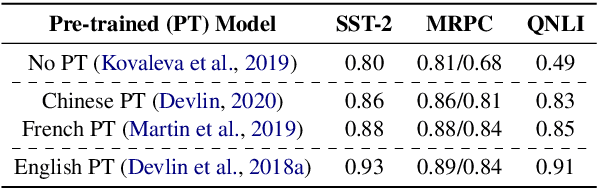
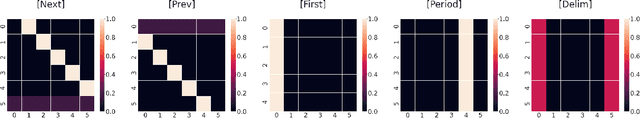
In this paper, we propose a simple and effective technique to allow for efficient self-supervised learning with bi-directional Transformers. Our approach is motivated by recent studies demonstrating that self-attention patterns in trained models contain a majority of non-linguistic regularities. We propose a computationally efficient auxiliary loss function to guide attention heads to conform to such patterns. Our method is agnostic to the actual pre-training objective and results in faster convergence of models as well as better performance on downstream tasks compared to the baselines, achieving state of the art results in low-resource settings. Surprisingly, we also find that linguistic properties of attention heads are not necessarily correlated with language modeling performance.