 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEvolving Latent Space Model for Dynamic Networks
Feb 11, 2018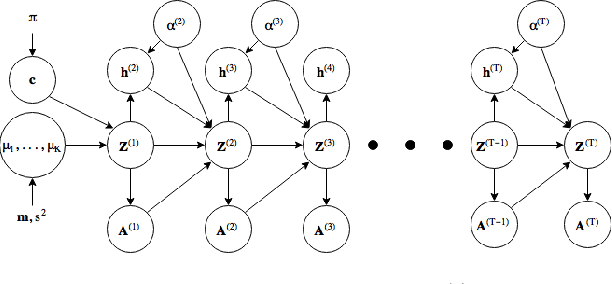
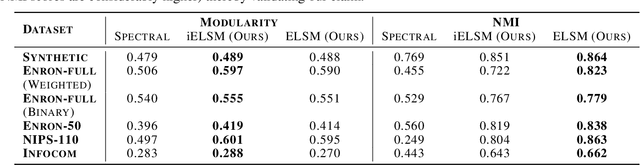
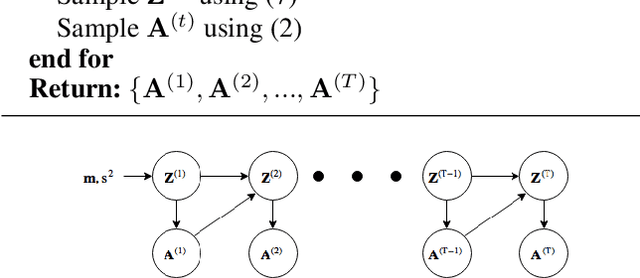
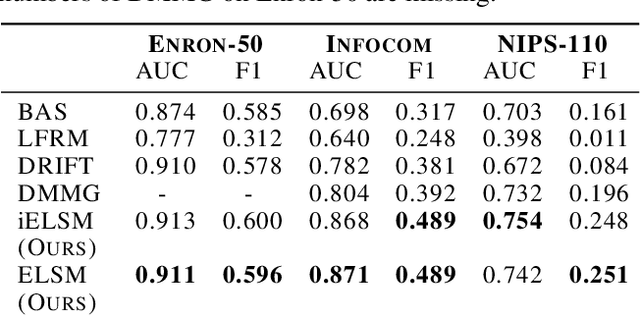
Networks observed in the real world like social networks, collaboration networks etc., exhibit temporal dynamics, i.e. nodes and edges appear and/or disappear over time. In this paper, we propose a generative, latent space based, statistical model for such networks (called dynamic networks). We consider the case where the number of nodes is fixed, but the presence of edges can vary over time. Our model allows the number of communities in the network to be different at different time steps. We use a neural network based methodology to perform approximate inference in the proposed model and its simplified version. Experiments done on synthetic and real-world networks for the task of community detection and link prediction demonstrate the utility and effectiveness of our model as compared to other similar existing approaches. To the best of our knowledge, this is the first work that integrates statistical modeling of dynamic networks with deep learning for community detection and link prediction.
Attentive Recurrent Comparators
Jun 30, 2017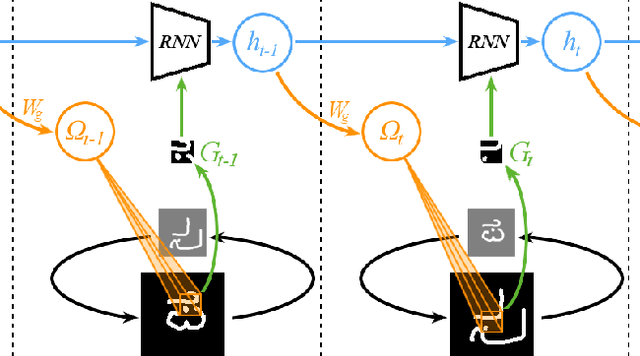
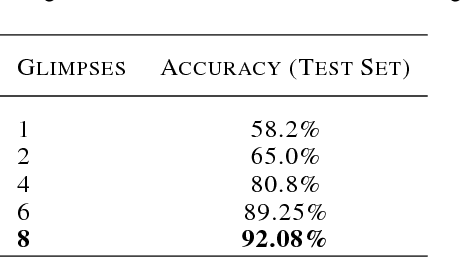


Rapid learning requires flexible representations to quickly adopt to new evidence. We develop a novel class of models called Attentive Recurrent Comparators (ARCs) that form representations of objects by cycling through them and making observations. Using the representations extracted by ARCs, we develop a way of approximating a \textit{dynamic representation space} and use it for one-shot learning. In the task of one-shot classification on the Omniglot dataset, we achieve the state of the art performance with an error rate of 1.5\%. This represents the first super-human result achieved for this task with a generic model that uses only pixel information.
Uniform Hypergraph Partitioning: Provable Tensor Methods and Sampling Techniques
May 17, 2017
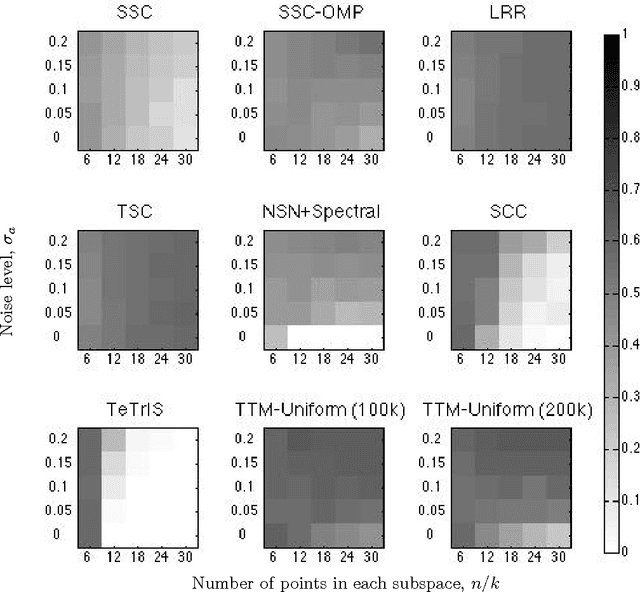
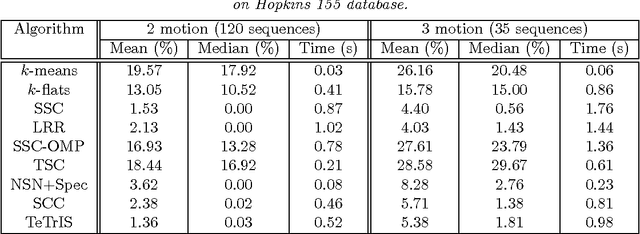
In a series of recent works, we have generalised the consistency results in the stochastic block model literature to the case of uniform and non-uniform hypergraphs. The present paper continues the same line of study, where we focus on partitioning weighted uniform hypergraphs---a problem often encountered in computer vision. This work is motivated by two issues that arise when a hypergraph partitioning approach is used to tackle computer vision problems: (i) The uniform hypergraphs constructed for higher-order learning contain all edges, but most have negligible weights. Thus, the adjacency tensor is nearly sparse, and yet, not binary. (ii) A more serious concern is that standard partitioning algorithms need to compute all edge weights, which is computationally expensive for hypergraphs. This is usually resolved in practice by merging the clustering algorithm with a tensor sampling strategy---an approach that is yet to be analysed rigorously. We build on our earlier work on partitioning dense unweighted uniform hypergraphs (Ghoshdastidar and Dukkipati, ICML, 2015), and address the aforementioned issues by proposing provable and efficient partitioning algorithms. Our analysis justifies the empirical success of practical sampling techniques. We also complement our theoretical findings by elaborate empirical comparison of various hypergraph partitioning schemes.
Amortized Inference and Learning in Latent Conditional Random Fields for Weakly-Supervised Semantic Image Segmentation
May 03, 2017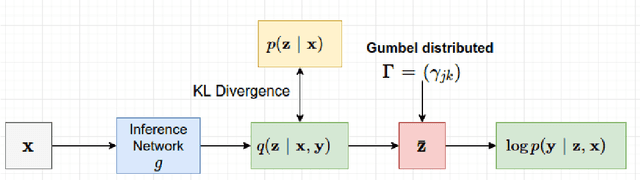
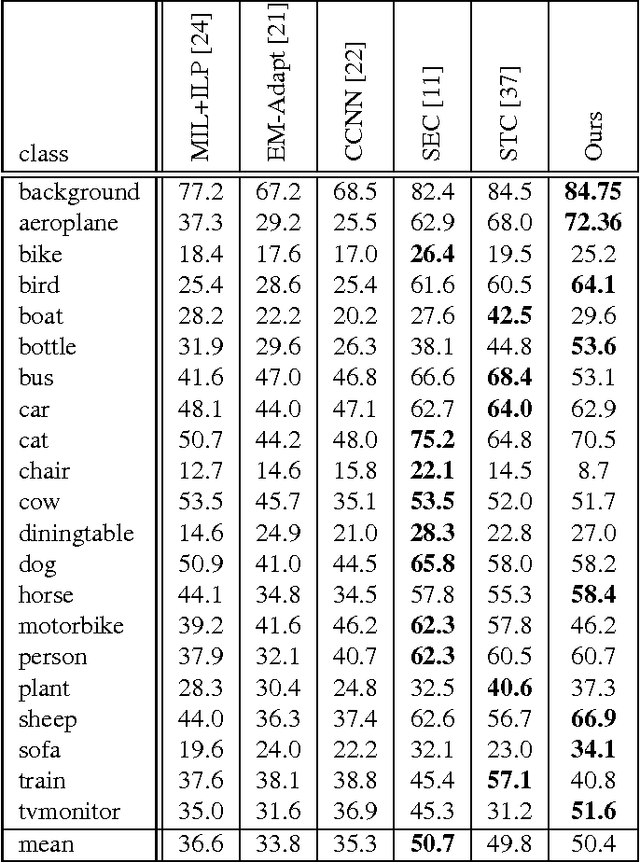
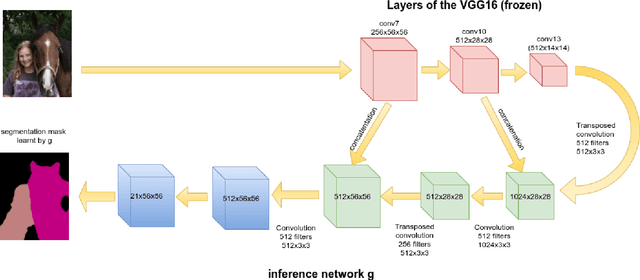

Conditional random fields (CRFs) are commonly employed as a post-processing tool for image segmentation tasks. The unary potentials of the CRF are often learnt independently by a classifier, thereby decoupling the inference in CRF from the training of classifier. Such a scheme works effectively, when pixel-level labelling is available for all the images. However, in absence of pixel-level labels, the classifier is faced with the uphill task of selectively assigning the image-level labels to the pixels of the image. Prior work often relied on localization cues, such as saliency maps, objectness priors, bounding boxes etc., to address this challenging problem. In contrast, we model the labels of the pixels as latent variables of a CRF. The pixels and the image-level labels are the observed variables of the latent CRF. We amortize the cost of inference in the latent CRF over the entire dataset, by training an inference network to approximate the posterior distribution of the latent variables given the observed variables. The inference network can be trained in an end-to-end fashion, and requires no localization cues for training. Moreover, unlike other approaches for weakly-supervised segmentation, the proposed model doesn't require further post-processing. The proposed model achieves performance comparable with other approaches that employ saliency masks for the task of weakly-supervised semantic image segmentation on the challenging VOC 2012 dataset.
Generative Adversarial Residual Pairwise Networks for One Shot Learning
Mar 23, 2017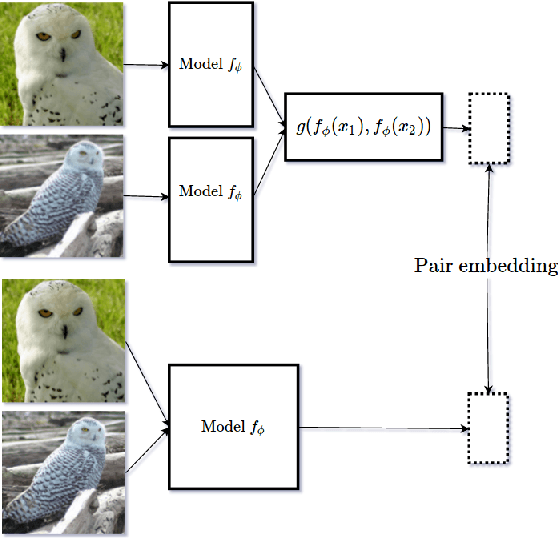
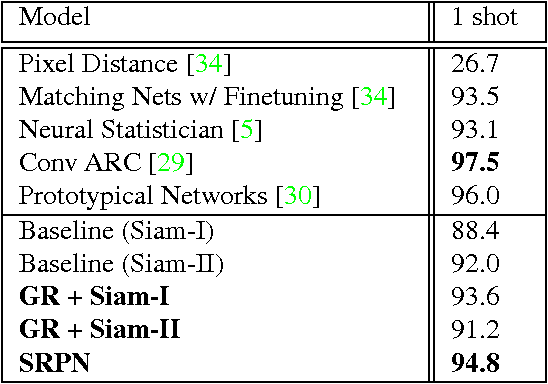
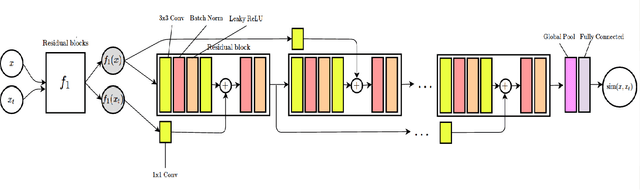
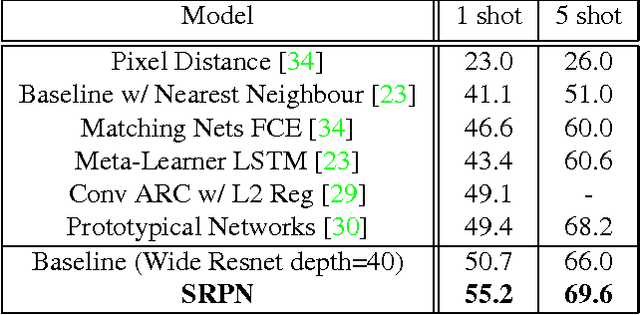
Deep neural networks achieve unprecedented performance levels over many tasks and scale well with large quantities of data, but performance in the low-data regime and tasks like one shot learning still lags behind. While recent work suggests many hypotheses from better optimization to more complicated network structures, in this work we hypothesize that having a learnable and more expressive similarity objective is an essential missing component. Towards overcoming that, we propose a network design inspired by deep residual networks that allows the efficient computation of this more expressive pairwise similarity objective. Further, we argue that regularization is key in learning with small amounts of data, and propose an additional generator network based on the Generative Adversarial Networks where the discriminator is our residual pairwise network. This provides a strong regularizer by leveraging the generated data samples. The proposed model can generate plausible variations of exemplars over unseen classes and outperforms strong discriminative baselines for few shot classification tasks. Notably, our residual pairwise network design outperforms previous state-of-theart on the challenging mini-Imagenet dataset for one shot learning by getting over 55% accuracy for the 5-way classification task over unseen classes.
Discriminative Neural Topic Models
Feb 28, 2017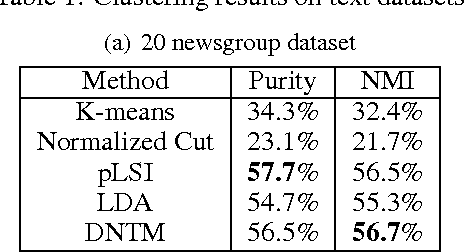


We propose a neural network based approach for learning topics from text and image datasets. The model makes no assumptions about the conditional distribution of the observed features given the latent topics. This allows us to perform topic modelling efficiently using sentences of documents and patches of images as observed features, rather than limiting ourselves to words. Moreover, the proposed approach is online, and hence can be used for streaming data. Furthermore, since the approach utilizes neural networks, it can be implemented on GPU with ease, and hence it is very scalable.
A Neural Architecture Mimicking Humans End-to-End for Natural Language Inference
Jan 27, 2017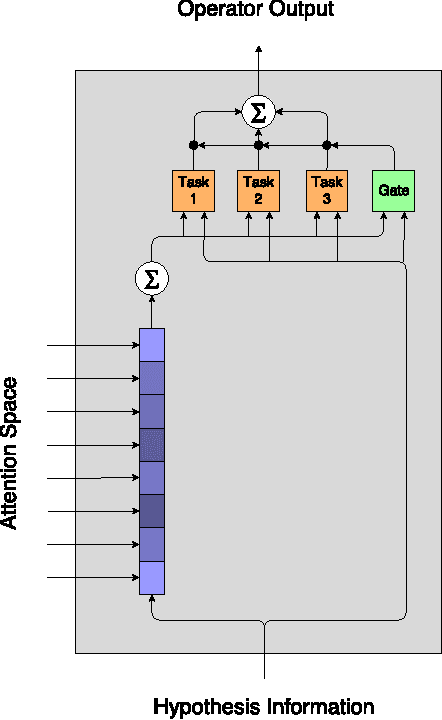
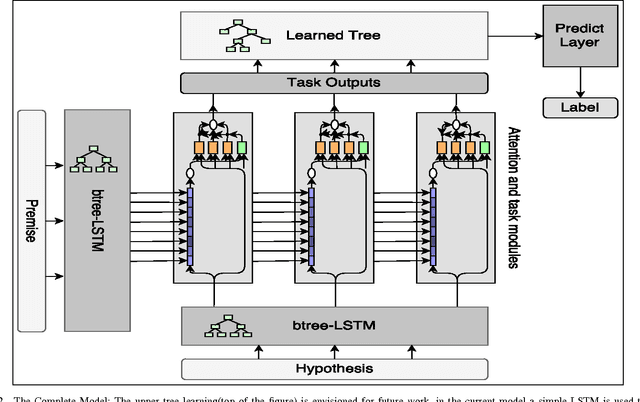

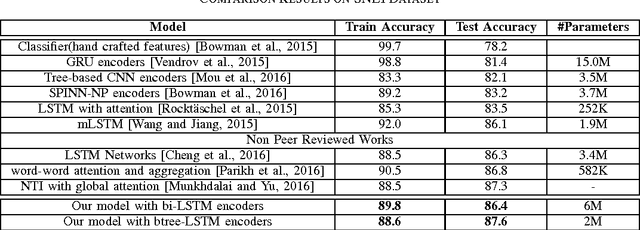
In this work we use the recent advances in representation learning to propose a neural architecture for the problem of natural language inference. Our approach is aligned to mimic how a human does the natural language inference process given two statements. The model uses variants of Long Short Term Memory (LSTM), attention mechanism and composable neural networks, to carry out the task. Each part of our model can be mapped to a clear functionality humans do for carrying out the overall task of natural language inference. The model is end-to-end differentiable enabling training by stochastic gradient descent. On Stanford Natural Language Inference(SNLI) dataset, the proposed model achieves better accuracy numbers than all published models in literature.
Image Generation and Editing with Variational Info Generative AdversarialNetworks
Jan 17, 2017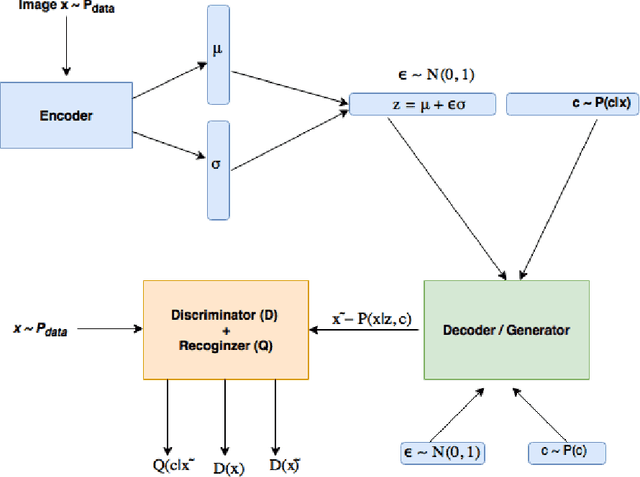

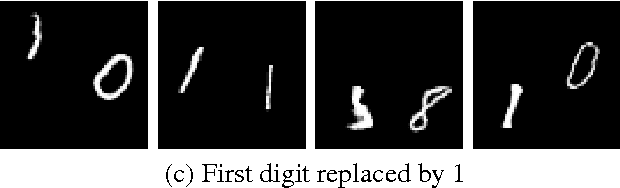
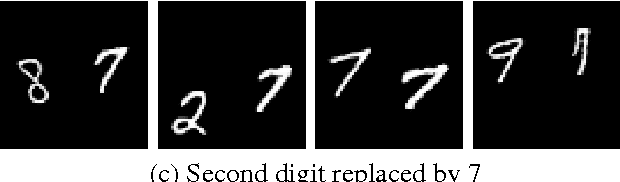
Recently there has been an enormous interest in generative models for images in deep learning. In pursuit of this, Generative Adversarial Networks (GAN) and Variational Auto-Encoder (VAE) have surfaced as two most prominent and popular models. While VAEs tend to produce excellent reconstructions but blurry samples, GANs generate sharp but slightly distorted images. In this paper we propose a new model called Variational InfoGAN (ViGAN). Our aim is two fold: (i) To generated new images conditioned on visual descriptions, and (ii) modify the image, by fixing the latent representation of image and varying the visual description. We evaluate our model on Labeled Faces in the Wild (LFW), celebA and a modified version of MNIST datasets and demonstrate the ability of our model to generate new images as well as to modify a given image by changing attributes.
Deep Variational Inference Without Pixel-Wise Reconstruction
Nov 16, 2016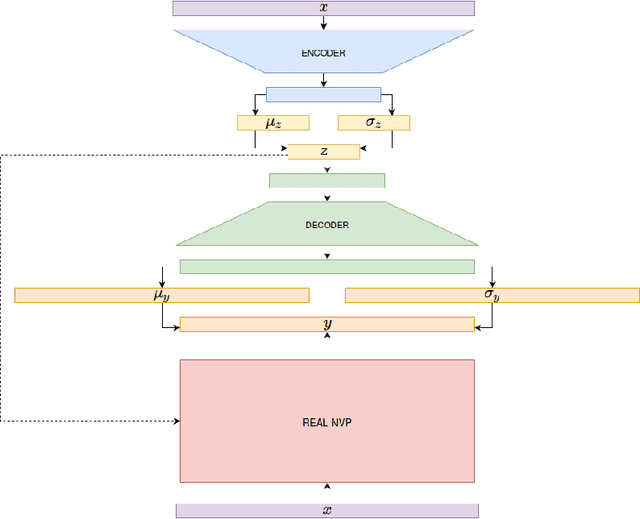
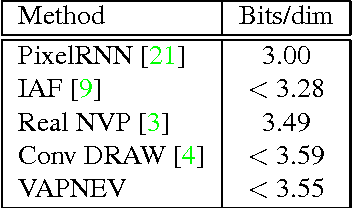
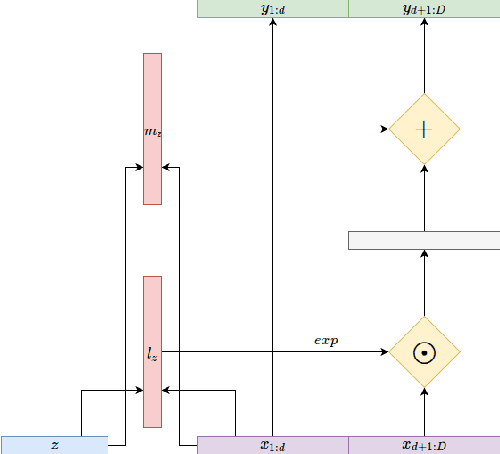
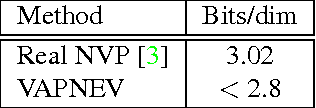
Variational autoencoders (VAEs), that are built upon deep neural networks have emerged as popular generative models in computer vision. Most of the work towards improving variational autoencoders has focused mainly on making the approximations to the posterior flexible and accurate, leading to tremendous progress. However, there have been limited efforts to replace pixel-wise reconstruction, which have known shortcomings. In this work, we use real-valued non-volume preserving transformations (real NVP) to exactly compute the conditional likelihood of the data given the latent distribution. We show that a simple VAE with this form of reconstruction is competitive with complicated VAE structures, on image modeling tasks. As part of our model, we develop powerful conditional coupling layers that enable real NVP to learn with fewer intermediate layers.
Variational methods for Conditional Multimodal Deep Learning
Aug 26, 2016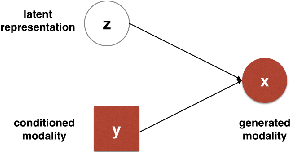


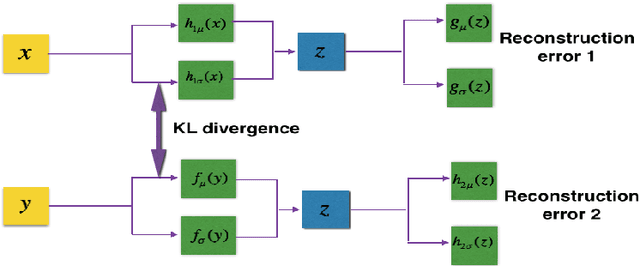
In this paper, we address the problem of conditional modality learning, whereby one is interested in generating one modality given the other. While it is straightforward to learn a joint distribution over multiple modalities using a deep multimodal architecture, we observe that such models aren't very effective at conditional generation. Hence, we address the problem by learning conditional distributions between the modalities. We use variational methods for maximizing the corresponding conditional log-likelihood. The resultant deep model, which we refer to as conditional multimodal autoencoder (CMMA), forces the latent representation obtained from a single modality alone to be `close' to the joint representation obtained from multiple modalities. We use the proposed model to generate faces from attributes. We show that the faces generated from attributes using the proposed model, are qualitatively and quantitatively more representative of the attributes from which they were generated, than those obtained by other deep generative models. We also propose a secondary task, whereby the existing faces are modified by modifying the corresponding attributes. We observe that the modifications in face introduced by the proposed model are representative of the corresponding modifications in attributes.