 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGeometry-Aware Texture Generation for 3D Head Modeling with Artist-driven Control
May 07, 2025Creating realistic 3D head assets for virtual characters that match a precise artistic vision remains labor-intensive. We present a novel framework that streamlines this process by providing artists with intuitive control over generated 3D heads. Our approach uses a geometry-aware texture synthesis pipeline that learns correlations between head geometry and skin texture maps across different demographics. The framework offers three levels of artistic control: manipulation of overall head geometry, adjustment of skin tone while preserving facial characteristics, and fine-grained editing of details such as wrinkles or facial hair. Our pipeline allows artists to make edits to a single texture map using familiar tools, with our system automatically propagating these changes coherently across the remaining texture maps needed for realistic rendering. Experiments demonstrate that our method produces diverse results with clean geometries. We showcase practical applications focusing on intuitive control for artists, including skin tone adjustments and simplified editing workflows for adding age-related details or removing unwanted features from scanned models. This integrated approach aims to streamline the artistic workflow in virtual character creation.
Optimizing Correlated Graspability Score and Grasp Regression for Better Grasp Prediction
Feb 03, 2020
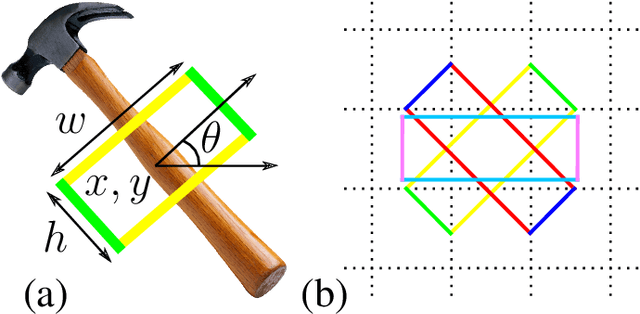
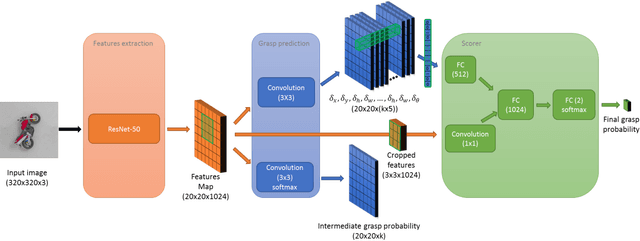
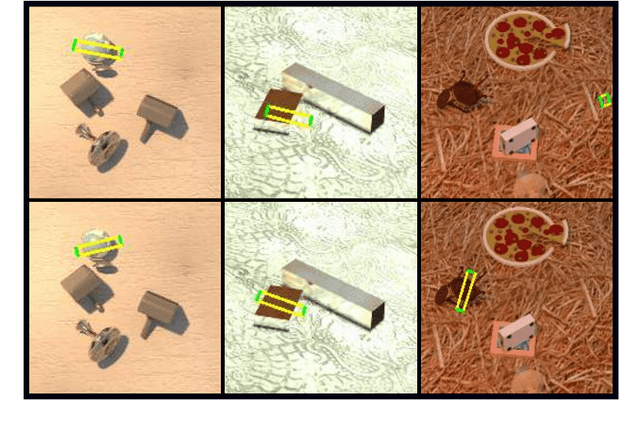
Grasping objects is one of the most important abilities to master for a robot in order to interact with its environment. Current state-of-the-art methods rely on deep neural networks trained to predict a graspability score jointly but separately from regression of an offset of grasp reference parameters, although the predicted offset could decrease the graspability score. In this paper, we extend a state-of-the-art neural network with a scorer which evaluates the graspability of a given position and introduce a novel loss function which correlates regression of grasp parameters with graspability score. We show that this novel architecture improves the performance from 81.95% for a state-of-the-art grasp detection network to 85.74% on Jacquard dataset. Because real-life applications generally feature scenes of multiple objects laid on a variable decor, we also introduce Jacquard+, a test-only extension of Jacquard dataset. Its role is to complete the traditional real robot evaluation by benchmarking the adaptability of a learned grasp prediction model on a different data distribution than the training one while remaining in totally reproducible conditions. Using this novel benchmark and evaluated through the Simulated Grasp Trial criterion, our proposed model outperforms a state-of-the-art one by 7 points.
Developmental Bayesian Optimization of Black-Box with Visual Similarity-Based Transfer Learning
Oct 19, 2018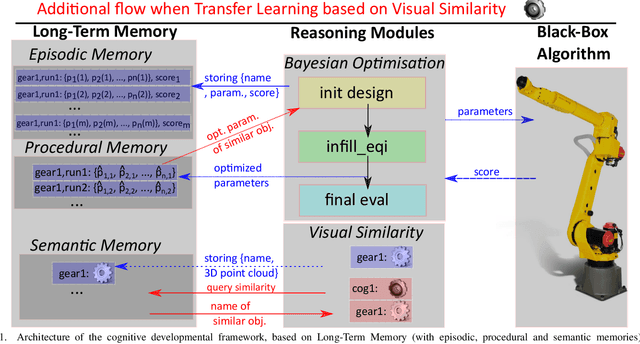
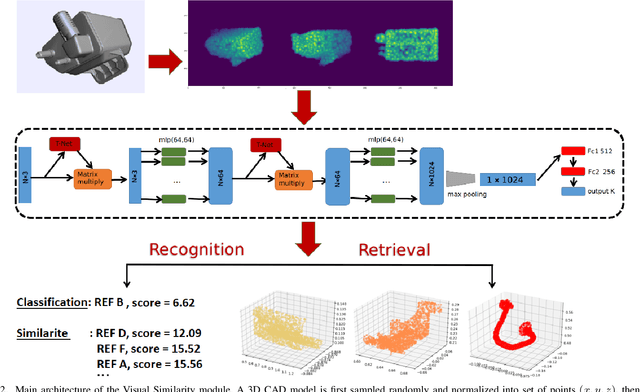

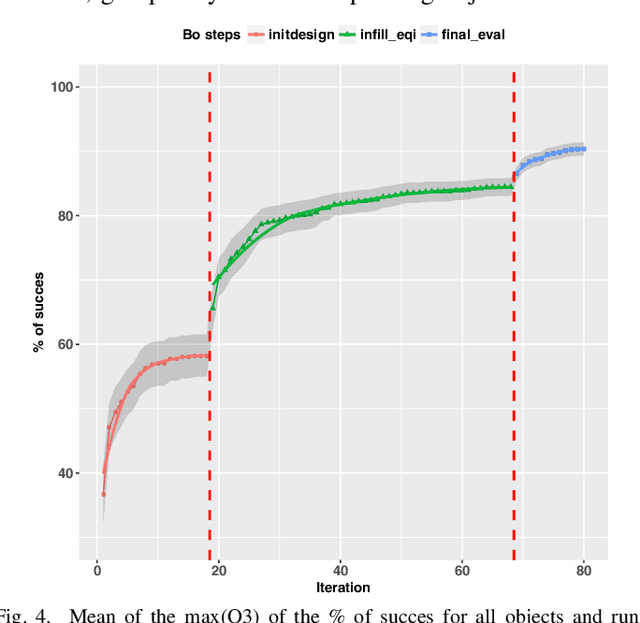
We present a developmental framework based on a long-term memory and reasoning mechanisms (Vision Similarity and Bayesian Optimisation). This architecture allows a robot to optimize autonomously hyper-parameters that need to be tuned from any action and/or vision module, treated as a black-box. The learning can take advantage of past experiences (stored in the episodic and procedural memories) in order to warm-start the exploration using a set of hyper-parameters previously optimized from objects similar to the new unknown one (stored in a semantic memory). As example, the system has been used to optimized 9 continuous hyper-parameters of a professional software (Kamido) both in simulation and with a real robot (industrial robotic arm Fanuc) with a total of 13 different objects. The robot is able to find a good object-specific optimization in 68 (simulation) or 40 (real) trials. In simulation, we demonstrate the benefit of the transfer learning based on visual similarity, as opposed to an amnesic learning (i.e. learning from scratch all the time). Moreover, with the real robot, we show that the method consistently outperforms the manual optimization from an expert with less than 2 hours of training time to achieve more than 88% of success.
Jacquard: A Large Scale Dataset for Robotic Grasp Detection
Sep 28, 2018
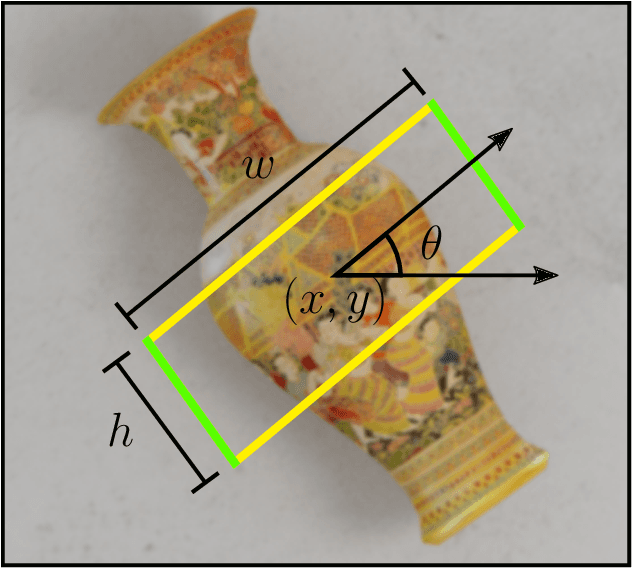
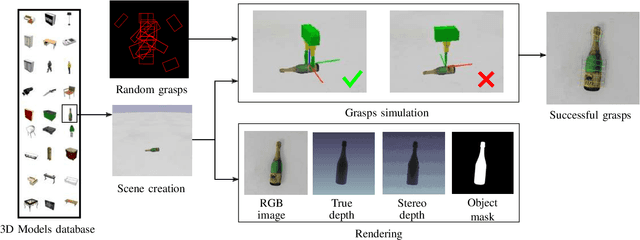

Grasping skill is a major ability that a wide number of real-life applications require for robotisation. State-of-the-art robotic grasping methods perform prediction of object grasp locations based on deep neural networks. However, such networks require huge amount of labeled data for training making this approach often impracticable in robotics. In this paper, we propose a method to generate a large scale synthetic dataset with ground truth, which we refer to as the Jacquard grasping dataset. Jacquard is built on a subset of ShapeNet, a large CAD models dataset, and contains both RGB-D images and annotations of successful grasping positions based on grasp attempts performed in a simulated environment. We carried out experiments using an off-the-shelf CNN, with three different evaluation metrics, including real grasping robot trials. The results show that Jacquard enables much better generalization skills than a human labeled dataset thanks to its diversity of objects and grasping positions. For the purpose of reproducible research in robotics, we are releasing along with the Jacquard dataset a web interface for researchers to evaluate the successfulness of their grasping position detections using our dataset.