 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVoxtral
Jul 17, 2025We present Voxtral Mini and Voxtral Small, two multimodal audio chat models. Voxtral is trained to comprehend both spoken audio and text documents, achieving state-of-the-art performance across a diverse range of audio benchmarks, while preserving strong text capabilities. Voxtral Small outperforms a number of closed-source models, while being small enough to run locally. A 32K context window enables the model to handle audio files up to 40 minutes in duration and long multi-turn conversations. We also contribute three benchmarks for evaluating speech understanding models on knowledge and trivia. Both Voxtral models are released under Apache 2.0 license.
Magistral
Jun 12, 2025



We introduce Magistral, Mistral's first reasoning model and our own scalable reinforcement learning (RL) pipeline. Instead of relying on existing implementations and RL traces distilled from prior models, we follow a ground up approach, relying solely on our own models and infrastructure. Notably, we demonstrate a stack that enabled us to explore the limits of pure RL training of LLMs, present a simple method to force the reasoning language of the model, and show that RL on text data alone maintains most of the initial checkpoint's capabilities. We find that RL on text maintains or improves multimodal understanding, instruction following and function calling. We present Magistral Medium, trained for reasoning on top of Mistral Medium 3 with RL alone, and we open-source Magistral Small (Apache 2.0) which further includes cold-start data from Magistral Medium.
CAp 2017 challenge: Twitter Named Entity Recognition
Jul 24, 2017
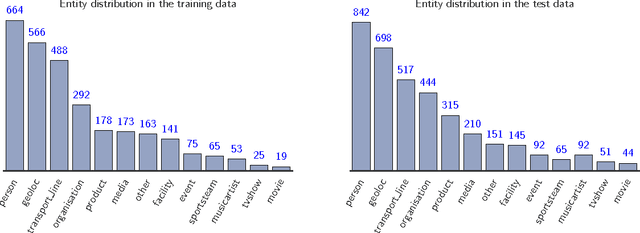
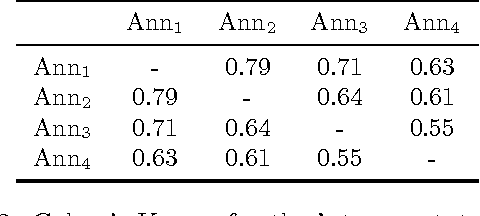
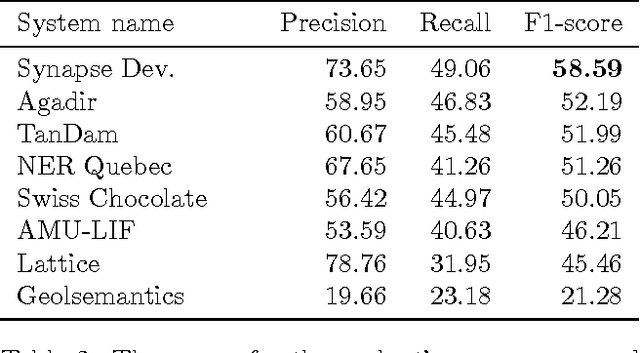
The paper describes the CAp 2017 challenge. The challenge concerns the problem of Named Entity Recognition (NER) for tweets written in French. We first present the data preparation steps we followed for constructing the dataset released in the framework of the challenge. We begin by demonstrating why NER for tweets is a challenging problem especially when the number of entities increases. We detail the annotation process and the necessary decisions we made. We provide statistics on the inter-annotator agreement, and we conclude the data description part with examples and statistics for the data. We, then, describe the participation in the challenge, where 8 teams participated, with a focus on the methods employed by the challenge participants and the scores achieved in terms of F$_1$ measure. Importantly, the constructed dataset comprising $\sim$6,000 tweets annotated for 13 types of entities, which to the best of our knowledge is the first such dataset in French, is publicly available at \url{http://cap2017.imag.fr/competition.html} .