 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSoK: Facial Deepfake Detectors
Jan 09, 2024



Deepfakes have rapidly emerged as a profound and serious threat to society, primarily due to their ease of creation and dissemination. This situation has triggered an accelerated development of deepfake detection technologies. However, many existing detectors rely heavily on lab-generated datasets for validation, which may not effectively prepare them for novel, emerging, and real-world deepfake techniques. In this paper, we conduct an extensive and comprehensive review and analysis of the latest state-of-the-art deepfake detectors, evaluating them against several critical criteria. These criteria facilitate the categorization of these detectors into 4 high-level groups and 13 fine-grained sub-groups, all aligned with a unified standard conceptual framework. This classification and framework offer deep and practical insights into the factors that affect detector efficacy. We assess the generalizability of 16 leading detectors across various standard attack scenarios, including black-box, white-box, and gray-box settings. Our systematized analysis and experimentation lay the groundwork for a deeper understanding of deepfake detectors and their generalizability, paving the way for future research focused on creating detectors adept at countering various attack scenarios. Additionally, this work offers insights for developing more proactive defenses against deepfakes.
Deepfake in the Metaverse: Security Implications for Virtual Gaming, Meetings, and Offices
Mar 26, 2023
The metaverse has gained significant attention from various industries due to its potential to create a fully immersive and interactive virtual world. However, the integration of deepfakes in the metaverse brings serious security implications, particularly with regard to impersonation. This paper examines the security implications of deepfakes in the metaverse, specifically in the context of gaming, online meetings, and virtual offices. The paper discusses how deepfakes can be used to impersonate in gaming scenarios, how online meetings in the metaverse open the door for impersonation, and how virtual offices in the metaverse lack physical authentication, making it easier for attackers to impersonate someone. The implications of these security concerns are discussed in relation to the confidentiality, integrity, and availability (CIA) triad. The paper further explores related issues such as the darkverse, and digital cloning, as well as regulatory and privacy concerns associated with addressing security threats in the virtual world.
Cybersecurity Challenges of Power Transformers
Feb 25, 2023



The rise of cyber threats on critical infrastructure and its potential for devastating consequences, has significantly increased. The dependency of new power grid technology on information, data analytic and communication systems make the entire electricity network vulnerable to cyber threats. Power transformers play a critical role within the power grid and are now commonly enhanced through factory add-ons or intelligent monitoring systems added later to improve the condition monitoring of critical and long lead time assets such as transformers. However, the increased connectivity of those power transformers opens the door to more cyber attacks. Therefore, the need to detect and prevent cyber threats is becoming critical. The first step towards that would be a deeper understanding of the potential cyber-attacks landscape against power transformers. Much of the existing literature pays attention to smart equipment within electricity distribution networks, and most methods proposed are based on model-based detection algorithms. Moreover, only a few of these works address the security vulnerabilities of power elements, especially transformers within the transmission network. To the best of our knowledge, there is no study in the literature that systematically investigate the cybersecurity challenges against the newly emerged smart transformers. This paper addresses this shortcoming by exploring the vulnerabilities and the attack vectors of power transformers within electricity networks, the possible attack scenarios and the risks associated with these attacks.
Why Do Deepfake Detectors Fail?
Feb 25, 2023



Recent rapid advancements in deepfake technology have allowed the creation of highly realistic fake media, such as video, image, and audio. These materials pose significant challenges to human authentication, such as impersonation, misinformation, or even a threat to national security. To keep pace with these rapid advancements, several deepfake detection algorithms have been proposed, leading to an ongoing arms race between deepfake creators and deepfake detectors. Nevertheless, these detectors are often unreliable and frequently fail to detect deepfakes. This study highlights the challenges they face in detecting deepfakes, including (1) the pre-processing pipeline of artifacts and (2) the fact that generators of new, unseen deepfake samples have not been considered when building the defense models. Our work sheds light on the need for further research and development in this field to create more robust and reliable detectors.
Tracking Dataset IP Use in Deep Neural Networks
Nov 24, 2022



Training highly performant deep neural networks (DNNs) typically requires the collection of a massive dataset and the use of powerful computing resources. Therefore, unauthorized redistribution of private pre-trained DNNs may cause severe economic loss for model owners. For protecting the ownership of DNN models, DNN watermarking schemes have been proposed by embedding secret information in a DNN model and verifying its presence for model ownership. However, existing DNN watermarking schemes compromise the model utility and are vulnerable to watermark removal attacks because a model is modified with a watermark. Alternatively, a new approach dubbed DEEPJUDGE was introduced to measure the similarity between a suspect model and a victim model without modifying the victim model. However, DEEPJUDGE would only be designed to detect the case where a suspect model's architecture is the same as a victim model's. In this work, we propose a novel DNN fingerprinting technique dubbed DEEPTASTER to prevent a new attack scenario in which a victim's data is stolen to build a suspect model. DEEPTASTER can effectively detect such data theft attacks even when a suspect model's architecture differs from a victim model's. To achieve this goal, DEEPTASTER generates a few adversarial images with perturbations, transforms them into the Fourier frequency domain, and uses the transformed images to identify the dataset used in a suspect model. The intuition is that those adversarial images can be used to capture the characteristics of DNNs built on a specific dataset. We evaluated the detection accuracy of DEEPTASTER on three datasets with three model architectures under various attack scenarios, including transfer learning, pruning, fine-tuning, and data augmentation. Overall, DEEPTASTER achieves a balanced accuracy of 94.95%, which is significantly better than 61.11% achieved by DEEPJUDGE in the same settings.
MACAB: Model-Agnostic Clean-Annotation Backdoor to Object Detection with Natural Trigger in Real-World
Sep 06, 2022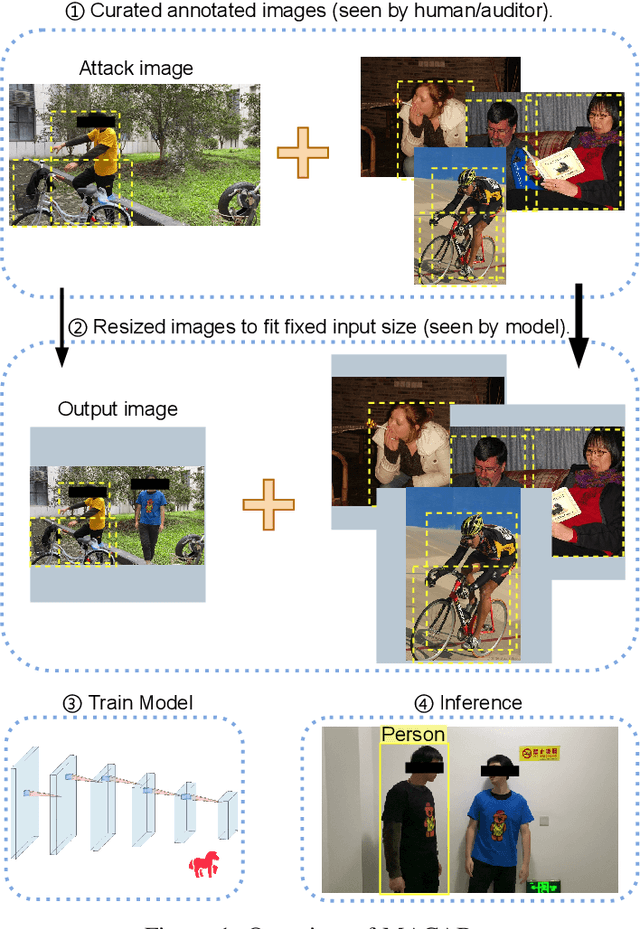
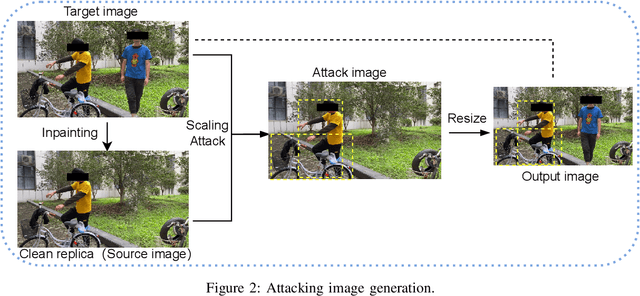


Object detection is the foundation of various critical computer-vision tasks such as segmentation, object tracking, and event detection. To train an object detector with satisfactory accuracy, a large amount of data is required. However, due to the intensive workforce involved with annotating large datasets, such a data curation task is often outsourced to a third party or relied on volunteers. This work reveals severe vulnerabilities of such data curation pipeline. We propose MACAB that crafts clean-annotated images to stealthily implant the backdoor into the object detectors trained on them even when the data curator can manually audit the images. We observe that the backdoor effect of both misclassification and the cloaking are robustly achieved in the wild when the backdoor is activated with inconspicuously natural physical triggers. Backdooring non-classification object detection with clean-annotation is challenging compared to backdooring existing image classification tasks with clean-label, owing to the complexity of having multiple objects within each frame, including victim and non-victim objects. The efficacy of the MACAB is ensured by constructively i abusing the image-scaling function used by the deep learning framework, ii incorporating the proposed adversarial clean image replica technique, and iii combining poison data selection criteria given constrained attacking budget. Extensive experiments demonstrate that MACAB exhibits more than 90% attack success rate under various real-world scenes. This includes both cloaking and misclassification backdoor effect even restricted with a small attack budget. The poisoned samples cannot be effectively identified by state-of-the-art detection techniques.The comprehensive video demo is at https://youtu.be/MA7L_LpXkp4, which is based on a poison rate of 0.14% for YOLOv4 cloaking backdoor and Faster R-CNN misclassification backdoor.
PhishClone: Measuring the Efficacy of Cloning Evasion Attacks
Sep 04, 2022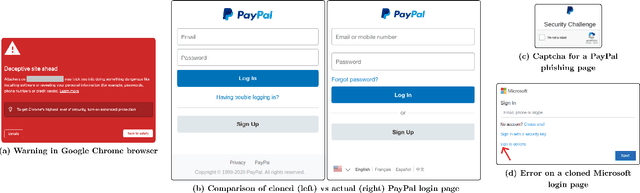
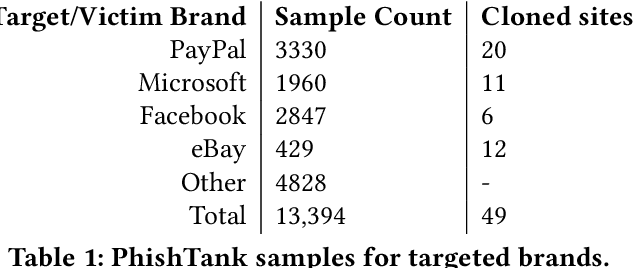
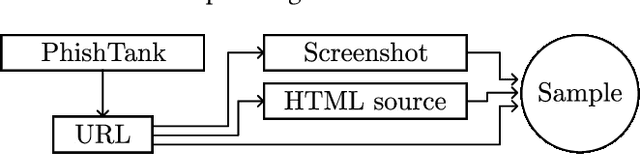

Web-based phishing accounts for over 90% of data breaches, and most web-browsers and security vendors rely on machine-learning (ML) models as mitigation. Despite this, links posted regularly on anti-phishing aggregators such as PhishTank and VirusTotal are shown to easily bypass existing detectors. Prior art suggests that automated website cloning, with light mutations, is gaining traction with attackers. This has limited exposure in current literature and leads to sub-optimal ML-based countermeasures. The work herein conducts the first empirical study that compiles and evaluates a variety of state-of-the-art cloning techniques in wide circulation. We collected 13,394 samples and found 8,566 confirmed phishing pages targeting 4 popular websites using 7 distinct cloning mechanisms. These samples were replicated with malicious code removed within a controlled platform fortified with precautions that prevent accidental access. We then reported our sites to VirusTotal and other platforms, with regular polling of results for 7 days, to ascertain the efficacy of each cloning technique. Results show that no security vendor detected our clones, proving the urgent need for more effective detectors. Finally, we posit 4 recommendations to aid web developers and ML-based defences to alleviate the risks of cloning attacks.
Profiler: Profile-Based Model to Detect Phishing Emails
Aug 18, 2022
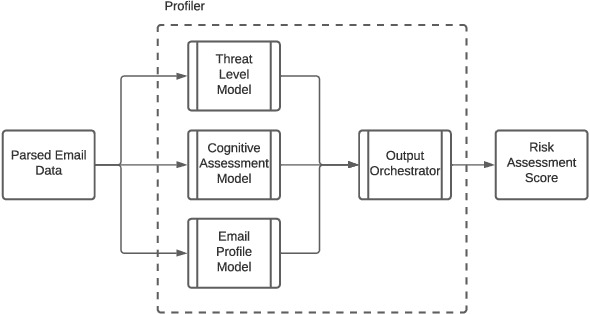
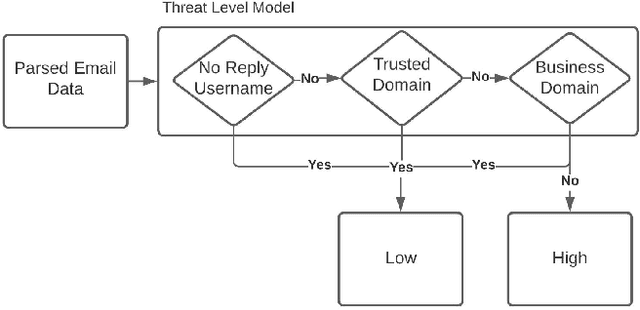
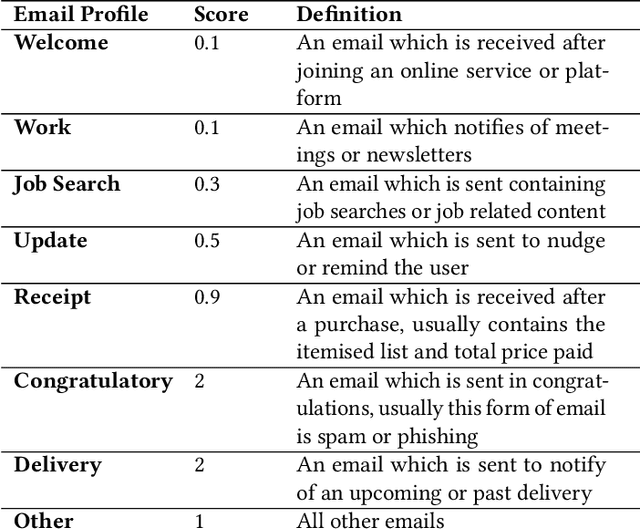
Email phishing has become more prevalent and grows more sophisticated over time. To combat this rise, many machine learning (ML) algorithms for detecting phishing emails have been developed. However, due to the limited email data sets on which these algorithms train, they are not adept at recognising varied attacks and, thus, suffer from concept drift; attackers can introduce small changes in the statistical characteristics of their emails or websites to successfully bypass detection. Over time, a gap develops between the reported accuracy from literature and the algorithm's actual effectiveness in the real world. This realises itself in frequent false positive and false negative classifications. To this end, we propose a multidimensional risk assessment of emails to reduce the feasibility of an attacker adapting their email and avoiding detection. This horizontal approach to email phishing detection profiles an incoming email on its main features. We develop a risk assessment framework that includes three models which analyse an email's (1) threat level, (2) cognitive manipulation, and (3) email type, which we combine to return the final risk assessment score. The Profiler does not require large data sets to train on to be effective and its analysis of varied email features reduces the impact of concept drift. Our Profiler can be used in conjunction with ML approaches, to reduce their misclassifications or as a labeller for large email data sets in the training stage. We evaluate the efficacy of the Profiler against a machine learning ensemble using state-of-the-art ML algorithms on a data set of 9000 legitimate and 900 phishing emails from a large Australian research organisation. Our results indicate that the Profiler's mitigates the impact of concept drift, and delivers 30% less false positive and 25% less false negative email classifications over the ML ensemble's approach.
* 12 pages
Binarizing Split Learning for Data Privacy Enhancement and Computation Reduction
Jun 10, 2022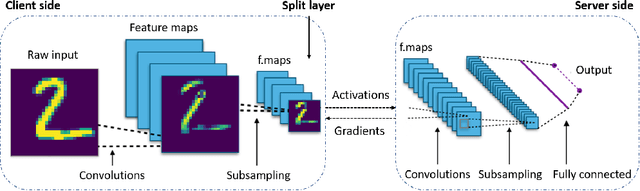
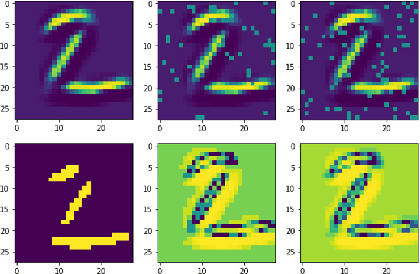
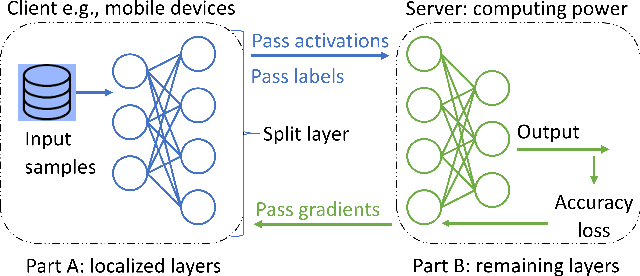
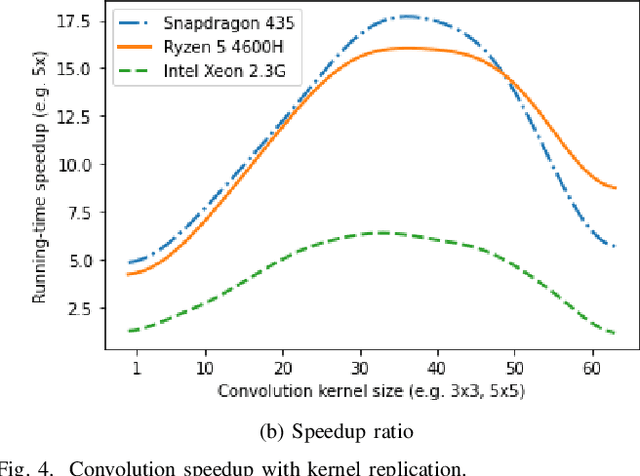
Split learning (SL) enables data privacy preservation by allowing clients to collaboratively train a deep learning model with the server without sharing raw data. However, SL still has limitations such as potential data privacy leakage and high computation at clients. In this study, we propose to binarize the SL local layers for faster computation (up to 17.5 times less forward-propagation time in both training and inference phases on mobile devices) and reduced memory usage (up to 32 times less memory and bandwidth requirements). More importantly, the binarized SL (B-SL) model can reduce privacy leakage from SL smashed data with merely a small degradation in model accuracy. To further enhance the privacy preservation, we also propose two novel approaches: 1) training with additional local leak loss and 2) applying differential privacy, which could be integrated separately or concurrently into the B-SL model. Experimental results with different datasets have affirmed the advantages of the B-SL models compared with several benchmark models. The effectiveness of B-SL models against feature-space hijacking attack (FSHA) is also illustrated. Our results have demonstrated B-SL models are promising for lightweight IoT/mobile applications with high privacy-preservation requirements such as mobile healthcare applications.
Towards A Critical Evaluation of Robustness for Deep Learning Backdoor Countermeasures
Apr 13, 2022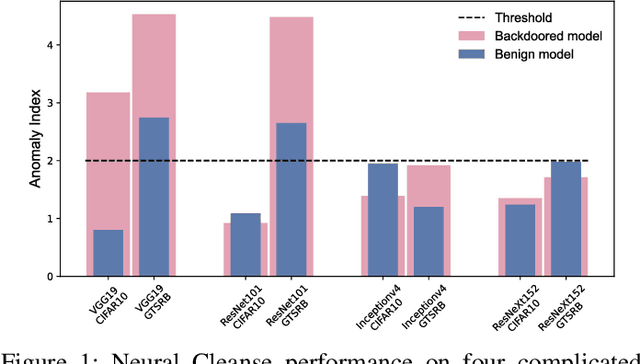
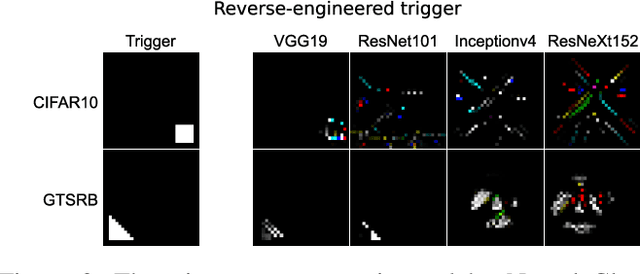
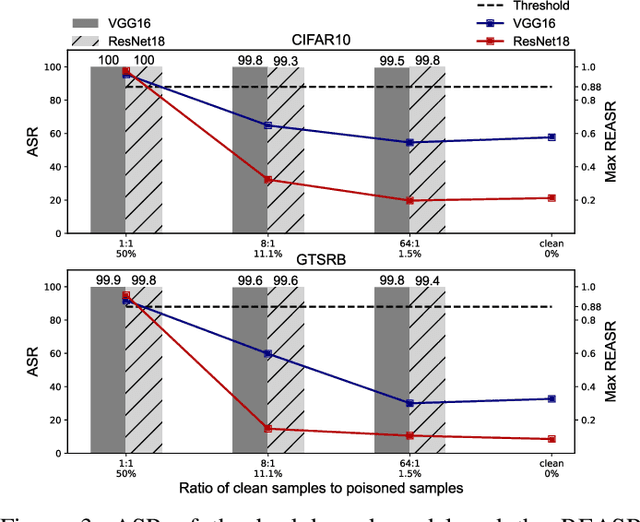

Since Deep Learning (DL) backdoor attacks have been revealed as one of the most insidious adversarial attacks, a number of countermeasures have been developed with certain assumptions defined in their respective threat models. However, the robustness of these countermeasures is inadvertently ignored, which can introduce severe consequences, e.g., a countermeasure can be misused and result in a false implication of backdoor detection. For the first time, we critically examine the robustness of existing backdoor countermeasures with an initial focus on three influential model-inspection ones that are Neural Cleanse (S&P'19), ABS (CCS'19), and MNTD (S&P'21). Although the three countermeasures claim that they work well under their respective threat models, they have inherent unexplored non-robust cases depending on factors such as given tasks, model architectures, datasets, and defense hyper-parameter, which are \textit{not even rooted from delicate adaptive attacks}. We demonstrate how to trivially bypass them aligned with their respective threat models by simply varying aforementioned factors. Particularly, for each defense, formal proofs or empirical studies are used to reveal its two non-robust cases where it is not as robust as it claims or expects, especially the recent MNTD. This work highlights the necessity of thoroughly evaluating the robustness of backdoor countermeasures to avoid their misleading security implications in unknown non-robust cases.