 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti Modal Attention Networks with Uncertainty Quantification for Automated Concrete Bridge Deck Delamination Detection
Dec 23, 2025



Deteriorating civil infrastructure requires automated inspection techniques overcoming limitations of visual assessment. While Ground Penetrating Radar and Infrared Thermography enable subsurface defect detection, single modal approaches face complementary constraints radar struggles with moisture and shallow defects, while thermography exhibits weather dependency and limited depth. This paper presents a multi modal attention network fusing radar temporal patterns with thermal spatial signatures for bridge deck delamination detection. Our architecture introduces temporal attention for radar processing, spatial attention for thermal features, and cross modal fusion with learnable embeddings discovering complementary defect patterns invisible to individual sensors. We incorporate uncertainty quantification through Monte Carlo dropout and learned variance estimation, decomposing uncertainty into epistemic and aleatoric components for safety critical decisions. Experiments on five bridge datasets reveal that on balanced to moderately imbalanced data, our approach substantially outperforms baselines in accuracy and AUC representing meaningful improvements over single modal and concatenation based fusion. Ablation studies demonstrate cross modal attention provides critical gains beyond within modality attention, while multi head mechanisms achieve improved calibration. Uncertainty quantification reduces calibration error, enabling selective prediction by rejecting uncertain cases. However, under extreme class imbalance, attention mechanisms show vulnerability to majority class collapse. These findings provide actionable guidance: attention based architecture performs well across typical scenarios, while extreme imbalance requires specialized techniques. Our system maintains deployment efficiency, enabling real time inspection with characterized capabilities and limitations.
Dual Model Deep Learning for Alzheimer Prognostication
Dec 22, 2025



Disease modifying therapies for Alzheimer's disease demand precise timing decisions, yet current predictive models require longitudinal observations and provide no uncertainty quantification, rendering them impractical at the critical first visit when treatment decisions must be made. We developed PROGRESS (PRognostic Generalization from REsting Static Signatures), a dual-model deep learning framework that transforms a single baseline cerebrospinal fluid biomarker assessment into actionable prognostic estimates without requiring prior clinical history. The framework addresses two complementary clinical questions: a probabilistic trajectory network predicts individualized cognitive decline with calibrated uncertainty bounds achieving near-nominal coverage, enabling honest prognostic communication; and a deep survival model estimates time to conversion from mild cognitive impairment to dementia. Using data from over 3,000 participants across 43 Alzheimer's Disease Research Centers in the National Alzheimer's Coordinating Center database, PROGRESS substantially outperforms Cox proportional hazards, Random Survival Forests, and gradient boosting methods for survival prediction. Risk stratification identifies patient groups with seven-fold differences in conversion rates, enabling clinically meaningful treatment prioritization. Leave-one-center-out validation demonstrates robust generalizability, with survival discrimination remaining strong across held-out sites despite heterogeneous measurement conditions spanning four decades of assay technologies. By combining superior survival prediction with trustworthy trajectory uncertainty quantification, PROGRESS bridges the gap between biomarker measurement and personalized clinical decision-making.
Alzheimer's Disease Brain Network Mining
Dec 19, 2025Machine learning approaches for Alzheimer's disease (AD) diagnosis face a fundamental challenges. Clinical assessments are expensive and invasive, leaving ground truth labels available for only a fraction of neuroimaging datasets. We introduce Multi view Adaptive Transport Clustering for Heterogeneous Alzheimer's Disease (MATCH-AD), a semi supervised framework that integrates deep representation learning, graph-based label propagation, and optimal transport theory to address this limitation. The framework leverages manifold structure in neuroimaging data to propagate diagnostic information from limited labeled samples to larger unlabeled populations, while using Wasserstein distances to quantify disease progression between cognitive states. Evaluated on nearly five thousand subjects from the National Alzheimer's Coordinating Center, encompassing structural MRI measurements from hundreds of brain regions, cerebrospinal fluid biomarkers, and clinical variables MATCHAD achieves near-perfect diagnostic accuracy despite ground truth labels for less than one-third of subjects. The framework substantially outperforms all baseline methods, achieving kappa indicating almost perfect agreement compared to weak agreement for the best baseline, a qualitative transformation in diagnostic reliability. Performance remains clinically useful even under severe label scarcity, and we provide theoretical convergence guarantees with proven bounds on label propagation error and transport stability. These results demonstrate that principled semi-supervised learning can unlock the diagnostic potential of the vast repositories of partially annotated neuroimaging data accumulating worldwide, substantially reducing annotation burden while maintaining accuracy suitable for clinical deployment.
Bridging Training and Merging Through Momentum-Aware Optimization
Dec 18, 2025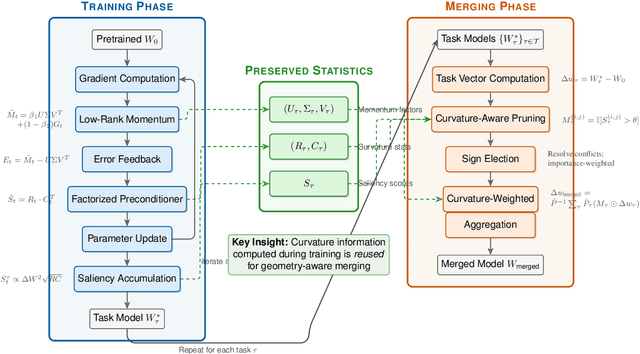
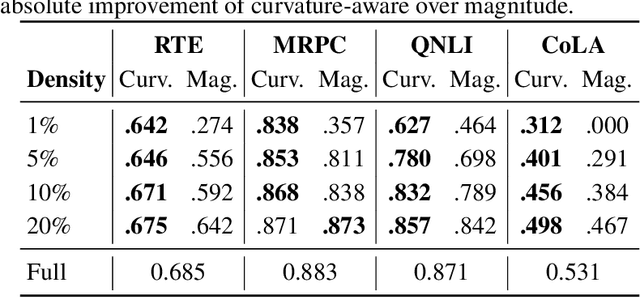
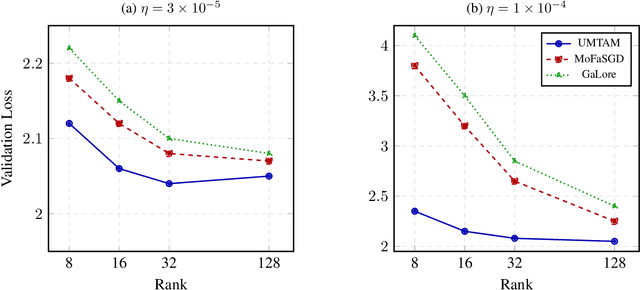
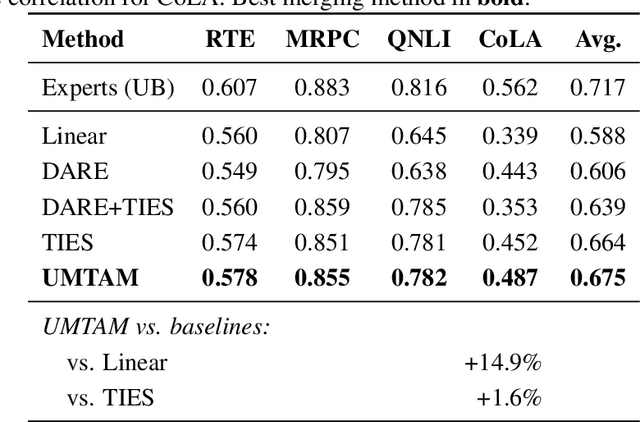
Training large neural networks and merging task-specific models both exploit low-rank structure and require parameter importance estimation, yet these challenges have been pursued in isolation. Current workflows compute curvature information during training, discard it, then recompute similar information for merging -- wasting computation and discarding valuable trajectory data. We introduce a unified framework that maintains factorized momentum and curvature statistics during training, then reuses this information for geometry-aware model composition. The proposed method achieves memory efficiency comparable to state-of-the-art approaches while accumulating task saliency scores that enable curvature-aware merging without post-hoc Fisher computation. We establish convergence guarantees for non-convex objectives with approximation error bounded by gradient singular value decay. On natural language understanding benchmarks, curvature-aware parameter selection outperforms magnitude-only baselines across all sparsity levels, with multi-task merging improving over strong baselines. The proposed framework exhibits rank-invariant convergence and superior hyperparameter robustness compared to existing low-rank optimizers. By treating the optimization trajectory as a reusable asset rather than discarding it, our approach eliminates redundant computation while enabling more principled model composition.