 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHow Well Does GPT-4o Understand Vision? Evaluating Multimodal Foundation Models on Standard Computer Vision Tasks
Jul 02, 2025Multimodal foundation models, such as GPT-4o, have recently made remarkable progress, but it is not clear where exactly these models stand in terms of understanding vision. In this paper, we benchmark the performance of popular multimodal foundation models (GPT-4o, o4-mini, Gemini 1.5 Pro and Gemini 2.0 Flash, Claude 3.5 Sonnet, Qwen2-VL, Llama 3.2) on standard computer vision tasks (semantic segmentation, object detection, image classification, depth and surface normal prediction) using established datasets (e.g., COCO, ImageNet and its variants, etc). The main challenges to performing this are: 1) most models are trained to output text and cannot natively express versatile domains, such as segments or 3D geometry, and 2) many leading models are proprietary and accessible only at an API level, i.e., there is no weight access to adapt them. We address these challenges by translating standard vision tasks into equivalent text-promptable and API-compatible tasks via prompt chaining to create a standardized benchmarking framework. We observe that 1) the models are not close to the state-of-the-art specialist models at any task. However, 2) they are respectable generalists; this is remarkable as they are presumably trained on primarily image-text-based tasks. 3) They perform semantic tasks notably better than geometric ones. 4) While the prompt-chaining techniques affect performance, better models exhibit less sensitivity to prompt variations. 5) GPT-4o performs the best among non-reasoning models, securing the top position in 4 out of 6 tasks, 6) reasoning models, e.g. o3, show improvements in geometric tasks, and 7) a preliminary analysis of models with native image generation, like the latest GPT-4o, shows they exhibit quirks like hallucinations and spatial misalignments.
4M-21: An Any-to-Any Vision Model for Tens of Tasks and Modalities
Jun 14, 2024



Current multimodal and multitask foundation models like 4M or UnifiedIO show promising results, but in practice their out-of-the-box abilities to accept diverse inputs and perform diverse tasks are limited by the (usually rather small) number of modalities and tasks they are trained on. In this paper, we expand upon the capabilities of them by training a single model on tens of highly diverse modalities and by performing co-training on large-scale multimodal datasets and text corpora. This includes training on several semantic and geometric modalities, feature maps from recent state of the art models like DINOv2 and ImageBind, pseudo labels of specialist models like SAM and 4DHumans, and a range of new modalities that allow for novel ways to interact with the model and steer the generation, for example image metadata or color palettes. A crucial step in this process is performing discrete tokenization on various modalities, whether they are image-like, neural network feature maps, vectors, structured data like instance segmentation or human poses, or data that can be represented as text. Through this, we expand on the out-of-the-box capabilities of multimodal models and specifically show the possibility of training one model to solve at least 3x more tasks/modalities than existing ones and doing so without a loss in performance. This enables more fine-grained and controllable multimodal generation capabilities and allows us to study the distillation of models trained on diverse data and objectives into a unified model. We successfully scale the training to a three billion parameter model using tens of modalities and different datasets. The resulting models and training code are open sourced at 4m.epfl.ch.
InForecaster: Forecasting Influenza Hemagglutinin Mutations Through the Lens of Anomaly Detection
Oct 25, 2022The influenza virus hemagglutinin is an important part of the virus attachment to the host cells. The hemagglutinin proteins are one of the genetic regions of the virus with a high potential for mutations. Due to the importance of predicting mutations in producing effective and low-cost vaccines, solutions that attempt to approach this problem have recently gained a significant attention. A historical record of mutations have been used to train predictive models in such solutions. However, the imbalance between mutations and the preserved proteins is a big challenge for the development of such models that needs to be addressed. Here, we propose to tackle this challenge through anomaly detection (AD). AD is a well-established field in Machine Learning (ML) that tries to distinguish unseen anomalies from the normal patterns using only normal training samples. By considering mutations as the anomalous behavior, we could benefit existing rich solutions in this field that have emerged recently. Such methods also fit the problem setup of extreme imbalance between the number of unmutated vs. mutated training samples. Motivated by this formulation, our method tries to find a compact representation for unmutated samples while forcing anomalies to be separated from the normal ones. This helps the model to learn a shared unique representation between normal training samples as much as possible, which improves the discernibility and detectability of mutated samples from the unmutated ones at the test time. We conduct a large number of experiments on four publicly available datasets, consisting of 3 different hemagglutinin protein datasets, and one SARS-CoV-2 dataset, and show the effectiveness of our method through different standard criteria.
Neural Distributed Image Compression with Cross-Attention Feature Alignment
Jul 18, 2022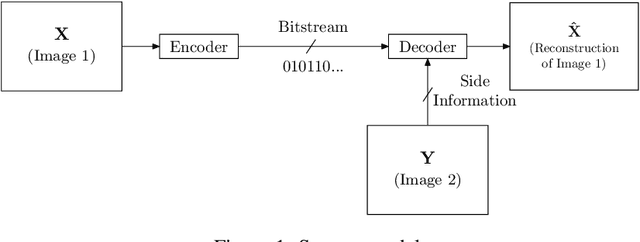
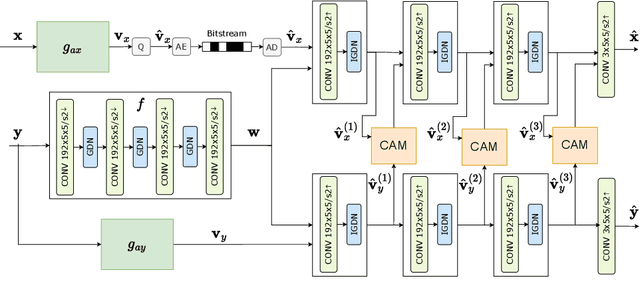
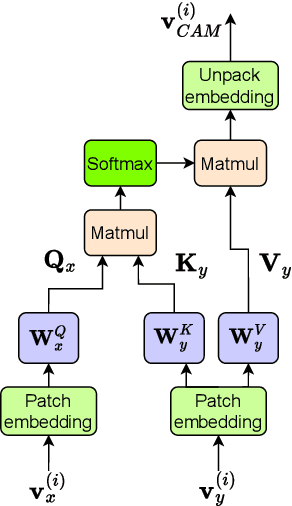
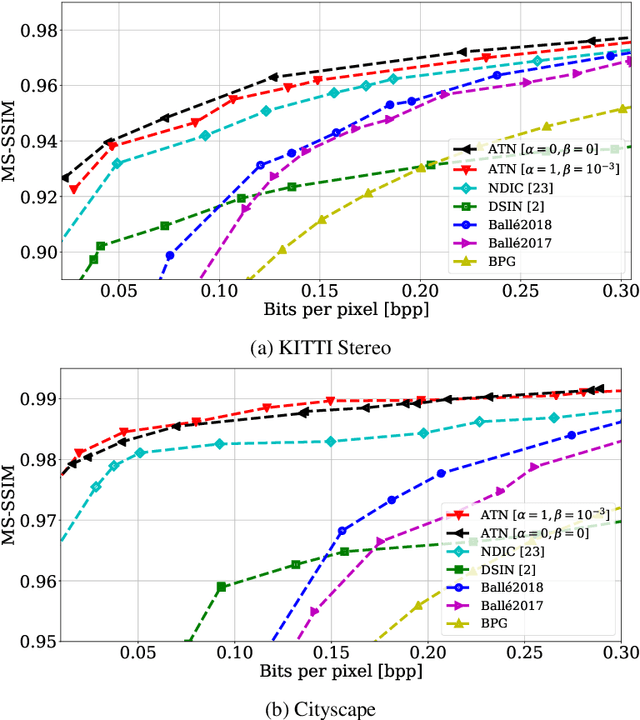
We propose a novel deep neural network (DNN) architecture for compressing an image when a correlated image is available as side information only at the decoder side, a special case of the well-known and heavily studied distributed source coding (DSC) problem. In particular, we consider a pair of stereo images, which have overlapping fields of view, captured by a synchronized and calibrated pair of cameras; and therefore, are highly correlated. We assume that one image of the pair is to be compressed and transmitted, while the other image is available only at the decoder. In the proposed architecture, the encoder maps the input image to a latent space using a DNN, quantizes the latent representation, and compresses it losslessly using entropy coding. The proposed decoder extracts useful information common between the images solely from the available side information, as well as a latent representation of the side information. Then, the latent representations of the two images, one received from the encoder, the other extracted locally, along with the locally generated common information, are fed to the respective decoders of the two images. We employ a cross-attention module (CAM) to align the feature maps obtained in the intermediate layers of the respective decoders of the two images, thus allowing better utilization of the side information. We train and demonstrate the effectiveness of the proposed algorithm on various realistic setups, such as KITTI and Cityscape datasets of stereo image pairs. Our results show that the proposed architecture is capable of exploiting the decoder-only side information in a more efficient manner as it outperforms previous works. We also show that the proposed method is able to provide significant gains even in the case of uncalibrated and unsynchronized camera array use cases.
Deep Stereo Image Compression with Decoder Side Information using Wyner Common Information
Jun 22, 2021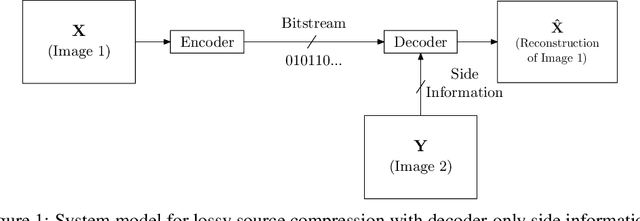
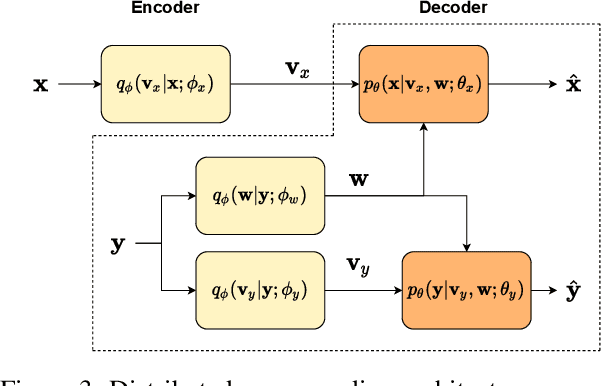
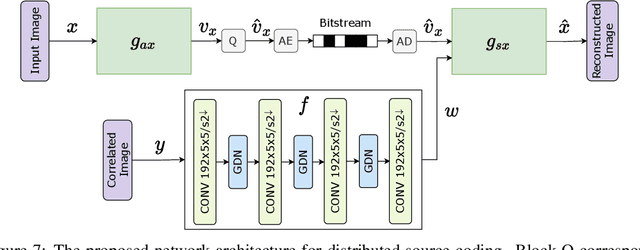
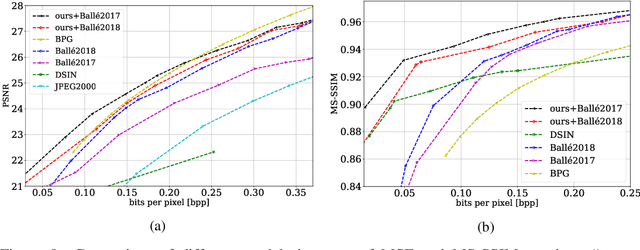
We present a novel deep neural network (DNN) architecture for compressing an image when a correlated image is available as side information only at the decoder. This problem is known as distributed source coding (DSC) in information theory. In particular, we consider a pair of stereo images, which generally have high correlation with each other due to overlapping fields of view, and assume that one image of the pair is to be compressed and transmitted, while the other image is available only at the decoder. In the proposed architecture, the encoder maps the input image to a latent space, quantizes the latent representation, and compresses it using entropy coding. The decoder is trained to extract the Wyner's common information between the input image and the correlated image from the latter. The received latent representation and the locally generated common information are passed through a decoder network to obtain an enhanced reconstruction of the input image. The common information provides a succinct representation of the relevant information at the receiver. We train and demonstrate the effectiveness of the proposed approach on the KITTI dataset of stereo image pairs. Our results show that the proposed architecture is capable of exploiting the decoder-only side information, and outperforms previous work on stereo image compression with decoder side information.