 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEgoTransfer: Transferring Motion Across Egocentric and Exocentric Domains using Deep Neural Networks
Dec 17, 2016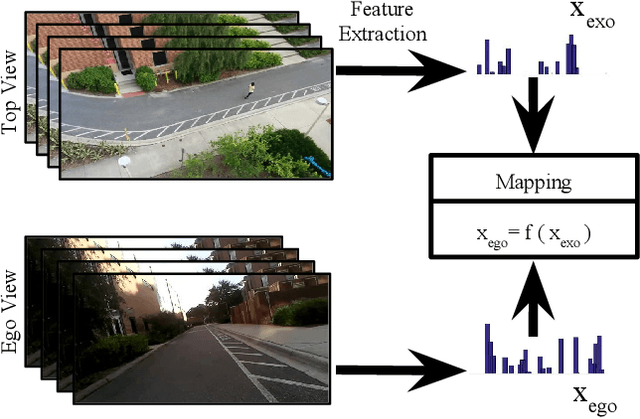


Mirror neurons have been observed in the primary motor cortex of primate species, in particular in humans and monkeys. A mirror neuron fires when a person performs a certain action, and also when he observes the same action being performed by another person. A crucial step towards building fully autonomous intelligent systems with human-like learning abilities is the capability in modeling the mirror neuron. On one hand, the abundance of egocentric cameras in the past few years has offered the opportunity to study a lot of vision problems from the first-person perspective. A great deal of interesting research has been done during the past few years, trying to explore various computer vision tasks from the perspective of the self. On the other hand, videos recorded by traditional static cameras, capture humans performing different actions from an exocentric third-person perspective. In this work, we take the first step towards relating motion information across these two perspectives. We train models that predict motion in an egocentric view, by observing it from an exocentric view, and vice versa. This allows models to predict how an egocentric motion would look like from outside. To do so, we train linear and nonlinear models and evaluate their performance in terms of retrieving the egocentric (exocentric) motion features, while having access to an exocentric (egocentric) motion feature. Our experimental results demonstrate that motion information can be successfully transferred across the two views.
Exploiting inter-image similarity and ensemble of extreme learners for fixation prediction using deep features
Oct 20, 2016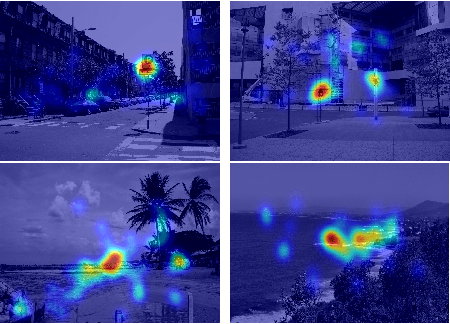
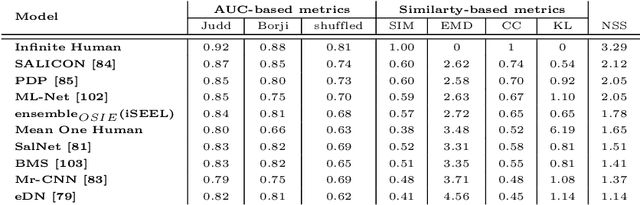
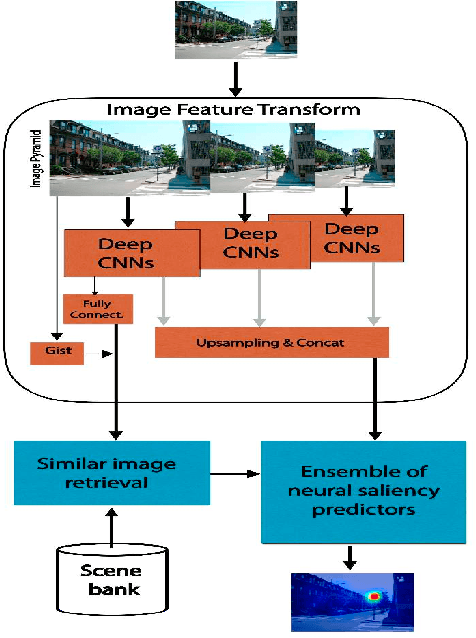
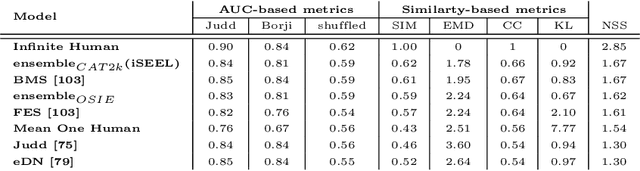
This paper presents a novel fixation prediction and saliency modeling framework based on inter-image similarities and ensemble of Extreme Learning Machines (ELM). The proposed framework is inspired by two observations, 1) the contextual information of a scene along with low-level visual cues modulates attention, 2) the influence of scene memorability on eye movement patterns caused by the resemblance of a scene to a former visual experience. Motivated by such observations, we develop a framework that estimates the saliency of a given image using an ensemble of extreme learners, each trained on an image similar to the input image. That is, after retrieving a set of similar images for a given image, a saliency predictor is learnt from each of the images in the retrieved image set using an ELM, resulting in an ensemble. The saliency of the given image is then measured in terms of the mean of predicted saliency value by the ensemble's members.
Egocentric Height Estimation
Oct 09, 2016
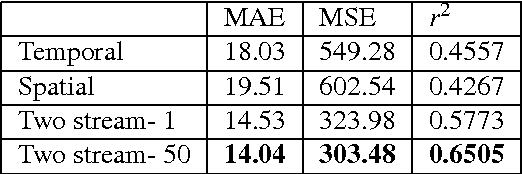
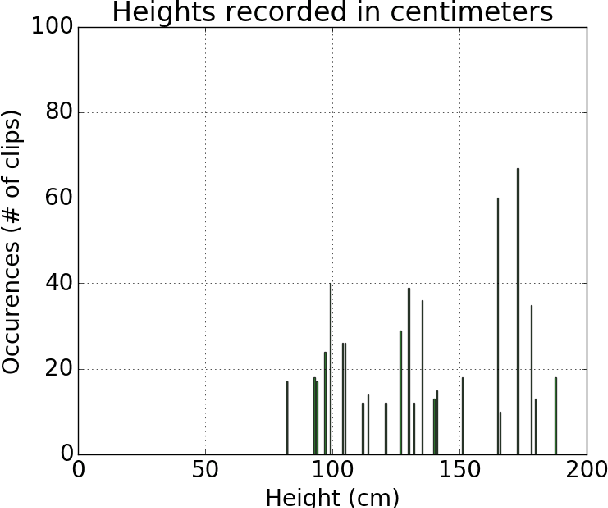
Egocentric, or first-person vision which became popular in recent years with an emerge in wearable technology, is different than exocentric (third-person) vision in some distinguishable ways, one of which being that the camera wearer is generally not visible in the video frames. Recent work has been done on action and object recognition in egocentric videos, as well as work on biometric extraction from first-person videos. Height estimation can be a useful feature for both soft-biometrics and object tracking. Here, we propose a method of estimating the height of an egocentric camera without any calibration or reference points. We used both traditional computer vision approaches and deep learning in order to determine the visual cues that results in best height estimation. Here, we introduce a framework inspired by two stream networks comprising of two Convolutional Neural Networks, one based on spatial information, and one based on information given by optical flow in a frame. Given an egocentric video as an input to the framework, our model yields a height estimate as an output. We also incorporate late fusion to learn a combination of temporal and spatial cues. Comparing our model with other methods we used as baselines, we achieve height estimates for videos with a Mean Average Error of 14.04 cm over a range of 103 cm of data, and classification accuracy for relative height (tall, medium or short) up to 93.75% where chance level is 33%.
Egocentric Meets Top-view
Sep 14, 2016
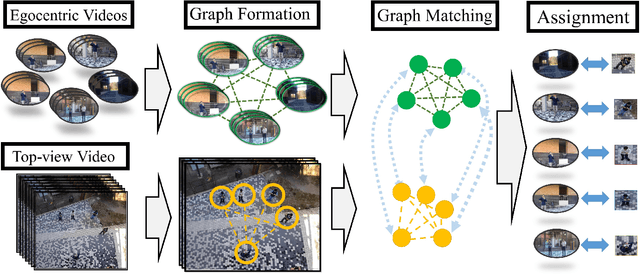
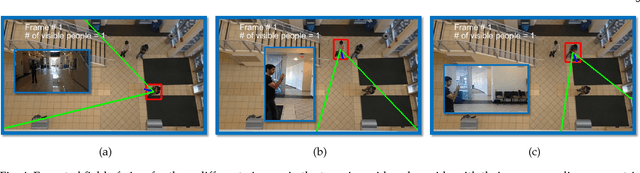
Thanks to the availability and increasing popularity of Egocentric cameras such as GoPro cameras, glasses, and etc. we have been provided with a plethora of videos captured from the first person perspective. Surveillance cameras and Unmanned Aerial Vehicles(also known as drones) also offer tremendous amount of videos, mostly with top-down or oblique view-point. Egocentric vision and top-view surveillance videos have been studied extensively in the past in the computer vision community. However, the relationship between the two has yet to be explored thoroughly. In this effort, we attempt to explore this relationship by approaching two questions. First, having a set of egocentric videos and a top-view video, can we verify if the top-view video contains all, or some of the egocentric viewers present in the egocentric set? And second, can we identify the egocentric viewers in the content of the top-view video? In other words, can we find the cameramen in the surveillance videos? These problems can become more challenging when the videos are not time-synchronous. Thus we formalize the problem in a way which handles and also estimates the unknown relative time-delays between the egocentric videos and the top-view video. We formulate the problem as a spectral graph matching instance, and jointly seek the optimal assignments and relative time-delays of the videos. As a result, we spatiotemporally localize the egocentric observers in the top-view video. We model each view (egocentric or top) using a graph, and compute the assignment and time-delays in an iterative-alternative fashion.
Vanishing point attracts gaze in free-viewing and visual search tasks
Sep 06, 2016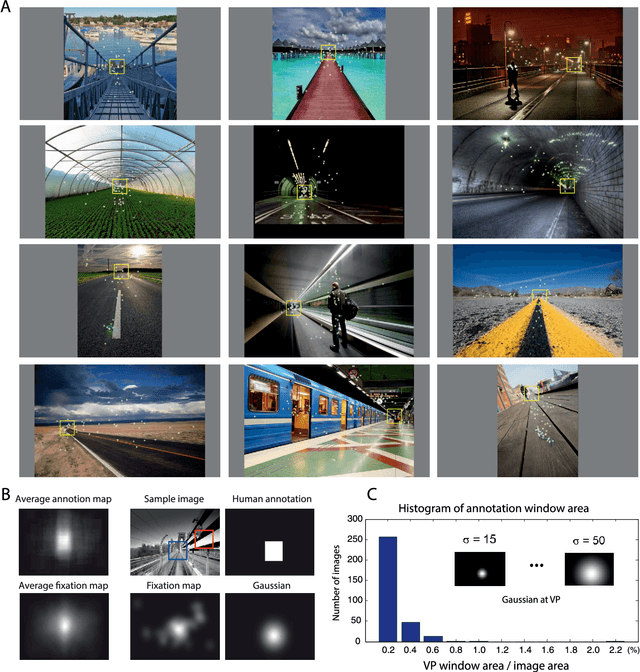

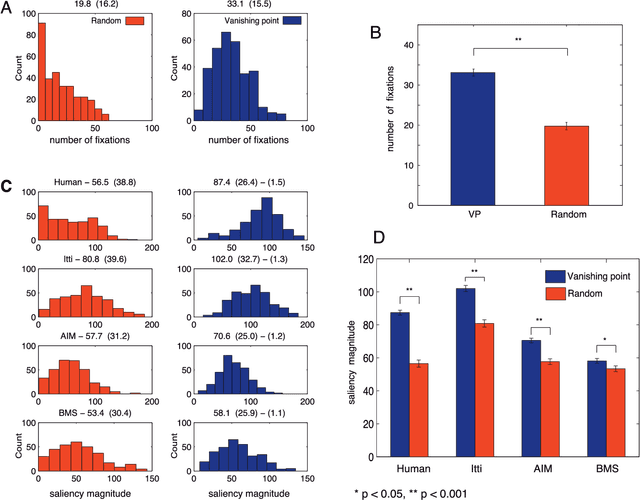

To investigate whether the vanishing point (VP) plays a significant role in gaze guidance, we ran two experiments. In the first one, we recorded fixations of 10 observers (4 female; mean age 22; SD=0.84) freely viewing 532 images, out of which 319 had VP (shuffled presentation; each image for 4 secs). We found that the average number of fixations at a local region (80x80 pixels) centered at the VP is significantly higher than the average fixations at random locations (t-test; n=319; p=1.8e-35). To address the confounding factor of saliency, we learned a combined model of bottom-up saliency and VP. AUC score of our model (0.85; SD=0.01) is significantly higher than the original saliency model (e.g., 0.8 using AIM model by Bruce & Tsotsos (2009), t-test; p= 3.14e-16) and the VP-only model (0.64, t-test; p= 4.02e-22). In the second experiment, we asked 14 subjects (4 female, mean age 23.07, SD=1.26) to search for a target character (T or L) placed randomly on a 3x3 imaginary grid overlaid on top of an image. Subjects reported their answers by pressing one of two keys. Stimuli consisted of 270 color images (180 with a single VP, 90 without). The target happened with equal probability inside each cell (15 times L, 15 times T). We found that subjects were significantly faster (and more accurate) when target happened inside the cell containing the VP compared to cells without VP (median across 14 subjects 1.34 sec vs. 1.96; Wilcoxon rank-sum test; p = 0.0014). Response time at VP cells were also significantly lower than response time on images without VP (median 2.37; p= 4.77e-05). These findings support the hypothesis that vanishing point, similar to face and text (Cerf et al., 2009) as well as gaze direction (Borji et al., 2014) attracts attention in free-viewing and visual search.
Vanishing point detection with convolutional neural networks
Sep 04, 2016


Inspired by the finding that vanishing point (road tangent) guides driver's gaze, in our previous work we showed that vanishing point attracts gaze during free viewing of natural scenes as well as in visual search (Borji et al., Journal of Vision 2016). We have also introduced improved saliency models using vanishing point detectors (Feng et al., WACV 2016). Here, we aim to predict vanishing points in naturalistic environments by training convolutional neural networks in an end-to-end manner over a large set of road images downloaded from Youtube with vanishing points annotated. Results demonstrate effectiveness of our approach compared to classic approaches of vanishing point detection in the literature.
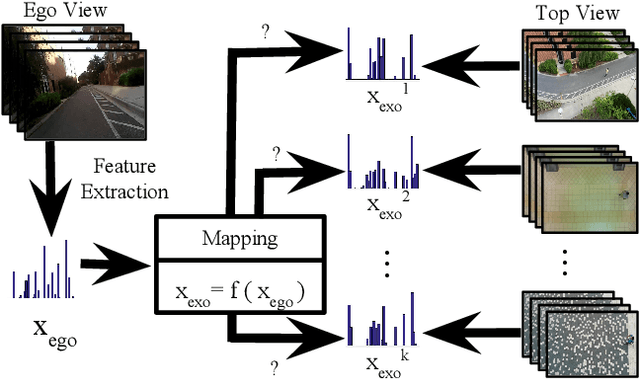
Ego2Top: Matching Viewers in Egocentric and Top-view Videos
Aug 13, 2016


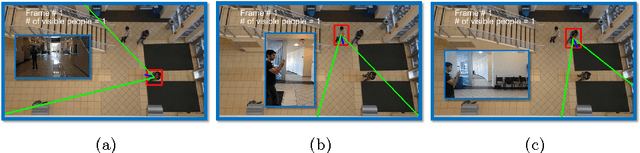
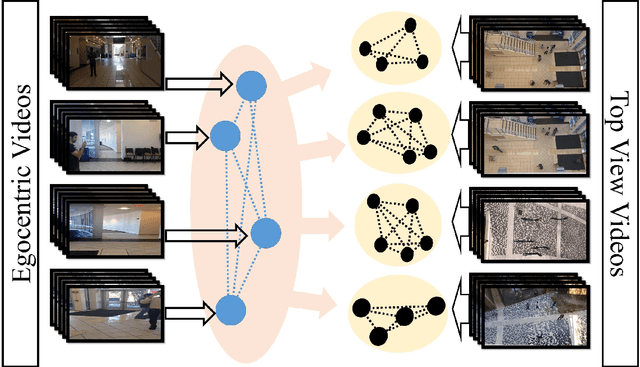
Egocentric cameras are becoming increasingly popular and provide us with large amounts of videos, captured from the first person perspective. At the same time, surveillance cameras and drones offer an abundance of visual information, often captured from top-view. Although these two sources of information have been separately studied in the past, they have not been collectively studied and related. Having a set of egocentric cameras and a top-view camera capturing the same area, we propose a framework to identify the egocentric viewers in the top-view video. We utilize two types of features for our assignment procedure. Unary features encode what a viewer (seen from top-view or recording an egocentric video) visually experiences over time. Pairwise features encode the relationship between the visual content of a pair of viewers. Modeling each view (egocentric or top) by a graph, the assignment process is formulated as spectral graph matching. Evaluating our method over a dataset of 50 top-view and 188 egocentric videos taken in different scenarios demonstrates the efficiency of the proposed approach in assigning egocentric viewers to identities present in top-view camera. We also study the effect of different parameters such as the number of egocentric viewers and visual features.
What can we learn about CNNs from a large scale controlled object dataset?
Jan 26, 2016
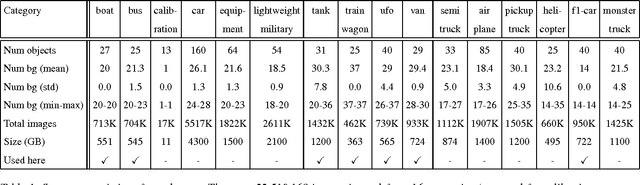
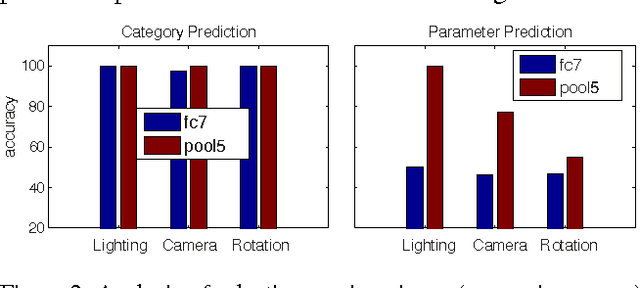
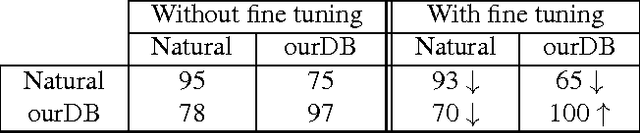
Tolerance to image variations (e.g. translation, scale, pose, illumination) is an important desired property of any object recognition system, be it human or machine. Moving towards increasingly bigger datasets has been trending in computer vision specially with the emergence of highly popular deep learning models. While being very useful for learning invariance to object inter- and intra-class shape variability, these large-scale wild datasets are not very useful for learning invariance to other parameters forcing researchers to resort to other tricks for training a model. In this work, we introduce a large-scale synthetic dataset, which is freely and publicly available, and use it to answer several fundamental questions regarding invariance and selectivity properties of convolutional neural networks. Our dataset contains two parts: a) objects shot on a turntable: 16 categories, 8 rotation angles, 11 cameras on a semicircular arch, 5 lighting conditions, 3 focus levels, variety of backgrounds (23.4 per instance) generating 1320 images per instance (over 20 million images in total), and b) scenes: in which a robot arm takes pictures of objects on a 1:160 scale scene. We study: 1) invariance and selectivity of different CNN layers, 2) knowledge transfer from one object category to another, 3) systematic or random sampling of images to build a train set, 4) domain adaptation from synthetic to natural scenes, and 5) order of knowledge delivery to CNNs. We also explore how our analyses can lead the field to develop more efficient CNNs.
Fixation prediction with a combined model of bottom-up saliency and vanishing point
Dec 06, 2015
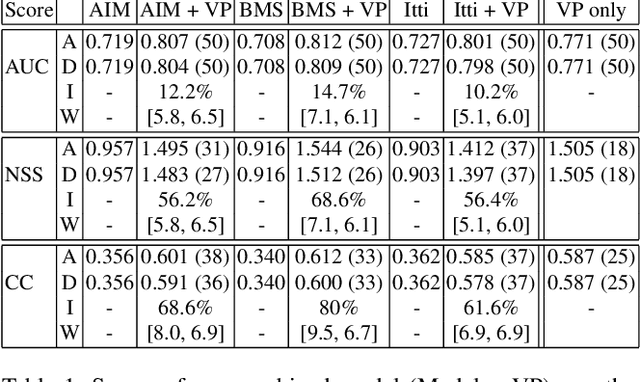
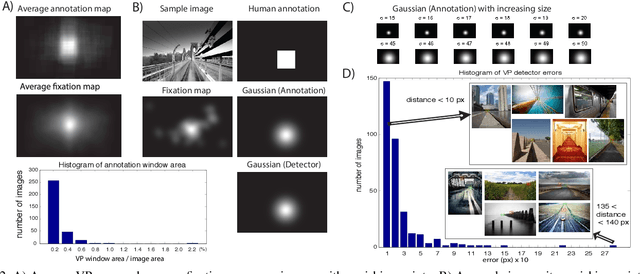
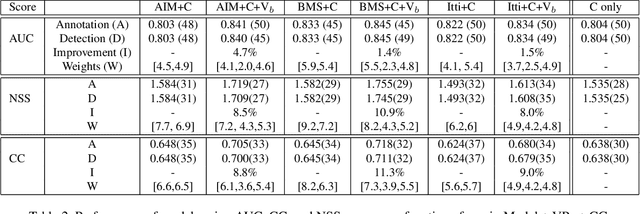
By predicting where humans look in natural scenes, we can understand how they perceive complex natural scenes and prioritize information for further high-level visual processing. Several models have been proposed for this purpose, yet there is a gap between best existing saliency models and human performance. While many researchers have developed purely computational models for fixation prediction, less attempts have been made to discover cognitive factors that guide gaze. Here, we study the effect of a particular type of scene structural information, known as the vanishing point, and show that human gaze is attracted to the vanishing point regions. We record eye movements of 10 observers over 532 images, out of which 319 have vanishing points. We then construct a combined model of traditional saliency and a vanishing point channel and show that our model outperforms state of the art saliency models using three scores on our dataset.
Computational models: Bottom-up and top-down aspects
Oct 27, 2015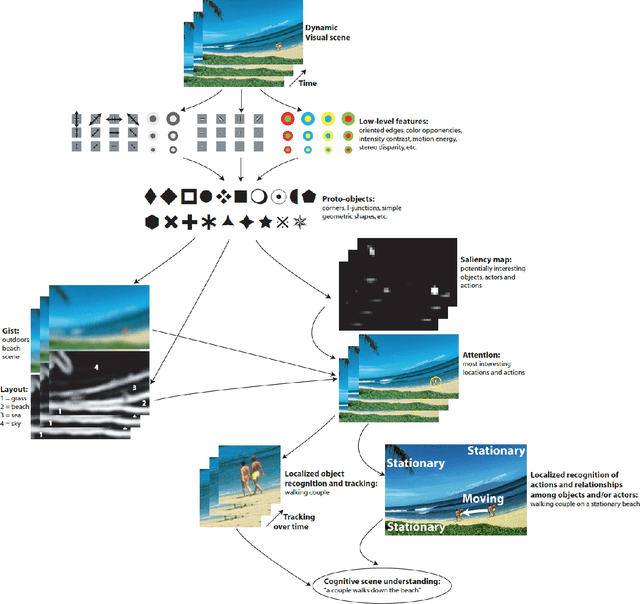
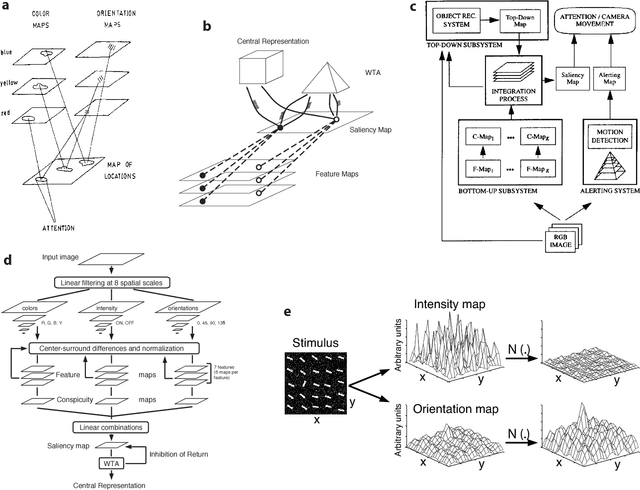
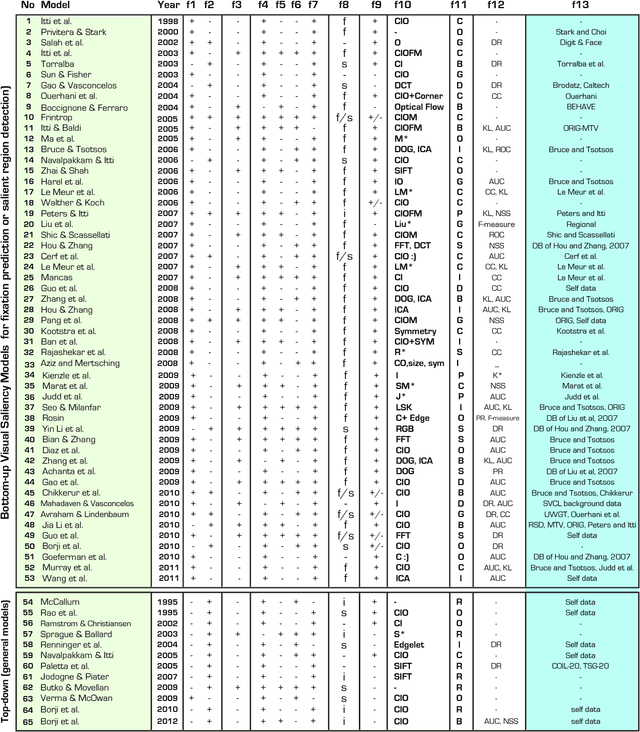
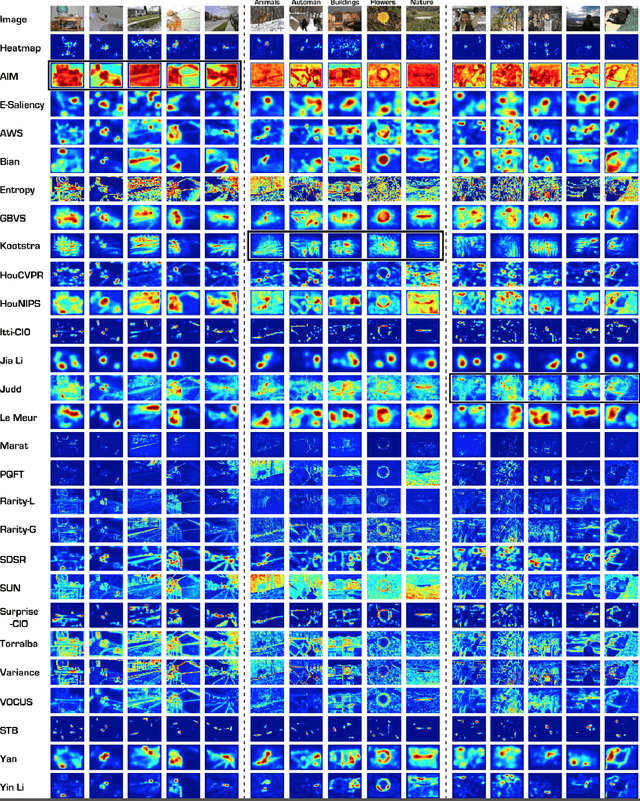
Computational models of visual attention have become popular over the past decade, we believe primarily for two reasons: First, models make testable predictions that can be explored by experimentalists as well as theoreticians, second, models have practical and technological applications of interest to the applied science and engineering communities. In this chapter, we take a critical look at recent attention modeling efforts. We focus on {\em computational models of attention} as defined by Tsotsos \& Rothenstein \shortcite{Tsotsos_Rothenstein11}: Models which can process any visual stimulus (typically, an image or video clip), which can possibly also be given some task definition, and which make predictions that can be compared to human or animal behavioral or physiological responses elicited by the same stimulus and task. Thus, we here place less emphasis on abstract models, phenomenological models, purely data-driven fitting or extrapolation models, or models specifically designed for a single task or for a restricted class of stimuli. For theoretical models, we refer the reader to a number of previous reviews that address attention theories and models more generally \cite{Itti_Koch01nrn,Paletta_etal05,Frintrop_etal10,Rothenstein_Tsotsos08,Gottlieb_Balan10,Toet11,Borji_Itti12pami}.