 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSmoothed Elicitation Complexity for Approximate $Γ$-calibration of Discrete Classification Tasks
May 21, 2026One prominent method of evaluating machine learning model trustworthiness is the notion of calibration. In the binary outcome setting, a probabilistic predictor is calibrated if outcomes are realized according to a model's distributional prediction, conditioned on this prediction. Straightforward extensions of binary calibration definitions to probabilistic multiclass classifiers suffer from an exponential complexity blowup as the space of predictions grows exponentially in the number of classes $n$. As a remedy, Noarov and Roth (2023) propose multiclass calibration with predictions that are properties of the outcome distribution, reducing complexity from growing in the number of classes $n$ to the dimension $d$ of the property, called its elicitation complexity. Previous work on approximate property calibration is generally limited to continuous scalar properties, despite many relevant properties of interest being discrete, like the mode or rankings. We characterize the approximate property calibration of discrete properties which are strongly orderable by using Lipschitz continuous properties as an intermediary. This work is the first to our knowledge to provide approximate calibration results for discrete properties. Along the way, we characterize the Lipschitz elicitation complexity of strongly orderable discrete properties by constructing algorithms for designing these Lipschitz properties, which we prove can be post-processed to obtain the original discrete property.
Egocentric Height Estimation
Oct 09, 2016
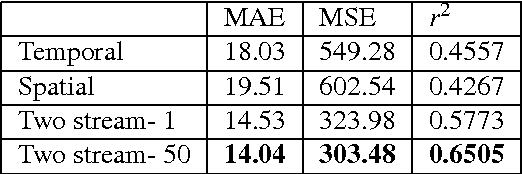
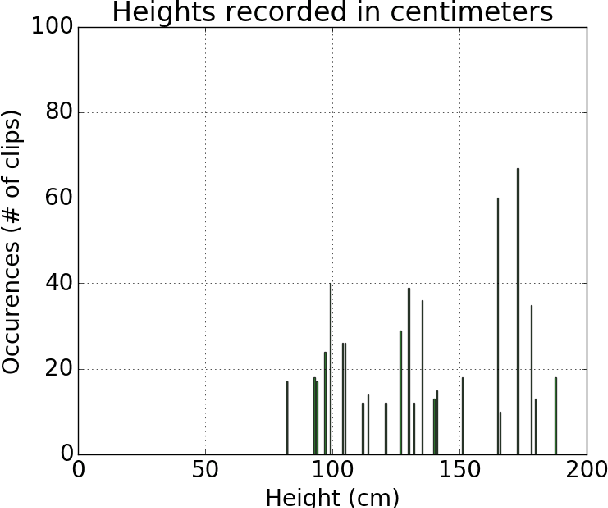
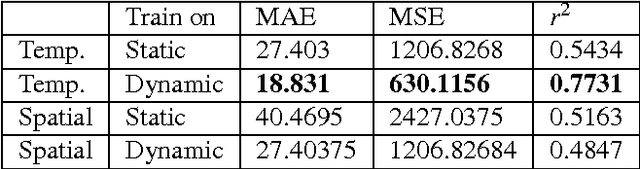
Egocentric, or first-person vision which became popular in recent years with an emerge in wearable technology, is different than exocentric (third-person) vision in some distinguishable ways, one of which being that the camera wearer is generally not visible in the video frames. Recent work has been done on action and object recognition in egocentric videos, as well as work on biometric extraction from first-person videos. Height estimation can be a useful feature for both soft-biometrics and object tracking. Here, we propose a method of estimating the height of an egocentric camera without any calibration or reference points. We used both traditional computer vision approaches and deep learning in order to determine the visual cues that results in best height estimation. Here, we introduce a framework inspired by two stream networks comprising of two Convolutional Neural Networks, one based on spatial information, and one based on information given by optical flow in a frame. Given an egocentric video as an input to the framework, our model yields a height estimate as an output. We also incorporate late fusion to learn a combination of temporal and spatial cues. Comparing our model with other methods we used as baselines, we achieve height estimates for videos with a Mean Average Error of 14.04 cm over a range of 103 cm of data, and classification accuracy for relative height (tall, medium or short) up to 93.75% where chance level is 33%.