 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEmpirical Upper Bound in Object Detection and More
Dec 17, 2019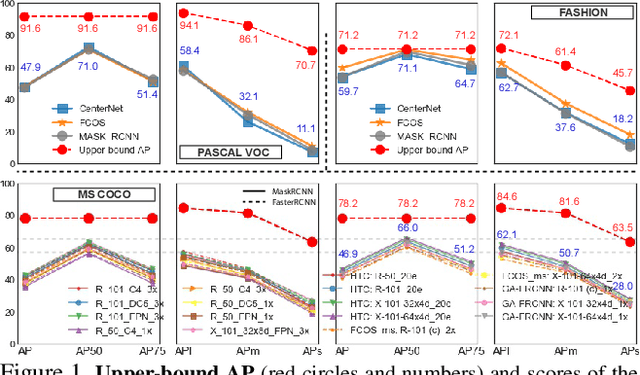
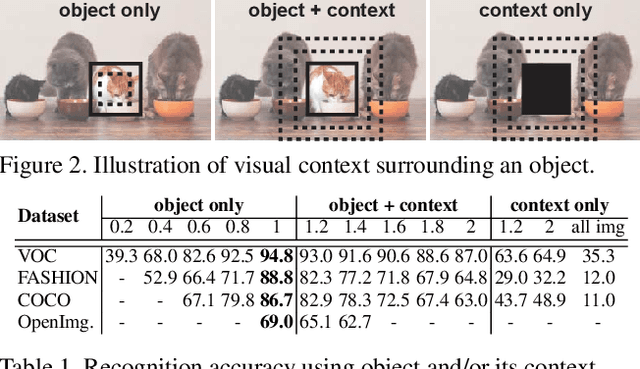

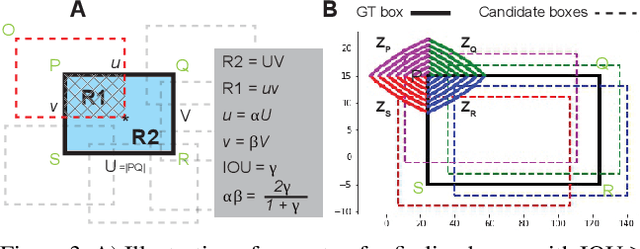
Object detection remains as one of the most notorious open problems in computer vision. Despite large strides in accuracy in recent years, modern object detectors have started to saturate on popular benchmarks raising the question of how far we can reach with deep learning tools and tricks. Here, by employing 2 state-of-the-art object detection benchmarks, and analyzing more than 15 models over 4 large scale datasets, we I) carefully determine the upperbound in AP, which is 91.6% on VOC (test2007), 78.2% on COCO (val2017), and 58.9% on OpenImages V4 (validation), regardless of the IOU. These numbers are much better than the mAP of the best model1 (47.9% on VOC, and 46.9% on COCO; IOUs=.5:.95), II) characterize the sources of errors in object detectors, in a novel and intuitive way, and find that classification error (confusion with other classes and misses) explains the largest fraction of errors and weighs more than localization and duplicate errors, and III) analyze the invariance properties of models when surrounding context of an object is removed, when an object is placed in an incongruent background, and when images are blurred or flipped vertically. We find that models generate boxes on empty regions and that context is more important for detecting small objects than larger ones. Our work taps into the tight relationship between recognition and detection and offers insights for building better models.
A New Ensemble Adversarial Attack Powered by Long-term Gradient Memories
Nov 18, 2019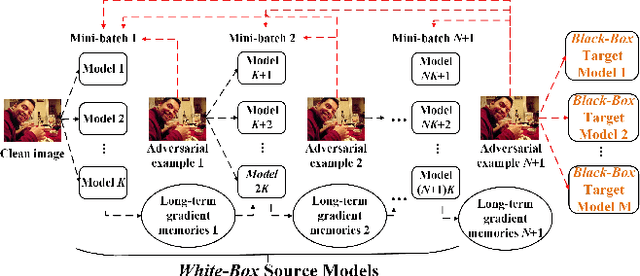
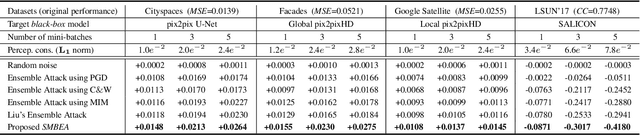
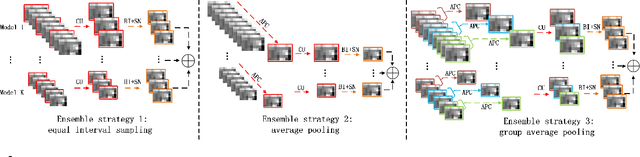
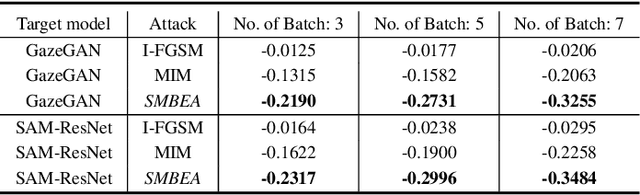
Deep neural networks are vulnerable to adversarial attacks.
DAVE: A Deep Audio-Visual Embedding for Dynamic Saliency Prediction
May 25, 2019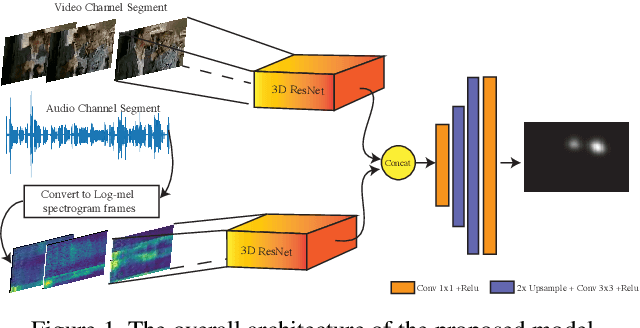
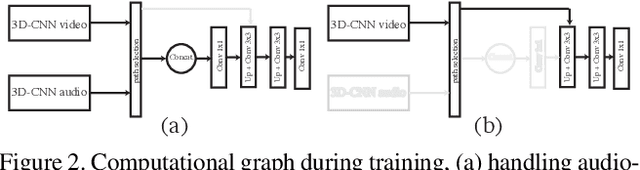
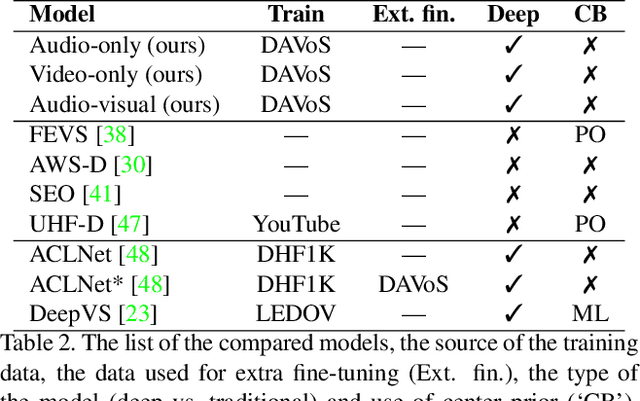
This paper presents a conceptually simple and effective Deep Audio-Visual Eembedding for dynamic saliency prediction dubbed ``DAVE". Several behavioral studies have shown a strong relation between auditory and visual cues for guiding gaze during scene free viewing. The existing video saliency models, however, only consider visual cues for predicting saliency over videos and neglect the auditory information that is ubiquitous in dynamic scenes. We propose a multimodal saliency model that utilizes audio and visual information for predicting saliency in videos. Our model consists of a two-stream encoder and a decoder. First, auditory and visual information are mapped into a feature space using 3D Convolutional Neural Networks (3D CNNs). Then, a decoder combines the features and maps them to a final saliency map. To train such model, data from various eye tracking datasets containing video and audio are pulled together. We further categorised videos into `social', `nature', and `miscellaneous' classes to analyze the models over different content types. Several analyses show that our audio-visual model outperforms video-based models significantly over all scores; overall and over individual categories. Contextual analysis of the model performance over the location of sound source reveals that the audio-visual model behaves similar to humans in attending to the location of sound source. Our endeavour demonstrates that audio is an important signal that can boost video saliency prediction and help getting closer to human performance.
GazeGAN: A Generative Adversarial Saliency Model based on Invariance Analysis of Human Gaze During Scene Free Viewing
May 25, 2019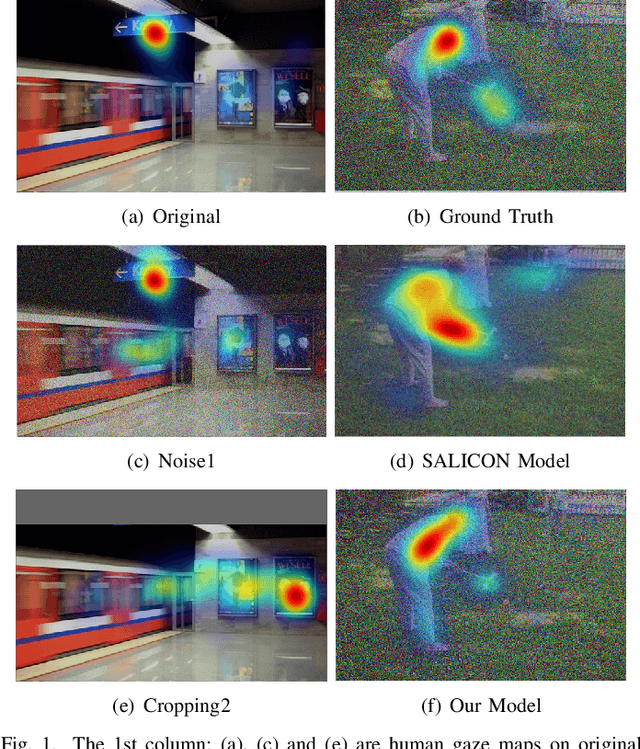


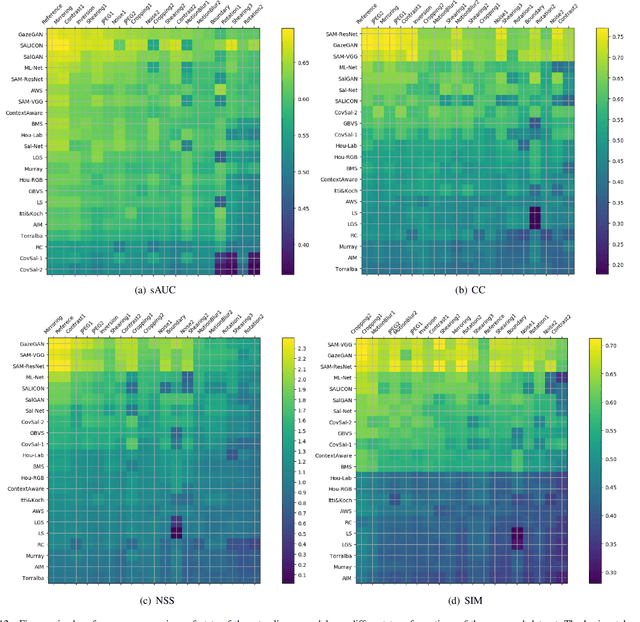
Data size is the bottleneck for developing deep saliency models, because collecting eye-movement data is very time consuming and expensive. Most of current studies on human attention and saliency modeling have used high quality stereotype stimuli. In real world, however, captured images undergo various types of transformations. Can we use these transformations to augment existing saliency datasets? Here, we first create a novel saliency dataset including fixations of 10 observers over 1900 images degraded by 19 types of transformations. Second, by analyzing eye movements, we find that observers look at different locations over transformed versus original images. Third, we utilize the new data over transformed images, called data augmentation transformation (DAT), to train deep saliency models. We find that label preserving DATs with negligible impact on human gaze boost saliency prediction, whereas some other DATs that severely impact human gaze degrade the performance. These label preserving valid augmentation transformations provide a solution to enlarge existing saliency datasets. Finally, we introduce a novel saliency model based on generative adversarial network (dubbed GazeGAN). A modified UNet is proposed as the generator of the GazeGAN, which combines classic skip connections with a novel center-surround connection (CSC), in order to leverage multi level features. We also propose a histogram loss based on Alternative Chi Square Distance (ACS HistLoss) to refine the saliency map in terms of luminance distribution. Extensive experiments and comparisons over 3 datasets indicate that GazeGAN achieves the best performance in terms of popular saliency evaluation metrics, and is more robust to various perturbations. Our code and data are available at: https://github.com/CZHQuality/Sal-CFS-GAN.
Digging Deeper into Egocentric Gaze Prediction
Apr 12, 2019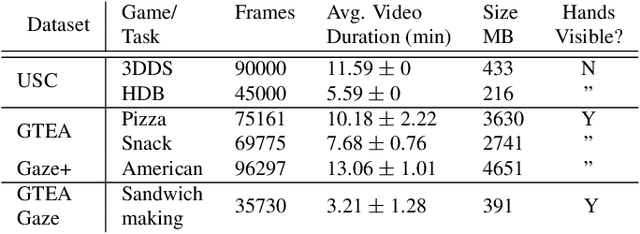

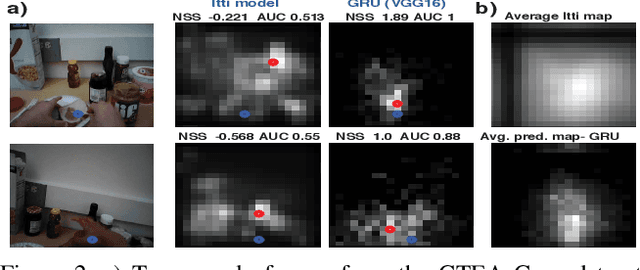
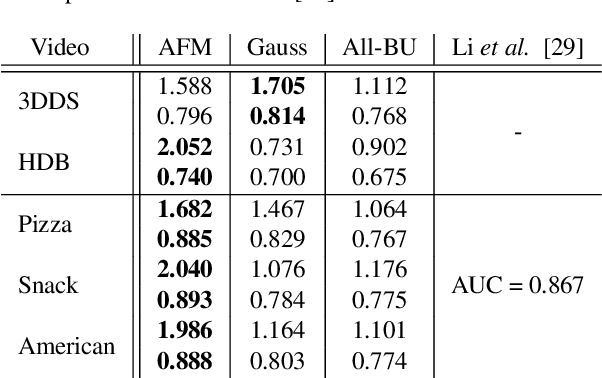
This paper digs deeper into factors that influence egocentric gaze. Instead of training deep models for this purpose in a blind manner, we propose to inspect factors that contribute to gaze guidance during daily tasks. Bottom-up saliency and optical flow are assessed versus strong spatial prior baselines. Task-specific cues such as vanishing point, manipulation point, and hand regions are analyzed as representatives of top-down information. We also look into the contribution of these factors by investigating a simple recurrent neural model for ego-centric gaze prediction. First, deep features are extracted for all input video frames. Then, a gated recurrent unit is employed to integrate information over time and to predict the next fixation. We also propose an integrated model that combines the recurrent model with several top-down and bottom-up cues. Extensive experiments over multiple datasets reveal that (1) spatial biases are strong in egocentric videos, (2) bottom-up saliency models perform poorly in predicting gaze and underperform spatial biases, (3) deep features perform better compared to traditional features, (4) as opposed to hand regions, the manipulation point is a strong influential cue for gaze prediction, (5) combining the proposed recurrent model with bottom-up cues, vanishing points and, in particular, manipulation point results in the best gaze prediction accuracy over egocentric videos, (6) the knowledge transfer works best for cases where the tasks or sequences are similar, and (7) task and activity recognition can benefit from gaze prediction. Our findings suggest that (1) there should be more emphasis on hand-object interaction and (2) the egocentric vision community should consider larger datasets including diverse stimuli and more subjects.
Understanding and Visualizing Deep Visual Saliency Models
Apr 03, 2019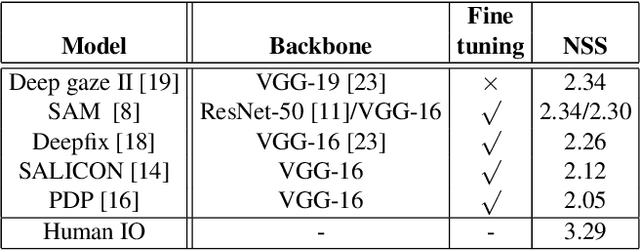
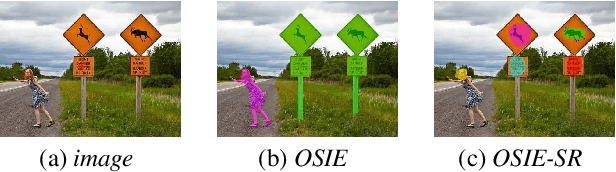

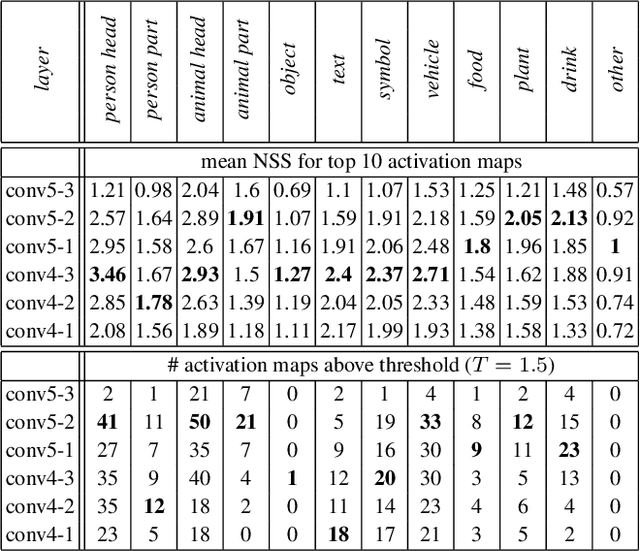
Recently, data-driven deep saliency models have achieved high performance and have outperformed classical saliency models, as demonstrated by results on datasets such as the MIT300 and SALICON. Yet, there remains a large gap between the performance of these models and the inter-human baseline. Some outstanding questions include what have these models learned, how and where they fail, and how they can be improved. This article attempts to answer these questions by analyzing the representations learned by individual neurons located at the intermediate layers of deep saliency models. To this end, we follow the steps of existing deep saliency models, that is borrowing a pre-trained model of object recognition to encode the visual features and learning a decoder to infer the saliency. We consider two cases when the encoder is used as a fixed feature extractor and when it is fine-tuned, and compare the inner representations of the network. To study how the learned representations depend on the task, we fine-tune the same network using the same image set but for two different tasks: saliency prediction versus scene classification. Our analyses reveal that: 1) some visual regions (e.g. head, text, symbol, vehicle) are already encoded within various layers of the network pre-trained for object recognition, 2) using modern datasets, we find that fine-tuning pre-trained models for saliency prediction makes them favor some categories (e.g. head) over some others (e.g. text), 3) although deep models of saliency outperform classical models on natural images, the converse is true for synthetic stimuli (e.g. pop-out search arrays), an evidence of significant difference between human and data-driven saliency models, and 4) we confirm that, after-fine tuning, the change in inner-representations is mostly due to the task and not the domain shift in the data.
Adversarial Attacks against Deep Saliency Models
Apr 02, 2019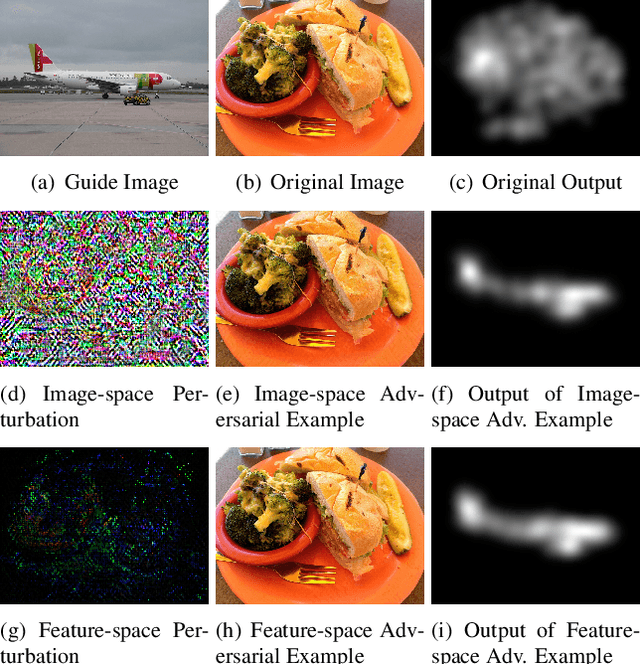
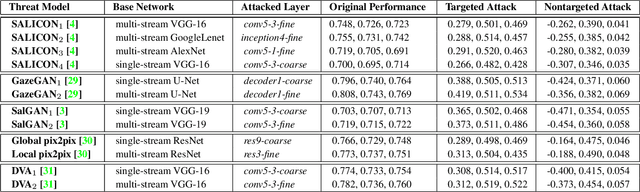
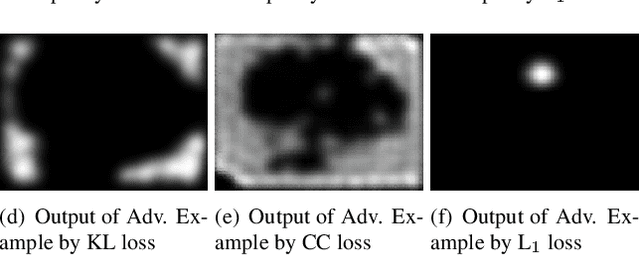
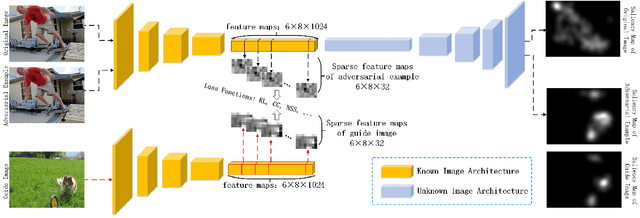
Currently, a plethora of saliency models based on deep neural networks have led great breakthroughs in many complex high-level vision tasks (e.g. scene description, object detection). The robustness of these models, however, has not yet been studied. In this paper, we propose a sparse feature-space adversarial attack method against deep saliency models for the first time. The proposed attack only requires a part of the model information, and is able to generate a sparser and more insidious adversarial perturbation, compared to traditional image-space attacks. These adversarial perturbations are so subtle that a human observer cannot notice their presences, but the model outputs will be revolutionized. This phenomenon raises security threats to deep saliency models in practical applications. We also explore some intriguing properties of the feature-space attack, e.g. 1) the hidden layers with bigger receptive fields generate sparser perturbations, 2) the deeper hidden layers achieve higher attack success rates, and 3) different loss functions and different attacked layers will result in diverse perturbations. Experiments indicate that the proposed method is able to successfully attack different model architectures across various image scenes.
A Synchronized Multi-Modal Attention-Caption Dataset and Analysis
Mar 06, 2019
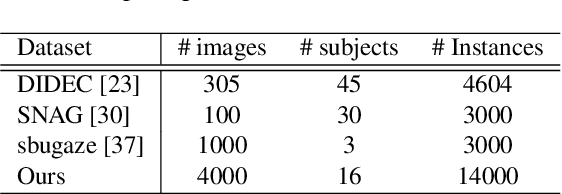
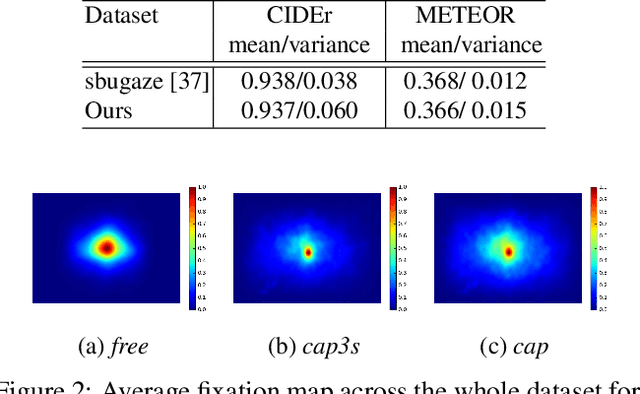

In this work, we present a novel multi-modal dataset consisting of eye movements and verbal descriptions recorded synchronously over images. Using this data, we study the differences between human attention in free-viewing and image captioning tasks. We look into the relationship between human attention and language constructs during perception and sentence articulation. We also compare human and machine attention, in particular the top-down soft attention approach that is argued to mimick human attention, in captioning tasks. Our study reveals that, (1) human attention behaviour in free-viewing is different than image description as humans tend to fixate on a greater variety of regions under the latter task; (2) there is a strong relationship between the described objects and the objects attended by subjects ($97\%$ of described objects are being attended); (3) a convolutional neural network as feature encoder captures regions that human attend under image captioning to a great extent (around $78\%$); (4) the soft-attention as the top-down mechanism does not agree with human attention behaviour neither spatially nor temporally; and (5) soft-attention does not add strong beneficial human-like attention behaviour for the task of captioning as it has low correlation between caption scores and attention consistency scores, indicating a large gap between human and machine in regard to top-down attention.
Video Summarization via Actionness Ranking
Mar 01, 2019
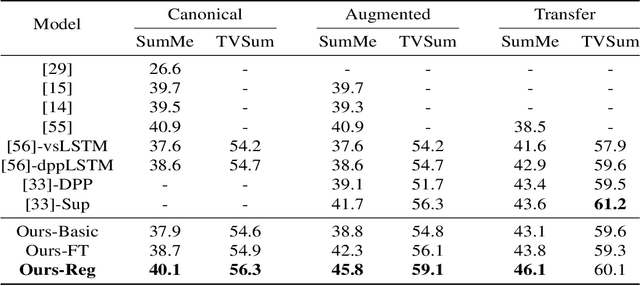
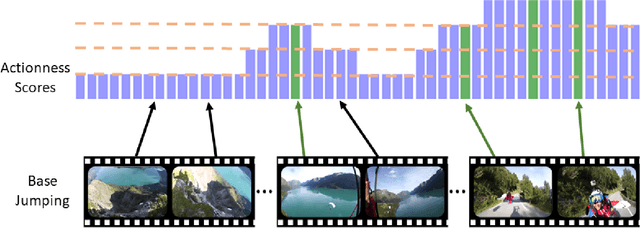
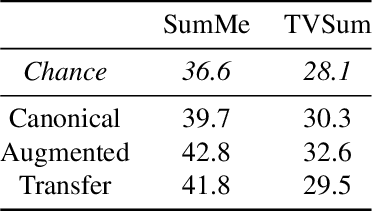
To automatically produce a brief yet expressive summary of a long video, an automatic algorithm should start by resembling the human process of summary generation. Prior work proposed supervised and unsupervised algorithms to train models for learning the underlying behavior of humans by increasing modeling complexity or craft-designing better heuristics to simulate human summary generation process. In this work, we take a different approach by analyzing a major cue that humans exploit for the summary generation; the nature and intensity of actions. We empirically observed that a frame is more likely to be included in human-generated summaries if it contains a substantial amount of deliberate motion performed by an agent, which is referred to as actionness. Therefore, we hypothesize that learning to automatically generate summaries involves an implicit knowledge of actionness estimation and ranking. We validate our hypothesis by running a user study that explores the correlation between human-generated summaries and actionness ranks. We also run a consensus and behavioral analysis between human subjects to ensure reliable and consistent results. The analysis exhibits a considerable degree of agreement among subjects within obtained data and verifying our initial hypothesis. Based on the study findings, we develop a method to incorporate actionness data to explicitly regulate a learning algorithm that is trained for summary generation. We assess the performance of our approach to four summarization benchmark datasets and demonstrate an evident advantage compared to state-of-the-art summarization methods.
Multi-View Egocentric Video Summarization
Dec 01, 2018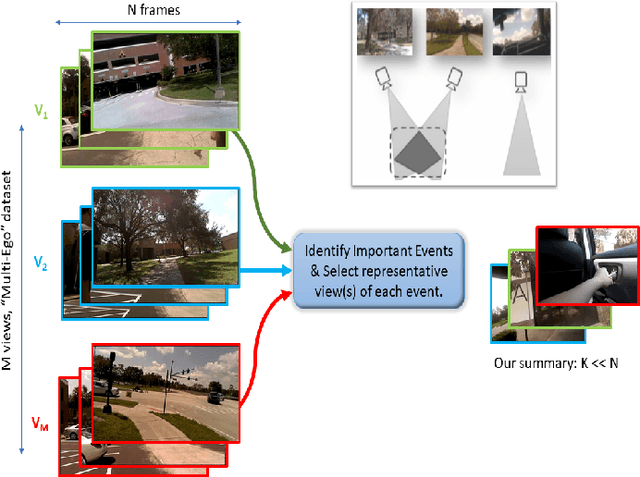
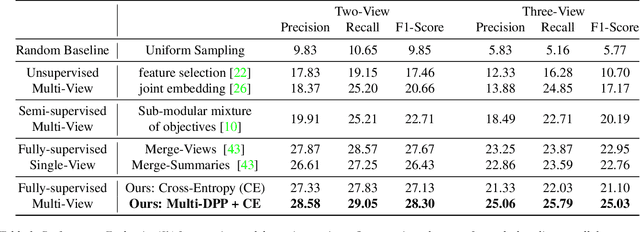
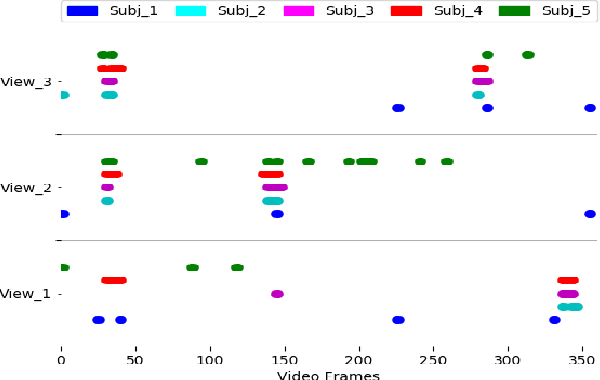
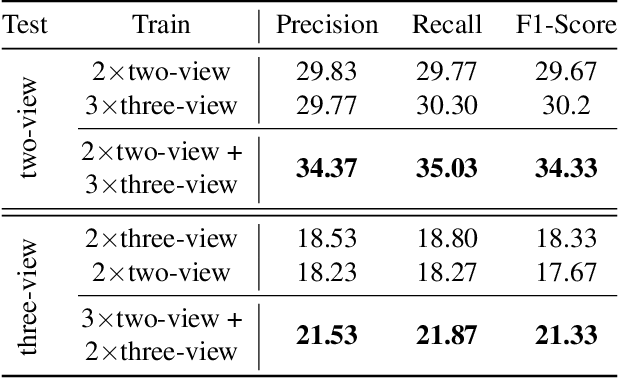
With vast amounts of video content being uploaded to the Internet every minute, video summarization becomes critical for efficient browsing, searching, and indexing of visual content. Nonetheless, the spread of social and egocentric cameras tends to create an abundance of sparse scenarios captured by several devices, and ultimately required to be jointly summarized. In this paper, we propose the problem of summarizing videos recorded simultaneously by several egocentric cameras that intermittently share the field of view. We present a supervised-learning framework that (a) identifies a diverse set of important events among dynamically moving cameras that often are not capturing the same scene, and (b) selects the most representative view(s) at each event to be included in the universal summary. A key contribution of our work is collecting a new multi-view egocentric dataset, Multi-Ego, due to the lack of an applicable and relevant alternative. Our dataset consists of 41 sequences, each recorded simultaneously by 3 cameras and covering a wide variety of real-life scenarios. The footage is annotated comprehensively by multiple individuals under various summarization settings: (a) single view, (b) two view, and (c) three view, with a consensus analysis ensuring a reliable ground truth. We conduct extensive experiments on the compiled dataset to show the effectiveness of our approach over several state-of-the-art baselines. We also show that it can learn from data of varied number-of-views, deeming it a scalable and a generic summarization approach. Our dataset and materials are publicly available.