 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSemantic Answer Type and Relation Prediction Task (SMART 2021)
Jan 10, 2022
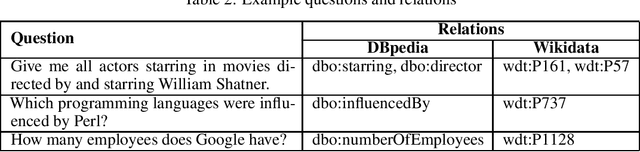
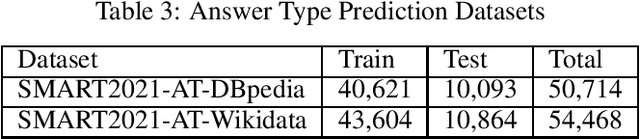
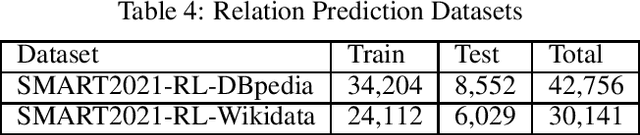
Each year the International Semantic Web Conference organizes a set of Semantic Web Challenges to establish competitions that will advance state-of-the-art solutions in some problem domains. The Semantic Answer Type and Relation Prediction Task (SMART) task is one of the ISWC 2021 Semantic Web challenges. This is the second year of the challenge after a successful SMART 2020 at ISWC 2020. This year's version focuses on two sub-tasks that are very important to Knowledge Base Question Answering (KBQA): Answer Type Prediction and Relation Prediction. Question type and answer type prediction can play a key role in knowledge base question answering systems providing insights about the expected answer that are helpful to generate correct queries or rank the answer candidates. More concretely, given a question in natural language, the first task is, to predict the answer type using a target ontology (e.g., DBpedia or Wikidata. Similarly, the second task is to identify relations in the natural language query and link them to the relations in a target ontology. This paper discusses the task descriptions, benchmark datasets, and evaluation metrics. For more information, please visit https://smart-task.github.io/2021/.
Topic Transferable Table Question Answering
Sep 15, 2021
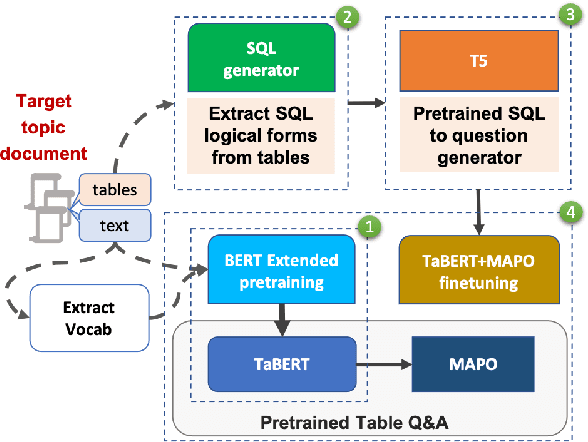
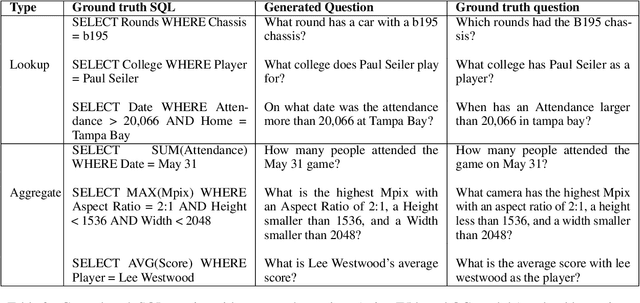
Weakly-supervised table question-answering(TableQA) models have achieved state-of-art performance by using pre-trained BERT transformer to jointly encoding a question and a table to produce structured query for the question. However, in practical settings TableQA systems are deployed over table corpora having topic and word distributions quite distinct from BERT's pretraining corpus. In this work we simulate the practical topic shift scenario by designing novel challenge benchmarks WikiSQL-TS and WikiTQ-TS, consisting of train-dev-test splits in five distinct topic groups, based on the popular WikiSQL and WikiTableQuestions datasets. We empirically show that, despite pre-training on large open-domain text, performance of models degrades significantly when they are evaluated on unseen topics. In response, we propose T3QA (Topic Transferable Table Question Answering) a pragmatic adaptation framework for TableQA comprising of: (1) topic-specific vocabulary injection into BERT, (2) a novel text-to-text transformer generator (such as T5, GPT2) based natural language question generation pipeline focused on generating topic specific training data, and (3) a logical form reranker. We show that T3QA provides a reasonably good baseline for our topic shift benchmarks. We believe our topic split benchmarks will lead to robust TableQA solutions that are better suited for practical deployment.
Robust Retrieval Augmented Generation for Zero-shot Slot Filling
Aug 31, 2021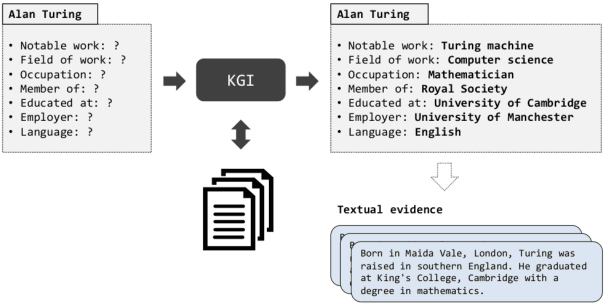
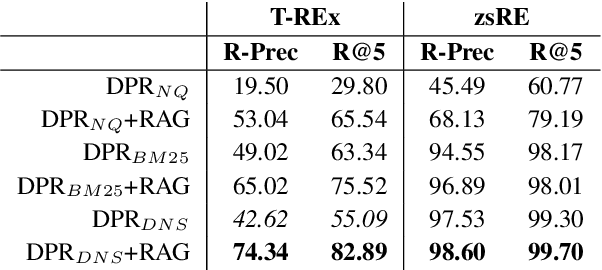
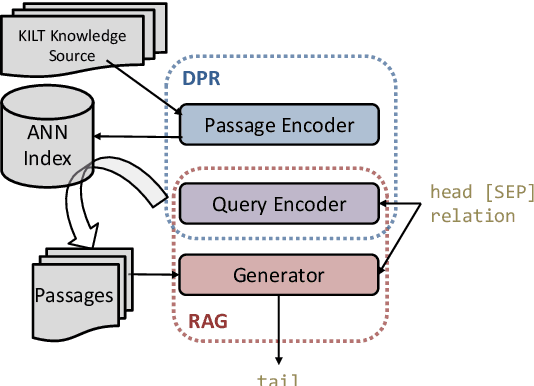
Automatically inducing high quality knowledge graphs from a given collection of documents still remains a challenging problem in AI. One way to make headway for this problem is through advancements in a related task known as slot filling. In this task, given an entity query in form of [Entity, Slot, ?], a system is asked to fill the slot by generating or extracting the missing value exploiting evidence extracted from relevant passage(s) in the given document collection. The recent works in the field try to solve this task in an end-to-end fashion using retrieval-based language models. In this paper, we present a novel approach to zero-shot slot filling that extends dense passage retrieval with hard negatives and robust training procedures for retrieval augmented generation models. Our model reports large improvements on both T-REx and zsRE slot filling datasets, improving both passage retrieval and slot value generation, and ranking at the top-1 position in the KILT leaderboard. Moreover, we demonstrate the robustness of our system showing its domain adaptation capability on a new variant of the TACRED dataset for slot filling, through a combination of zero/few-shot learning. We release the source code and pre-trained models.
Generative Relation Linking for Question Answering over Knowledge Bases
Aug 16, 2021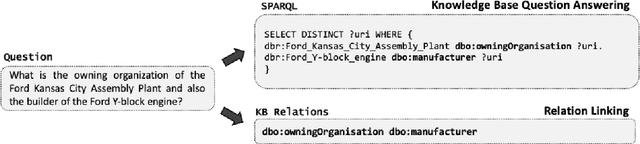
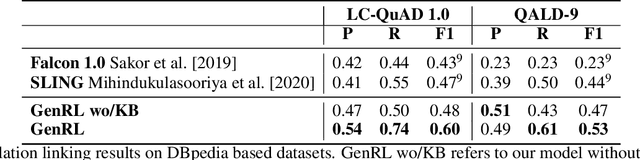
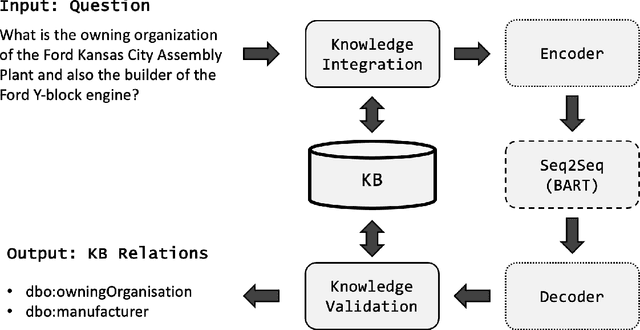
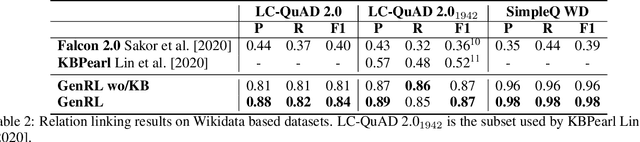
Relation linking is essential to enable question answering over knowledge bases. Although there are various efforts to improve relation linking performance, the current state-of-the-art methods do not achieve optimal results, therefore, negatively impacting the overall end-to-end question answering performance. In this work, we propose a novel approach for relation linking framing it as a generative problem facilitating the use of pre-trained sequence-to-sequence models. We extend such sequence-to-sequence models with the idea of infusing structured data from the target knowledge base, primarily to enable these models to handle the nuances of the knowledge base. Moreover, we train the model with the aim to generate a structured output consisting of a list of argument-relation pairs, enabling a knowledge validation step. We compared our method against the existing relation linking systems on four different datasets derived from DBpedia and Wikidata. Our method reports large improvements over the state-of-the-art while using a much simpler model that can be easily adapted to different knowledge bases.
AIT-QA: Question Answering Dataset over Complex Tables in the Airline Industry
Jun 24, 2021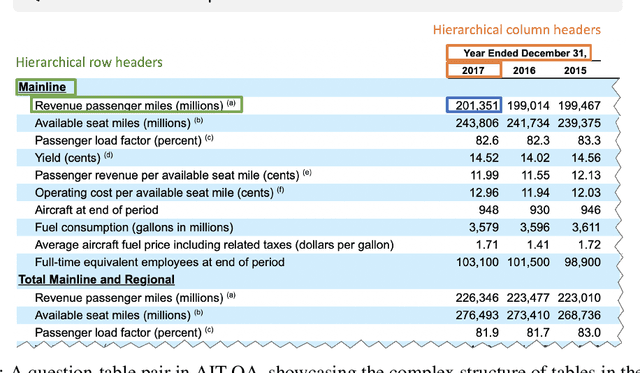
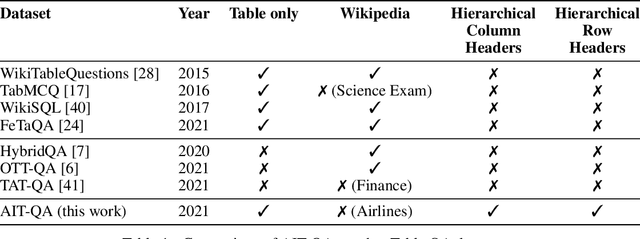
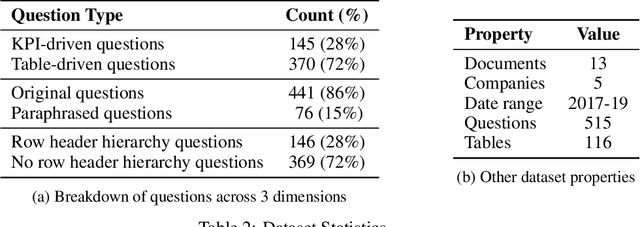
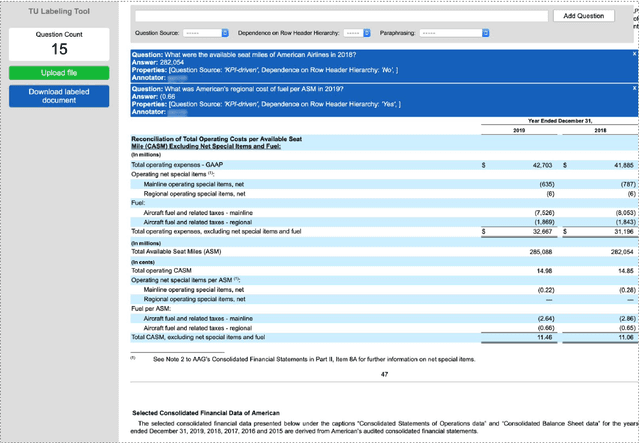
Recent advances in transformers have enabled Table Question Answering (Table QA) systems to achieve high accuracy and SOTA results on open domain datasets like WikiTableQuestions and WikiSQL. Such transformers are frequently pre-trained on open-domain content such as Wikipedia, where they effectively encode questions and corresponding tables from Wikipedia as seen in Table QA dataset. However, web tables in Wikipedia are notably flat in their layout, with the first row as the sole column header. The layout lends to a relational view of tables where each row is a tuple. Whereas, tables in domain-specific business or scientific documents often have a much more complex layout, including hierarchical row and column headers, in addition to having specialized vocabulary terms from that domain. To address this problem, we introduce the domain-specific Table QA dataset AIT-QA (Airline Industry Table QA). The dataset consists of 515 questions authored by human annotators on 116 tables extracted from public U.S. SEC filings (publicly available at: https://www.sec.gov/edgar.shtml) of major airline companies for the fiscal years 2017-2019. We also provide annotations pertaining to the nature of questions, marking those that require hierarchical headers, domain-specific terminology, and paraphrased forms. Our zero-shot baseline evaluation of three transformer-based SOTA Table QA methods - TaPAS (end-to-end), TaBERT (semantic parsing-based), and RCI (row-column encoding-based) - clearly exposes the limitation of these methods in this practical setting, with the best accuracy at just 51.8\% (RCI). We also present pragmatic table preprocessing steps used to pivot and project these complex tables into a layout suitable for the SOTA Table QA models.
CLTR: An End-to-End, Transformer-Based System for Cell Level Table Retrieval and Table Question Answering
Jun 09, 2021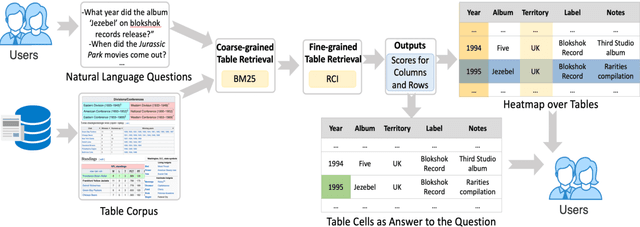
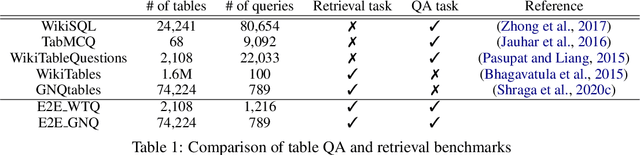
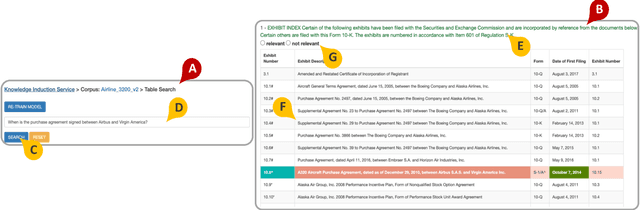
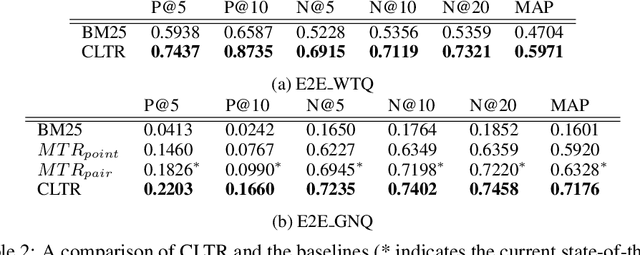
We present the first end-to-end, transformer-based table question answering (QA) system that takes natural language questions and massive table corpus as inputs to retrieve the most relevant tables and locate the correct table cells to answer the question. Our system, CLTR, extends the current state-of-the-art QA over tables model to build an end-to-end table QA architecture. This system has successfully tackled many real-world table QA problems with a simple, unified pipeline. Our proposed system can also generate a heatmap of candidate columns and rows over complex tables and allow users to quickly identify the correct cells to answer questions. In addition, we introduce two new open-domain benchmarks, E2E_WTQ and E2E_GNQ, consisting of 2,005 natural language questions over 76,242 tables. The benchmarks are designed to validate CLTR as well as accommodate future table retrieval and end-to-end table QA research and experiments. Our experiments demonstrate that our system is the current state-of-the-art model on the table retrieval task and produces promising results for end-to-end table QA.
Capturing Row and Column Semantics in Transformer Based Question Answering over Tables
Apr 26, 2021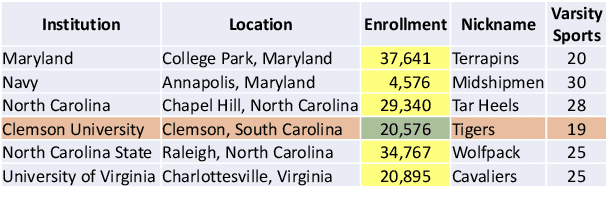
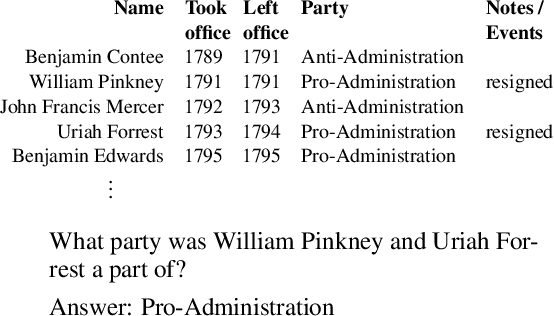
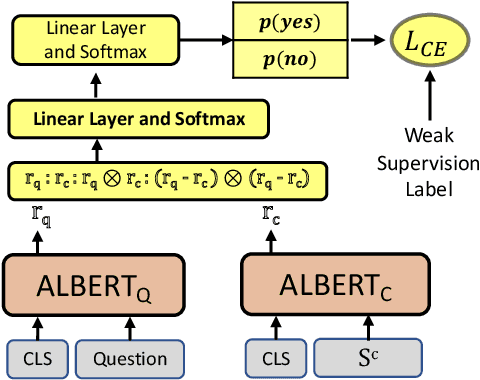
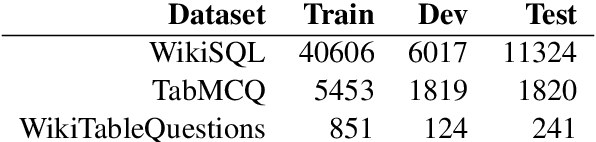
Transformer based architectures are recently used for the task of answering questions over tables. In order to improve the accuracy on this task, specialized pre-training techniques have been developed and applied on millions of open-domain web tables. In this paper, we propose two novel approaches demonstrating that one can achieve superior performance on table QA task without even using any of these specialized pre-training techniques. The first model, called RCI interaction, leverages a transformer based architecture that independently classifies rows and columns to identify relevant cells. While this model yields extremely high accuracy at finding cell values on recent benchmarks, a second model we propose, called RCI representation, provides a significant efficiency advantage for online QA systems over tables by materializing embeddings for existing tables. Experiments on recent benchmarks prove that the proposed methods can effectively locate cell values on tables (up to ~98% Hit@1 accuracy on WikiSQL lookup questions). Also, the interaction model outperforms the state-of-the-art transformer based approaches, pre-trained on very large table corpora (TAPAS and TaBERT), achieving ~3.4% and ~18.86% additional precision improvement on the standard WikiSQL benchmark.
Zero-shot Slot Filling with DPR and RAG
Apr 17, 2021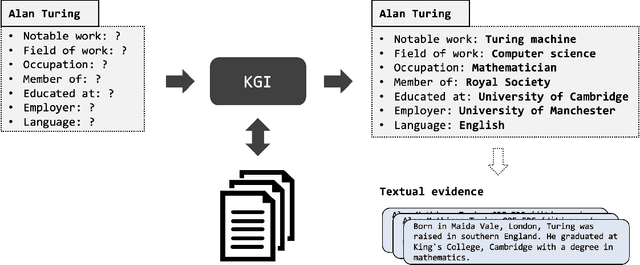

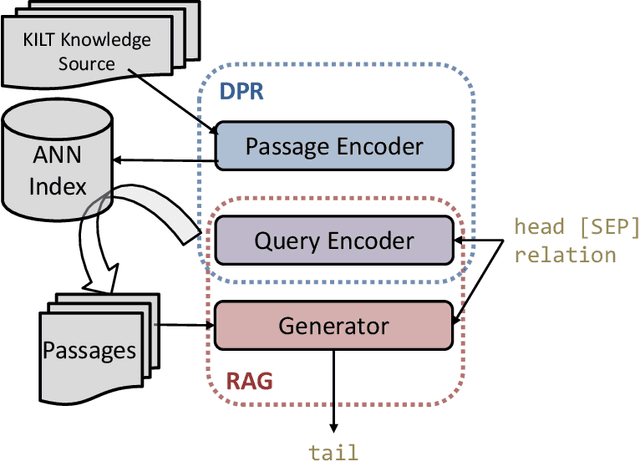
The ability to automatically extract Knowledge Graphs (KG) from a given collection of documents is a long-standing problem in Artificial Intelligence. One way to assess this capability is through the task of slot filling. Given an entity query in form of [Entity, Slot, ?], a system is asked to `fill' the slot by generating or extracting the missing value from a relevant passage or passages. This capability is crucial to create systems for automatic knowledge base population, which is becoming in ever-increasing demand, especially in enterprise applications. Recently, there has been a promising direction in evaluating language models in the same way we would evaluate knowledge bases, and the task of slot filling is the most suitable to this intent. The recent advancements in the field try to solve this task in an end-to-end fashion using retrieval-based language models. Models like Retrieval Augmented Generation (RAG) show surprisingly good performance without involving complex information extraction pipelines. However, the results achieved by these models on the two slot filling tasks in the KILT benchmark are still not at the level required by real-world information extraction systems. In this paper, we describe several strategies we adopted to improve the retriever and the generator of RAG in order to make it a better slot filler. Our KGI0 system (available at https://github.com/IBM/retrieve-write-slot-filling) reached the top-1 position on the KILT leaderboard on both T-REx and zsRE dataset with a large margin.
Type Prediction Systems
Apr 02, 2021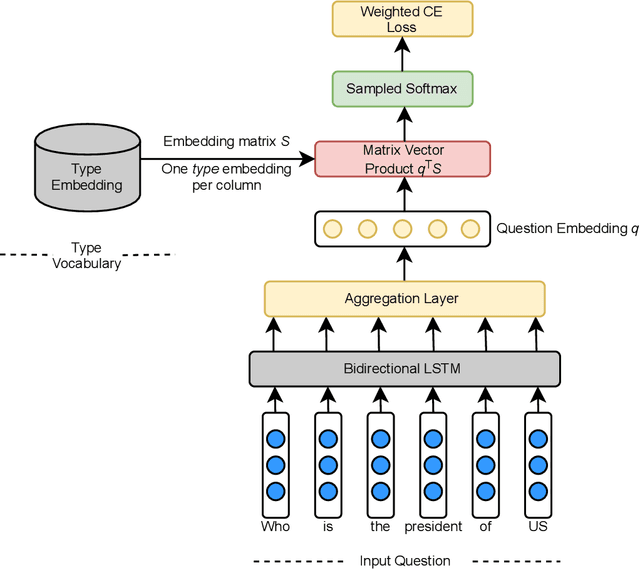
Inferring semantic types for entity mentions within text documents is an important asset for many downstream NLP tasks, such as Semantic Role Labelling, Entity Disambiguation, Knowledge Base Question Answering, etc. Prior works have mostly focused on supervised solutions that generally operate on relatively small-to-medium-sized type systems. In this work, we describe two systems aimed at predicting type information for the following two tasks, namely, a TypeSuggest module, an unsupervised system designed to predict types for a set of user-entered query terms, and an Answer Type prediction module, that provides a solution for the task of determining the correct type of the answer expected to a given query. Our systems generalize to arbitrary type systems of any sizes, thereby making it a highly appealing solution to extract type information at any granularity.
Joint Entity and Relation Canonicalization in Open Knowledge Graphs using Variational Autoencoders
Dec 08, 2020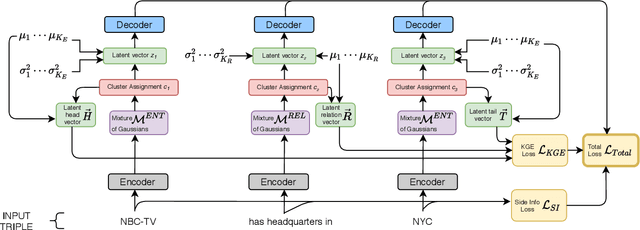

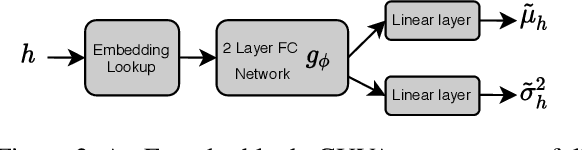
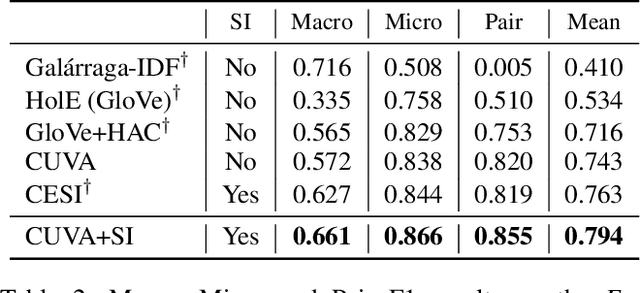
Noun phrases and relation phrases in open knowledge graphs are not canonicalized, leading to an explosion of redundant and ambiguous subject-relation-object triples. Existing approaches to face this problem take a two-step approach: first, they generate embedding representations for both noun and relation phrases, then a clustering algorithm is used to group them using the embeddings as features. In this work, we propose Canonicalizing Using Variational AutoEncoders (CUVA), a joint model to learn both embeddings and cluster assignments in an end-to-end approach, which leads to a better vector representation for the noun and relation phrases. Our evaluation over multiple benchmarks shows that CUVA outperforms the existing state of the art approaches. Moreover, we introduce CanonicNell a novel dataset to evaluate entity canonicalization systems.