 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-LCB: Extending LiveCodeBench to Multiple Programming Languages
Jun 18, 2026LiveCodeBench (LCB) has recently become a widely adopted benchmark for evaluating large language models (LLMs) on code-generation tasks. By curating competitive programming problems, constantly adding fresh problems to the set, and filtering them by release dates, LCB provides contamination-aware evaluation and offers a holistic view of coding capability. However, LCB remains restricted to Python, leaving open the question of whether LLMs can generalize across the diverse programming languages required in real-world software engineering. We introduce Multi-LCB, a benchmark for evaluating LLMs across twelve programming languages, including Python. Multi-LCB transforms Python tasks from the LCB dataset into equivalent tasks in other languages while preserving LCB's contamination controls and evaluation protocol. Because it is fully compatible with the original LCB format, Multi-LCB will automatically track future LCB updates, enabling systematic assessment of cross-language code generation competence and requiring models to sustain performance well beyond Python. We evaluated 24 LLMs for instruction and reasoning on Multi-LCB, uncovering evidence of Python overfitting, language-specific contamination, and substantial disparities in multilingual performance. Our results establish Multi-LCB as a rigorous new benchmark for multi-programming-language code evaluation, directly addressing LCB's primary limitation and exposing critical gaps in current LLM capabilities.
Investigating on RLHF methodology
Oct 02, 2024In this article, we investigate the alignment of Large Language Models according to human preferences. We discuss the features of training a Preference Model, which simulates human preferences, and the methods and details we found essential for achieving the best results. We also discuss using Reinforcement Learning to fine-tune Large Language Models and describe the challenges we faced and the ways to overcome them. Additionally, we present our experience with the Direct Preference Optimization method, which enables us to align a Large Language Model with human preferences without creating a separate Preference Model. As our contribution, we introduce the approach for collecting a preference dataset through perplexity filtering, which makes the process of creating such a dataset for a specific Language Model much easier and more cost-effective.
Empirical investigations on WVA structural issues
Aug 14, 2022
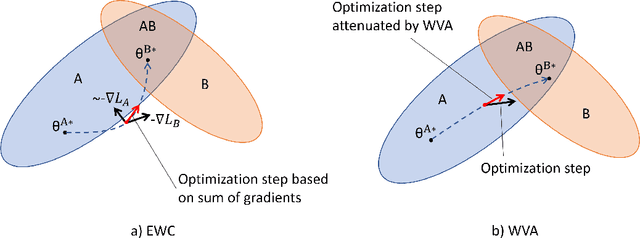
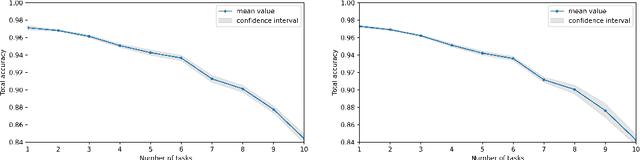
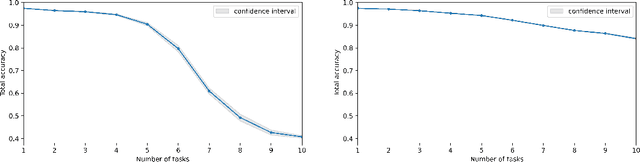
In this paper we want to present the results of empirical verification of some issues concerning the methods for overcoming catastrophic forgetting in neural networks. First, in the introduction, we will try to describe in detail the problem of catastrophic forgetting and methods for overcoming it for those who are not yet familiar with this topic. Then we will discuss the essence and limitations of the WVA method which we presented in previous papers. Further, we will touch upon the issues of applying the WVA method to gradients or optimization steps of weights, choosing the optimal attenuation function in this method, as well as choosing the optimal hyper-parameters of the method depending on the number of tasks in sequential training of neural networks.
Stabilizing Elastic Weight Consolidation method in practical ML tasks and using weight importances for neural network pruning
Sep 27, 2021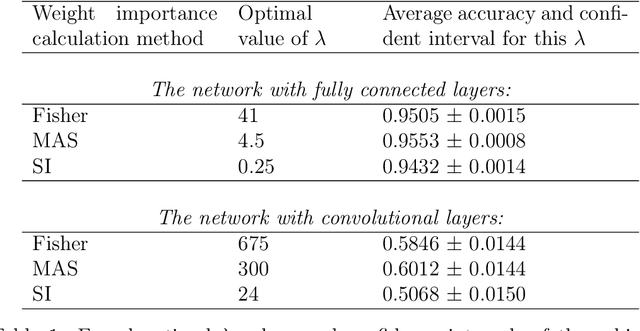
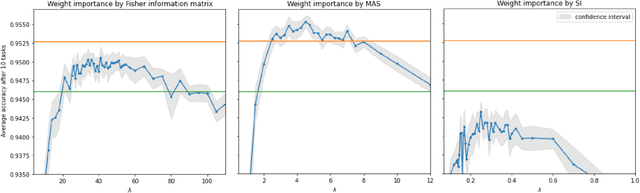
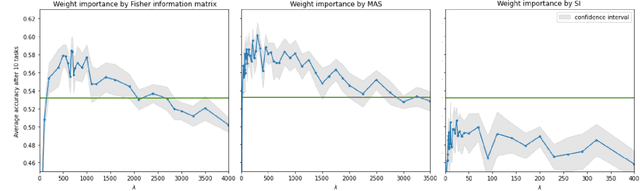
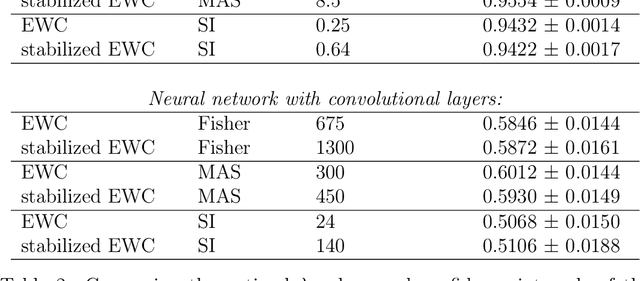
This paper is devoted to the features of the practical application of Elastic Weight Consolidation method. Here we will more rigorously compare the known methodologies for calculating the importance of weights when applied to networks with fully connected and convolutional layers. We will also point out the problems that arise when applying the Elastic Weight Consolidation method in multilayer neural networks with convolutional layers and self-attention layers, and propose method to overcome these problems. In addition, we will notice an interesting fact about the use of various types of weight importance in the neural network pruning task.
Natural Way to Overcome the Catastrophic Forgetting in Neural Networks
Apr 27, 2020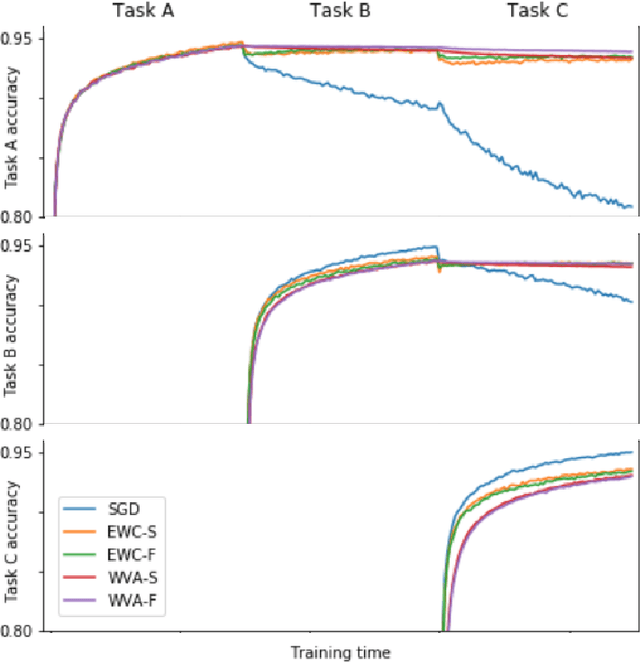
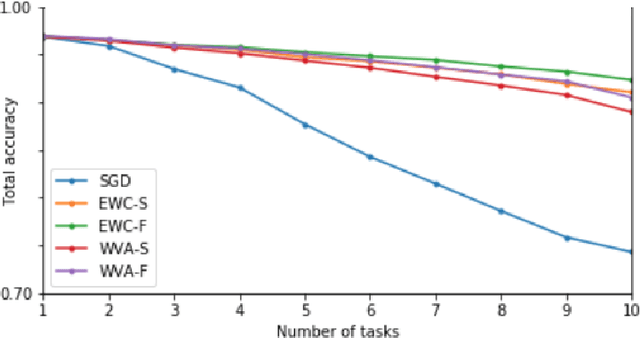
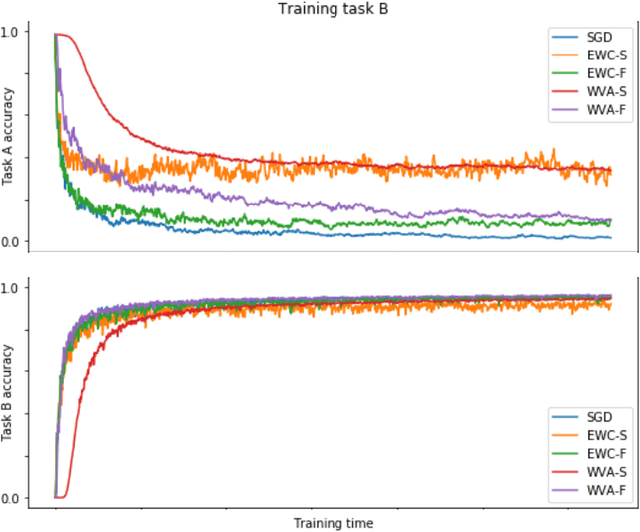
Not so long ago, a method was discovered that successfully overcomes the catastrophic forgetting of neural networks. Although we know about the cases of using this method to preserve skills when adapting pre-trained networks to particular tasks, it has not yet obtained widespread distribution. In this paper, we would like to propose an alternative method of overcoming catastrophic forgetting based on the total absolute signal passing through each connection in the network. This method has a simple implementation and seems to us essentially close to the processes occurring in the brain of animals to preserve previously learned skills during subsequent learning. We hope that the ease of implementation of this method will serve its wide application.