 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn Approximation Guarantees for Greedy Low Rank Optimization
Mar 08, 2017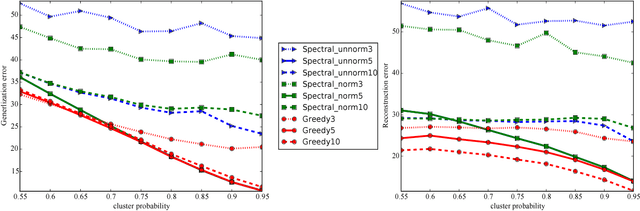
We provide new approximation guarantees for greedy low rank matrix estimation under standard assumptions of restricted strong convexity and smoothness. Our novel analysis also uncovers previously unknown connections between the low rank estimation and combinatorial optimization, so much so that our bounds are reminiscent of corresponding approximation bounds in submodular maximization. Additionally, we also provide statistical recovery guarantees. Finally, we present empirical comparison of greedy estimation with established baselines on two important real-world problems.
Leveraging Sparsity for Efficient Submodular Data Summarization
Mar 08, 2017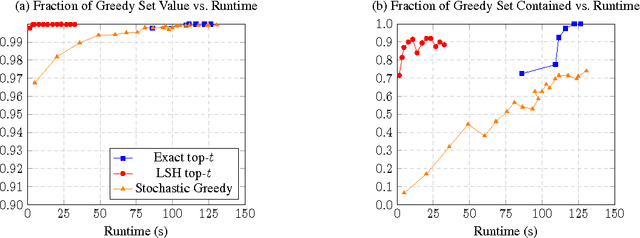
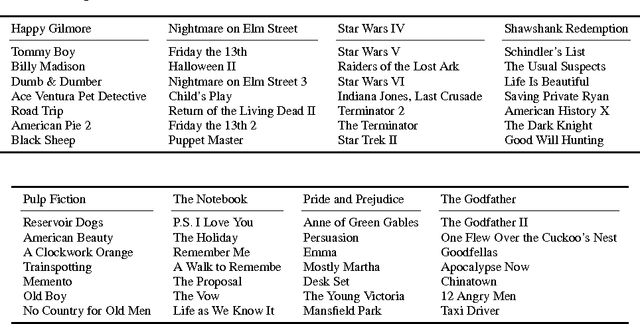
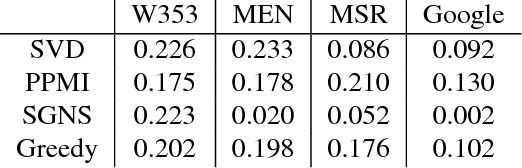
The facility location problem is widely used for summarizing large datasets and has additional applications in sensor placement, image retrieval, and clustering. One difficulty of this problem is that submodular optimization algorithms require the calculation of pairwise benefits for all items in the dataset. This is infeasible for large problems, so recent work proposed to only calculate nearest neighbor benefits. One limitation is that several strong assumptions were invoked to obtain provable approximation guarantees. In this paper we establish that these extra assumptions are not necessary---solving the sparsified problem will be almost optimal under the standard assumptions of the problem. We then analyze a different method of sparsification that is a better model for methods such as Locality Sensitive Hashing to accelerate the nearest neighbor computations and extend the use of the problem to a broader family of similarities. We validate our approach by demonstrating that it rapidly generates interpretable summaries.
Exact MAP Inference by Avoiding Fractional Vertices
Mar 08, 2017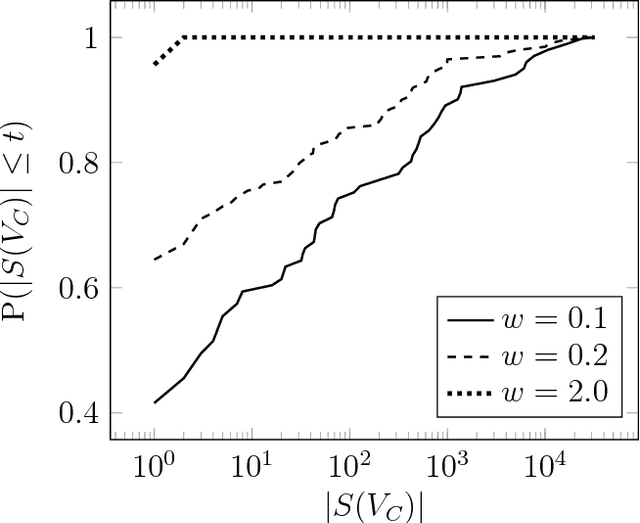



Given a graphical model, one essential problem is MAP inference, that is, finding the most likely configuration of states according to the model. Although this problem is NP-hard, large instances can be solved in practice. A major open question is to explain why this is true. We give a natural condition under which we can provably perform MAP inference in polynomial time. We require that the number of fractional vertices in the LP relaxation exceeding the optimal solution is bounded by a polynomial in the problem size. This resolves an open question by Dimakis, Gohari, and Wainwright. In contrast, for general LP relaxations of integer programs, known techniques can only handle a constant number of fractional vertices whose value exceeds the optimal solution. We experimentally verify this condition and demonstrate how efficient various integer programming methods are at removing fractional solutions.
Sparse Quadratic Logistic Regression in Sub-quadratic Time
Mar 08, 2017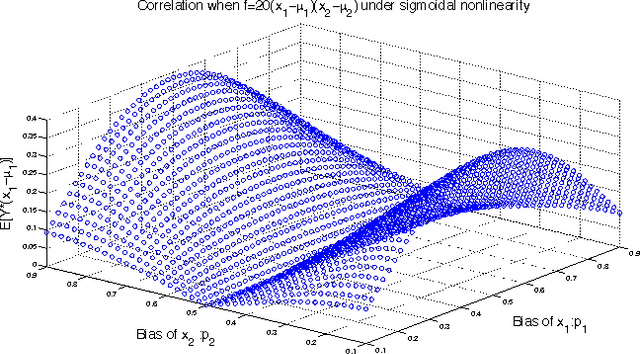

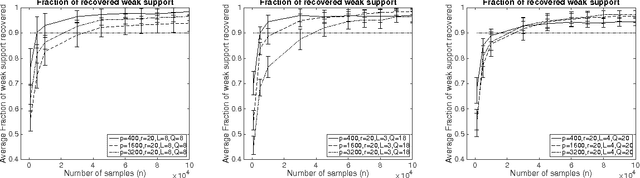

We consider support recovery in the quadratic logistic regression setting - where the target depends on both p linear terms $x_i$ and up to $p^2$ quadratic terms $x_i x_j$. Quadratic terms enable prediction/modeling of higher-order effects between features and the target, but when incorporated naively may involve solving a very large regression problem. We consider the sparse case, where at most $s$ terms (linear or quadratic) are non-zero, and provide a new faster algorithm. It involves (a) identifying the weak support (i.e. all relevant variables) and (b) standard logistic regression optimization only on these chosen variables. The first step relies on a novel insight about correlation tests in the presence of non-linearity, and takes $O(pn)$ time for $n$ samples - giving potentially huge computational gains over the naive approach. Motivated by insights from the boolean case, we propose a non-linear correlation test for non-binary finite support case that involves hashing a variable and then correlating with the output variable. We also provide experimental results to demonstrate the effectiveness of our methods.
Gradient Coding
Mar 08, 2017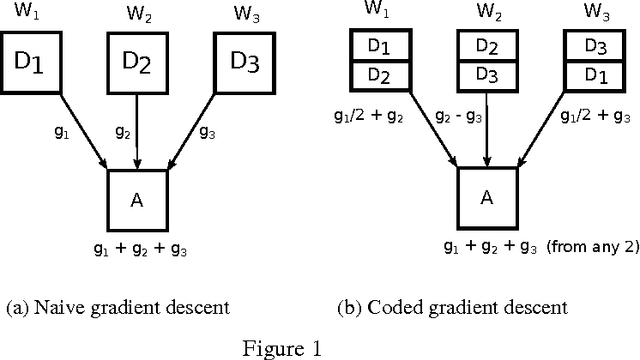
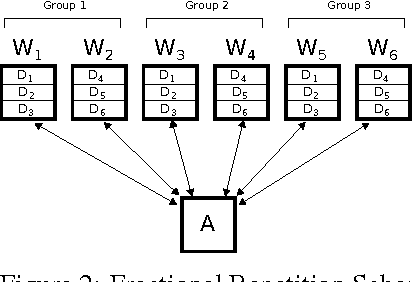
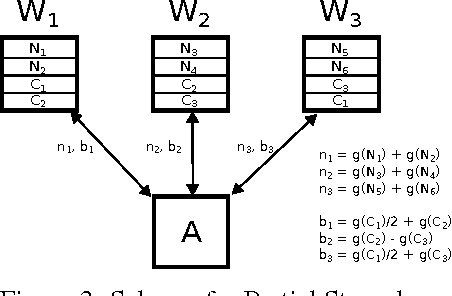
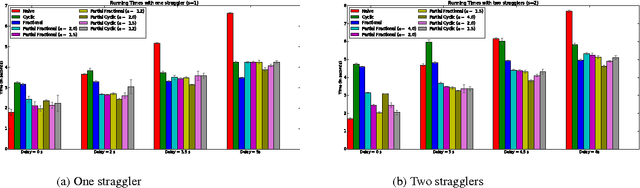
We propose a novel coding theoretic framework for mitigating stragglers in distributed learning. We show how carefully replicating data blocks and coding across gradients can provide tolerance to failures and stragglers for Synchronous Gradient Descent. We implement our schemes in python (using MPI) to run on Amazon EC2, and show how we compare against baseline approaches in running time and generalization error.
Cost-Optimal Learning of Causal Graphs
Mar 08, 2017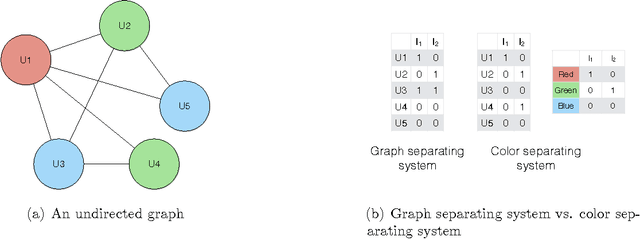
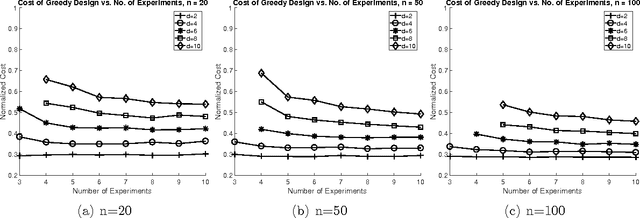
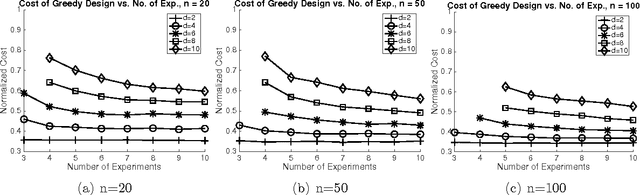
We consider the problem of learning a causal graph over a set of variables with interventions. We study the cost-optimal causal graph learning problem: For a given skeleton (undirected version of the causal graph), design the set of interventions with minimum total cost, that can uniquely identify any causal graph with the given skeleton. We show that this problem is solvable in polynomial time. Later, we consider the case when the number of interventions is limited. For this case, we provide polynomial time algorithms when the skeleton is a tree or a clique tree. For a general chordal skeleton, we develop an efficient greedy algorithm, which can be improved when the causal graph skeleton is an interval graph.
Entropic Causality and Greedy Minimum Entropy Coupling
Jan 28, 2017We study the problem of identifying the causal relationship between two discrete random variables from observational data. We recently proposed a novel framework called entropic causality that works in a very general functional model but makes the assumption that the unobserved exogenous variable has small entropy in the true causal direction. This framework requires the solution of a minimum entropy coupling problem: Given marginal distributions of m discrete random variables, each on n states, find the joint distribution with minimum entropy, that respects the given marginals. This corresponds to minimizing a concave function of nm variables over a convex polytope defined by nm linear constraints, called a transportation polytope. Unfortunately, it was recently shown that this minimum entropy coupling problem is NP-hard, even for 2 variables with n states. Even representing points (joint distributions) over this space can require exponential complexity (in n, m) if done naively. In our recent work we introduced an efficient greedy algorithm to find an approximate solution for this problem. In this paper we analyze this algorithm and establish two results: that our algorithm always finds a local minimum and also is within an additive approximation error from the unknown global optimum.
Entropic Causal Inference
Nov 15, 2016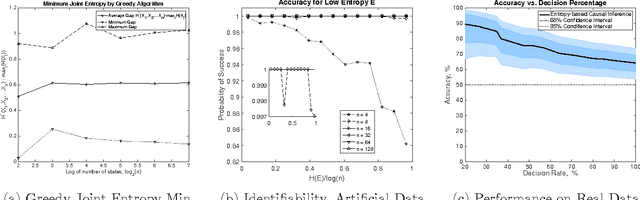
We consider the problem of identifying the causal direction between two discrete random variables using observational data. Unlike previous work, we keep the most general functional model but make an assumption on the unobserved exogenous variable: Inspired by Occam's razor, we assume that the exogenous variable is simple in the true causal direction. We quantify simplicity using R\'enyi entropy. Our main result is that, under natural assumptions, if the exogenous variable has low $H_0$ entropy (cardinality) in the true direction, it must have high $H_0$ entropy in the wrong direction. We establish several algorithmic hardness results about estimating the minimum entropy exogenous variable. We show that the problem of finding the exogenous variable with minimum entropy is equivalent to the problem of finding minimum joint entropy given $n$ marginal distributions, also known as minimum entropy coupling problem. We propose an efficient greedy algorithm for the minimum entropy coupling problem, that for $n=2$ provably finds a local optimum. This gives a greedy algorithm for finding the exogenous variable with minimum $H_1$ (Shannon Entropy). Our greedy entropy-based causal inference algorithm has similar performance to the state of the art additive noise models in real datasets. One advantage of our approach is that we make no use of the values of random variables but only their distributions. Our method can therefore be used for causal inference for both ordinal and also categorical data, unlike additive noise models.
Contextual Bandits with Latent Confounders: An NMF Approach
Oct 27, 2016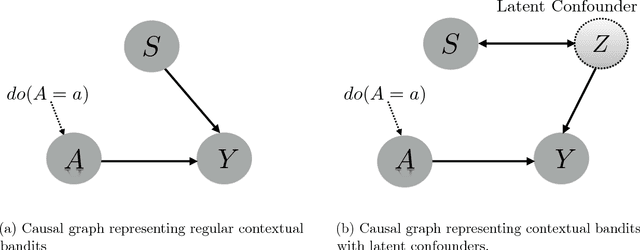
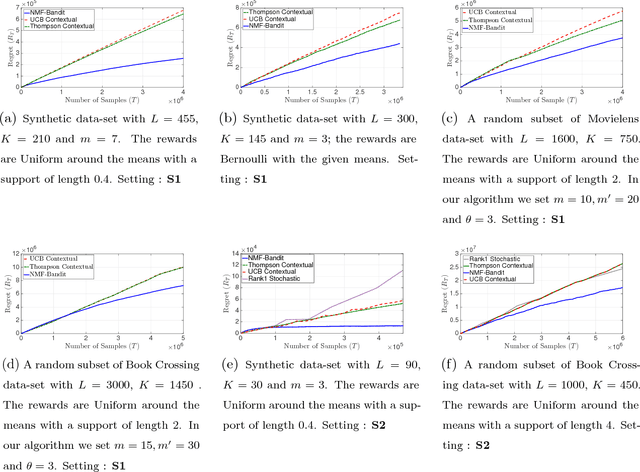
Motivated by online recommendation and advertising systems, we consider a causal model for stochastic contextual bandits with a latent low-dimensional confounder. In our model, there are $L$ observed contexts and $K$ arms of the bandit. The observed context influences the reward obtained through a latent confounder variable with cardinality $m$ ($m \ll L,K$). The arm choice and the latent confounder causally determines the reward while the observed context is correlated with the confounder. Under this model, the $L \times K$ mean reward matrix $\mathbf{U}$ (for each context in $[L]$ and each arm in $[K]$) factorizes into non-negative factors $\mathbf{A}$ ($L \times m$) and $\mathbf{W}$ ($m \times K$). This insight enables us to propose an $\epsilon$-greedy NMF-Bandit algorithm that designs a sequence of interventions (selecting specific arms), that achieves a balance between learning this low-dimensional structure and selecting the best arm to minimize regret. Our algorithm achieves a regret of $\mathcal{O}\left(L\mathrm{poly}(m, \log K) \log T \right)$ at time $T$, as compared to $\mathcal{O}(LK\log T)$ for conventional contextual bandits, assuming a constant gap between the best arm and the rest for each context. These guarantees are obtained under mild sufficiency conditions on the factors that are weaker versions of the well-known Statistical RIP condition. We further propose a class of generative models that satisfy our sufficient conditions, and derive a lower bound of $\mathcal{O}\left(Km\log T\right)$. These are the first regret guarantees for online matrix completion with bandit feedback, when the rank is greater than one. We further compare the performance of our algorithm with the state of the art, on synthetic and real world data-sets.
Single Pass PCA of Matrix Products
Oct 26, 2016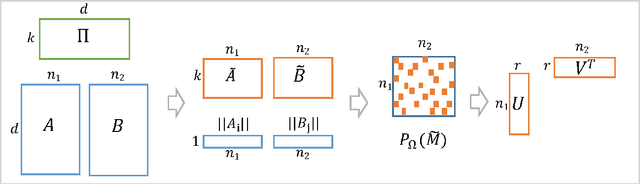
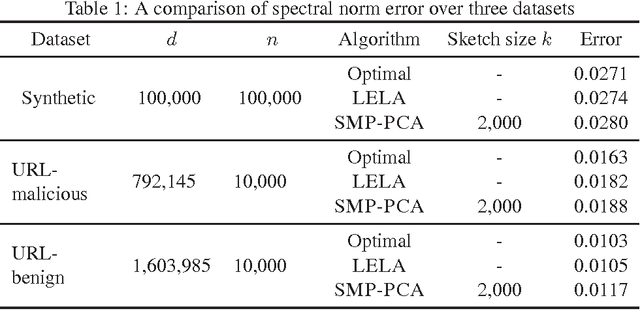
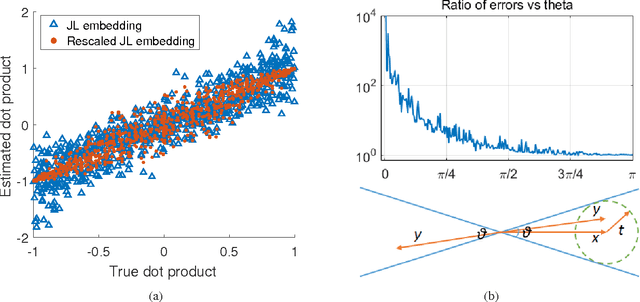
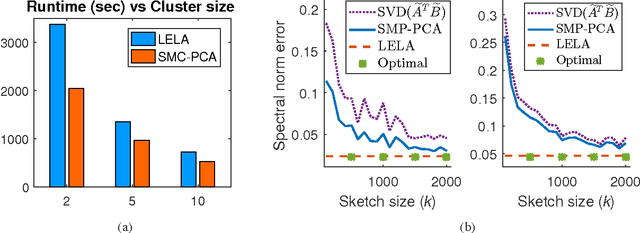
In this paper we present a new algorithm for computing a low rank approximation of the product $A^TB$ by taking only a single pass of the two matrices $A$ and $B$. The straightforward way to do this is to (a) first sketch $A$ and $B$ individually, and then (b) find the top components using PCA on the sketch. Our algorithm in contrast retains additional summary information about $A,B$ (e.g. row and column norms etc.) and uses this additional information to obtain an improved approximation from the sketches. Our main analytical result establishes a comparable spectral norm guarantee to existing two-pass methods; in addition we also provide results from an Apache Spark implementation that shows better computational and statistical performance on real-world and synthetic evaluation datasets.