 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrom Discrete Tokens to High-Fidelity Audio Using Multi-Band Diffusion
Aug 02, 2023



Deep generative models can generate high-fidelity audio conditioned on various types of representations (e.g., mel-spectrograms, Mel-frequency Cepstral Coefficients (MFCC)). Recently, such models have been used to synthesize audio waveforms conditioned on highly compressed representations. Although such methods produce impressive results, they are prone to generate audible artifacts when the conditioning is flawed or imperfect. An alternative modeling approach is to use diffusion models. However, these have mainly been used as speech vocoders (i.e., conditioned on mel-spectrograms) or generating relatively low sampling rate signals. In this work, we propose a high-fidelity multi-band diffusion-based framework that generates any type of audio modality (e.g., speech, music, environmental sounds) from low-bitrate discrete representations. At equal bit rate, the proposed approach outperforms state-of-the-art generative techniques in terms of perceptual quality. Training and, evaluation code, along with audio samples, are available on the facebookresearch/audiocraft Github page.
Simple and Controllable Music Generation
Jun 08, 2023We tackle the task of conditional music generation. We introduce MusicGen, a single Language Model (LM) that operates over several streams of compressed discrete music representation, i.e., tokens. Unlike prior work, MusicGen is comprised of a single-stage transformer LM together with efficient token interleaving patterns, which eliminates the need for cascading several models, e.g., hierarchically or upsampling. Following this approach, we demonstrate how MusicGen can generate high-quality samples, while being conditioned on textual description or melodic features, allowing better controls over the generated output. We conduct extensive empirical evaluation, considering both automatic and human studies, showing the proposed approach is superior to the evaluated baselines on a standard text-to-music benchmark. Through ablation studies, we shed light over the importance of each of the components comprising MusicGen. Music samples, code, and models are available at https://github.com/facebookresearch/audiocraft.
Hybrid Transformers for Music Source Separation
Nov 15, 2022A natural question arising in Music Source Separation (MSS) is whether long range contextual information is useful, or whether local acoustic features are sufficient. In other fields, attention based Transformers have shown their ability to integrate information over long sequences. In this work, we introduce Hybrid Transformer Demucs (HT Demucs), an hybrid temporal/spectral bi-U-Net based on Hybrid Demucs, where the innermost layers are replaced by a cross-domain Transformer Encoder, using self-attention within one domain, and cross-attention across domains. While it performs poorly when trained only on MUSDB, we show that it outperforms Hybrid Demucs (trained on the same data) by 0.45 dB of SDR when using 800 extra training songs. Using sparse attention kernels to extend its receptive field, and per source fine-tuning, we achieve state-of-the-art results on MUSDB with extra training data, with 9.20 dB of SDR.
Audio Language Modeling using Perceptually-Guided Discrete Representations
Nov 04, 2022In this work, we study the task of Audio Language Modeling, in which we aim at learning probabilistic models for audio that can be used for generation and completion. We use a state-of-the-art perceptually-guided audio compression model, to encode audio to discrete representations. Next, we train a transformer-based causal language model using these representations. At inference time, we perform audio auto-completion by encoding an audio prompt as a discrete sequence, feeding it to the audio language model, sampling from the model, and synthesizing the corresponding time-domain signal. We evaluate the quality of samples generated by our method on Audioset, the largest dataset for general audio to date, and show that it is superior to the evaluated baseline audio encoders. We additionally provide an extensive analysis to better understand the trade-off between audio-quality and language-modeling capabilities. Samples:link.
High Fidelity Neural Audio Compression
Oct 24, 2022We introduce a state-of-the-art real-time, high-fidelity, audio codec leveraging neural networks. It consists in a streaming encoder-decoder architecture with quantized latent space trained in an end-to-end fashion. We simplify and speed-up the training by using a single multiscale spectrogram adversary that efficiently reduces artifacts and produce high-quality samples. We introduce a novel loss balancer mechanism to stabilize training: the weight of a loss now defines the fraction of the overall gradient it should represent, thus decoupling the choice of this hyper-parameter from the typical scale of the loss. Finally, we study how lightweight Transformer models can be used to further compress the obtained representation by up to 40%, while staying faster than real time. We provide a detailed description of the key design choices of the proposed model including: training objective, architectural changes and a study of various perceptual loss functions. We present an extensive subjective evaluation (MUSHRA tests) together with an ablation study for a range of bandwidths and audio domains, including speech, noisy-reverberant speech, and music. Our approach is superior to the baselines methods across all evaluated settings, considering both 24 kHz monophonic and 48 kHz stereophonic audio. Code and models are available at github.com/facebookresearch/encodec.
AudioGen: Textually Guided Audio Generation
Sep 30, 2022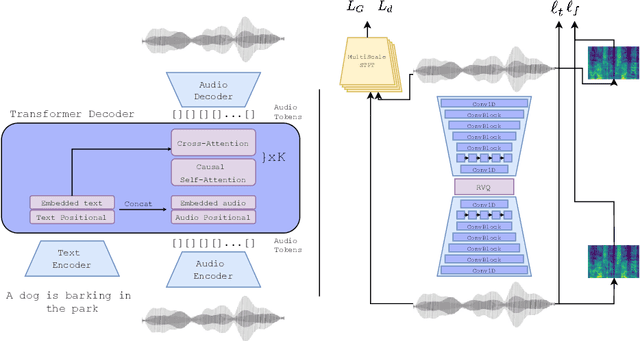
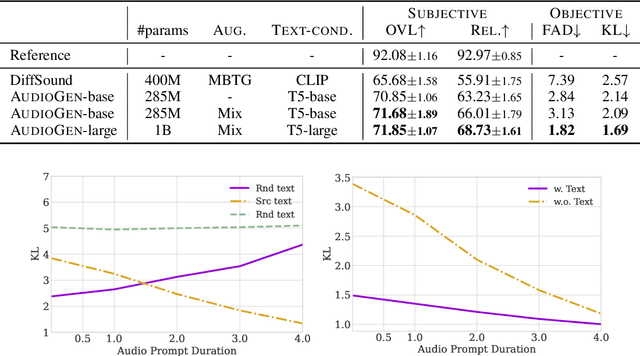
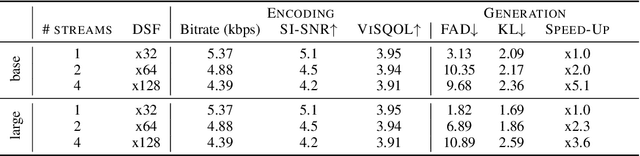
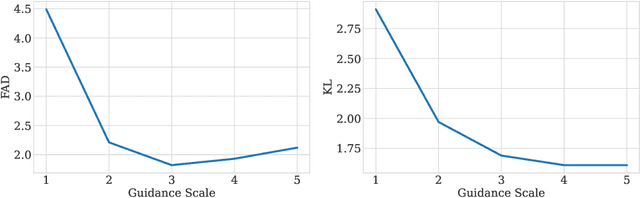
We tackle the problem of generating audio samples conditioned on descriptive text captions. In this work, we propose AaudioGen, an auto-regressive generative model that generates audio samples conditioned on text inputs. AudioGen operates on a learnt discrete audio representation. The task of text-to-audio generation poses multiple challenges. Due to the way audio travels through a medium, differentiating ``objects'' can be a difficult task (e.g., separating multiple people simultaneously speaking). This is further complicated by real-world recording conditions (e.g., background noise, reverberation, etc.). Scarce text annotations impose another constraint, limiting the ability to scale models. Finally, modeling high-fidelity audio requires encoding audio at high sampling rate, leading to extremely long sequences. To alleviate the aforementioned challenges we propose an augmentation technique that mixes different audio samples, driving the model to internally learn to separate multiple sources. We curated 10 datasets containing different types of audio and text annotations to handle the scarcity of text-audio data points. For faster inference, we explore the use of multi-stream modeling, allowing the use of shorter sequences while maintaining a similar bitrate and perceptual quality. We apply classifier-free guidance to improve adherence to text. Comparing to the evaluated baselines, AudioGen outperforms over both objective and subjective metrics. Finally, we explore the ability of the proposed method to generate audio continuation conditionally and unconditionally. Samples: https://tinyurl.com/audiogen-text2audio
Decoding speech from non-invasive brain recordings
Aug 25, 2022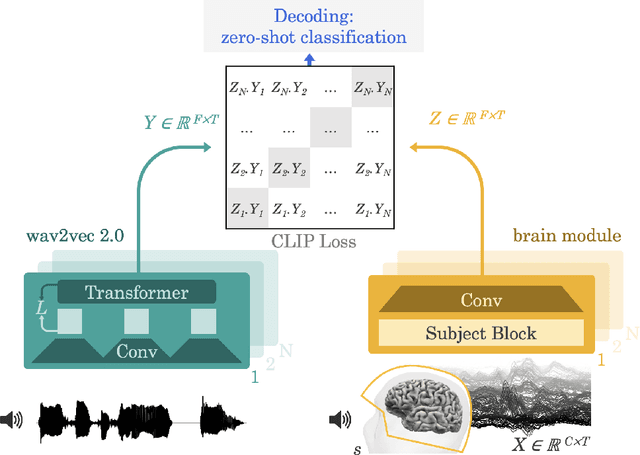

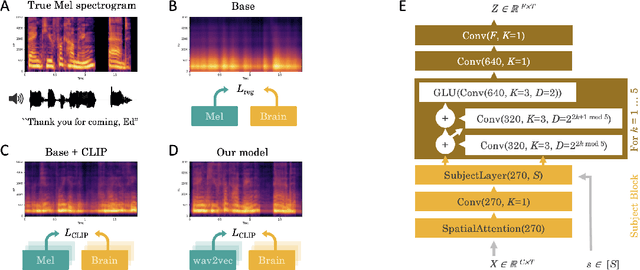

Decoding language from brain activity is a long-awaited goal in both healthcare and neuroscience. Major milestones have recently been reached thanks to intracranial devices: subject-specific pipelines trained on invasive brain responses to basic language tasks now start to efficiently decode interpretable features (e.g. letters, words, spectrograms). However, scaling this approach to natural speech and non-invasive brain recordings remains a major challenge. Here, we propose a single end-to-end architecture trained with contrastive learning across a large cohort of individuals to predict self-supervised representations of natural speech. We evaluate our model on four public datasets, encompassing 169 volunteers recorded with magneto- or electro-encephalography (M/EEG), while they listened to natural speech. The results show that our model can identify, from 3s of MEG signals, the corresponding speech segment with up to 72.5% top-10 accuracy out of 1,594 distinct segments (and 44% top-1 accuracy), and up to 19.1% out of 2,604 segments for EEG recordings -- hence allowing the decoding of phrases absent from the training set. Model comparison and ablation analyses show that these performances directly benefit from our original design choices, namely the use of (i) a contrastive objective, (ii) pretrained representations of speech and (iii) a common convolutional architecture simultaneously trained across several participants. Together, these results delineate a promising path to decode natural language processing in real time from non-invasive recordings of brain activity.
Hybrid Spectrogram and Waveform Source Separation
Nov 05, 2021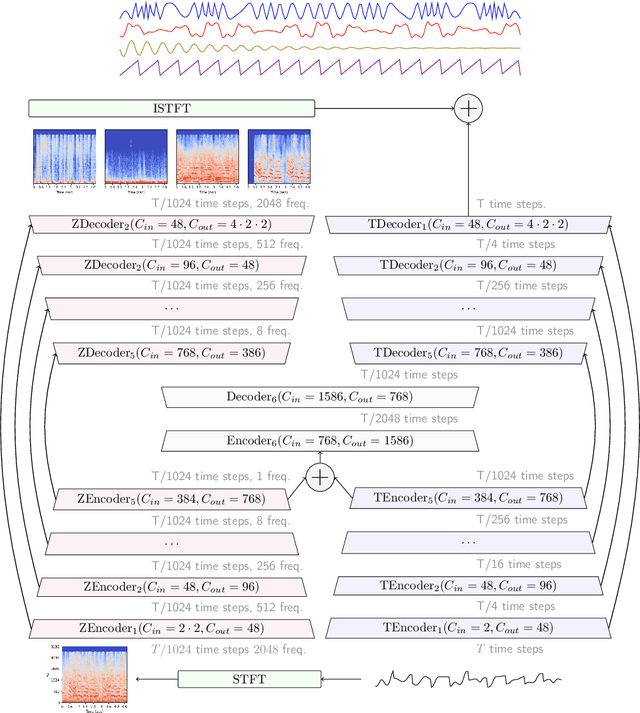
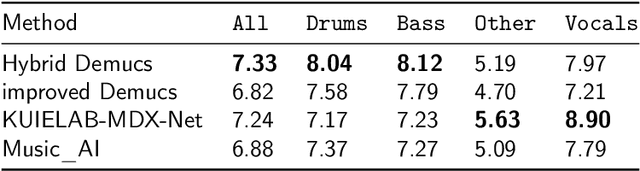
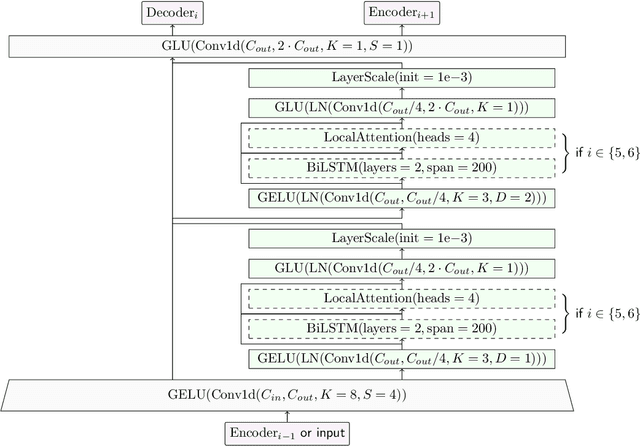
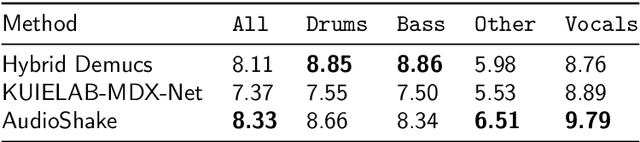
Source separation models either work on the spectrogram or waveform domain. In this work, we show how to perform end-to-end hybrid source separation, letting the model decide which domain is best suited for each source, and even combining both. The proposed hybrid version of the Demucs architecture won the Music Demixing Challenge 2021 organized by Sony. This architecture also comes with additional improvements, such as compressed residual branches, local attention or singular value regularization. Overall, a 1.4 dB improvement of the Signal-To-Distortion (SDR) was observed across all sources as measured on the MusDB HQ dataset, an improvement confirmed by human subjective evaluation, with an overall quality rated at 2.83 out of 5 (2.36 for the non hybrid Demucs), and absence of contamination at 3.04 (against 2.37 for the non hybrid Demucs and 2.44 for the second ranking model submitted at the competition).
Differentiable Model Compression via Pseudo Quantization Noise
Apr 20, 2021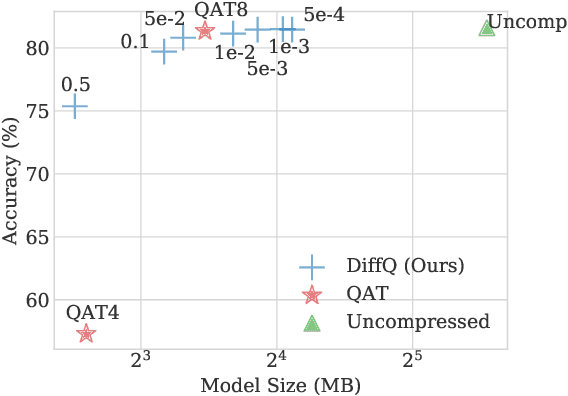
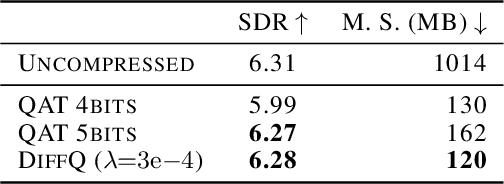
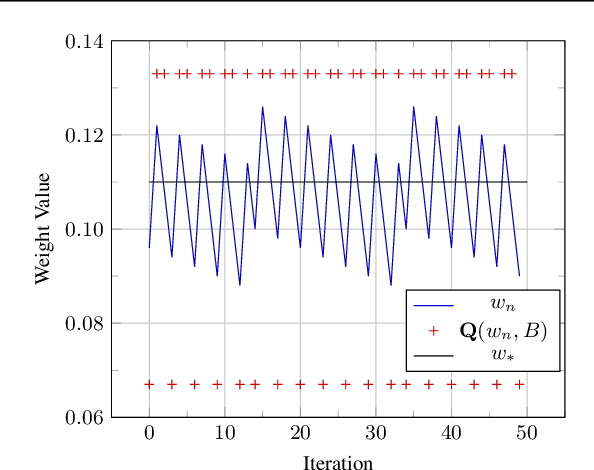
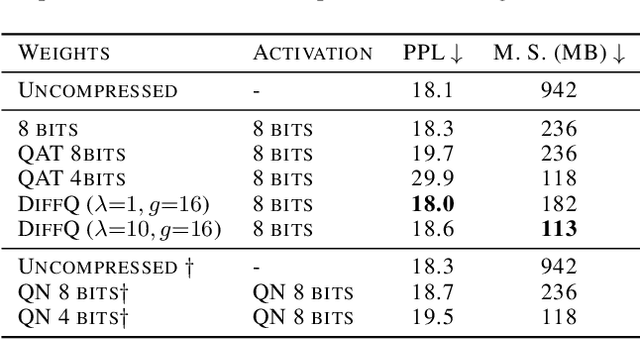
We propose to add independent pseudo quantization noise to model parameters during training to approximate the effect of a quantization operator. This method, DiffQ, is differentiable both with respect to the unquantized parameters, and the number of bits used. Given a single hyper-parameter expressing the desired balance between the quantized model size and accuracy, DiffQ can optimize the number of bits used per individual weight or groups of weights, in a single training. We experimentally verify that our method outperforms state-of-the-art quantization techniques on several benchmarks and architectures for image classification, language modeling, and audio source separation. For instance, on the Wikitext-103 language modeling benchmark, DiffQ compresses a 16 layers transformer model by a factor of 8, equivalent to 4 bits precision, while losing only 0.5 points of perplexity. Code is available at: https://github.com/facebookresearch/diffq
On the Convergence of Adam and Adagrad
Mar 05, 2020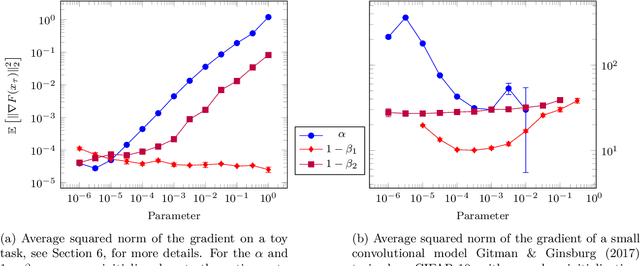
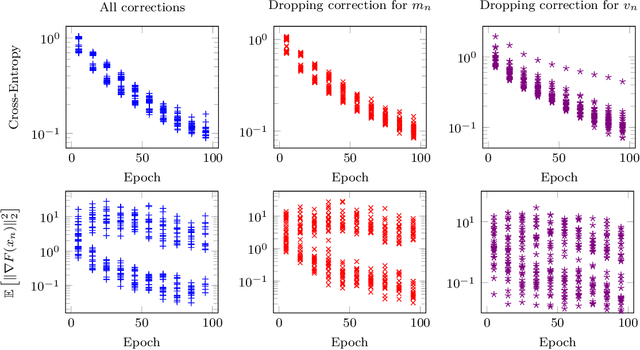
We provide a simple proof of the convergence of the optimization algorithms Adam and Adagrad with the assumptions of smooth gradients and almost sure uniform bound on the $\ell_\infty$ norm of the gradients. This work builds on the techniques introduced by Ward et al. (2019) and extends them to the Adam optimizer. We show that in expectation, the squared norm of the objective gradient averaged over the trajectory has an upper-bound which is explicit in the constants of the problem, parameters of the optimizer and the total number of iterations N. This bound can be made arbitrarily small. In particular, Adam with a learning rate $\alpha=1/\sqrt{N}$ and a momentum parameter on squared gradients $\beta_2=1 - 1/N$ achieves the same rate of convergence $O(\ln(N)/\sqrt{N})$ as Adagrad. Thus, it is possible to use Adam as a finite horizon version of Adagrad, much like constant step size SGD can be used instead of its asymptotically converging decaying step size version.