 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVulnerability Under Adversarial Machine Learning: Bias or Variance?
Aug 01, 2020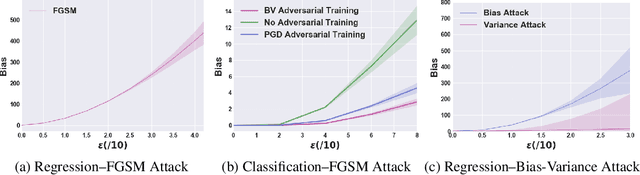
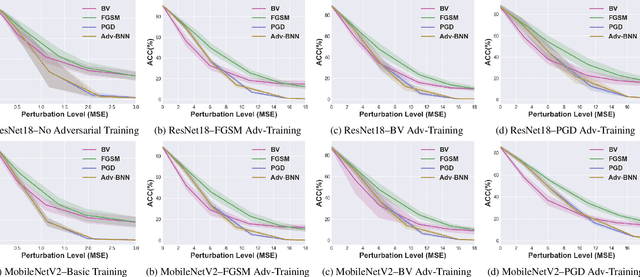
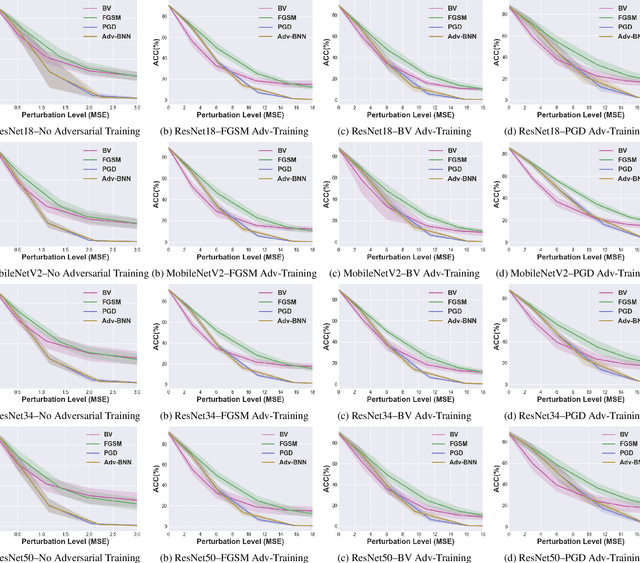
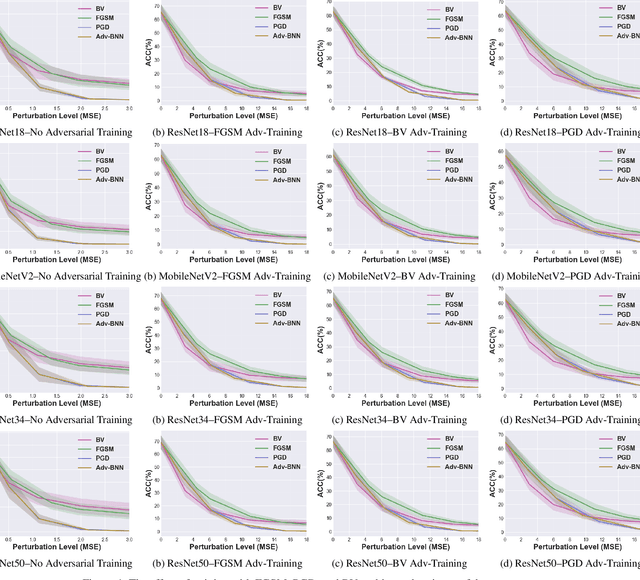
Prior studies have unveiled the vulnerability of the deep neural networks in the context of adversarial machine learning, leading to great recent attention into this area. One interesting question that has yet to be fully explored is the bias-variance relationship of adversarial machine learning, which can potentially provide deeper insights into this behaviour. The notion of bias and variance is one of the main approaches to analyze and evaluate the generalization and reliability of a machine learning model. Although it has been extensively used in other machine learning models, it is not well explored in the field of deep learning and it is even less explored in the area of adversarial machine learning. In this study, we investigate the effect of adversarial machine learning on the bias and variance of a trained deep neural network and analyze how adversarial perturbations can affect the generalization of a network. We derive the bias-variance trade-off for both classification and regression applications based on two main loss functions: (i) mean squared error (MSE), and (ii) cross-entropy. Furthermore, we perform quantitative analysis with both simulated and real data to empirically evaluate consistency with the derived bias-variance tradeoffs. Our analysis sheds light on why the deep neural networks have poor performance under adversarial perturbation from a bias-variance point of view and how this type of perturbation would change the performance of a network. Moreover, given these new theoretical findings, we introduce a new adversarial machine learning algorithm with lower computational complexity than well-known adversarial machine learning strategies (e.g., PGD) while providing a high success rate in fooling deep neural networks in lower perturbation magnitudes.
Understanding the temporal evolution of COVID-19 research through machine learning and natural language processing
Jul 22, 2020
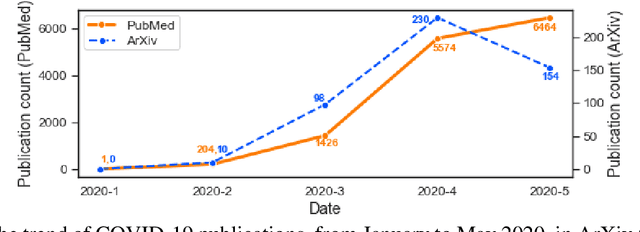
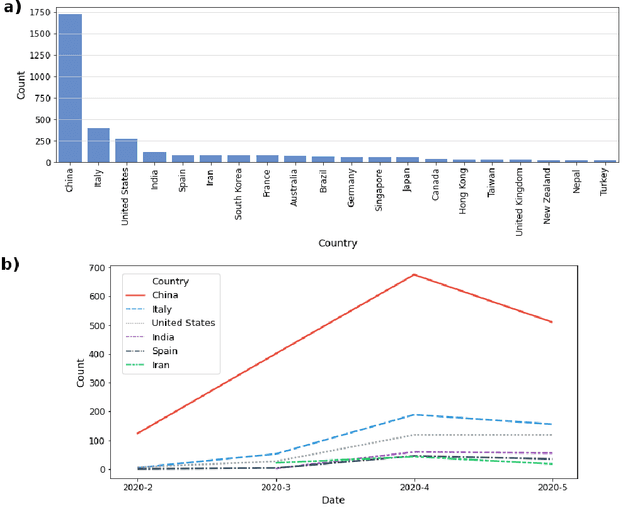
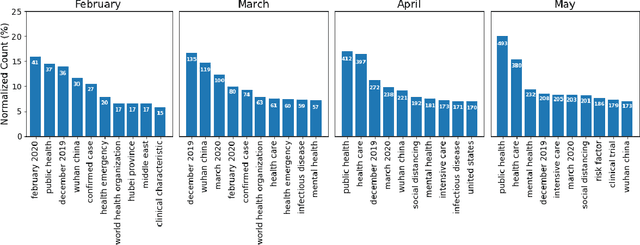
The outbreak of the novel coronavirus disease 2019 (COVID-19), caused by the severe acute respiratory syndrome coronavirus 2 (SARS-CoV-2) has been continuously affecting human lives and communities around the world in many ways, from cities under lockdown to new social experiences. Although in most cases COVID-19 results in mild illness, it has drawn global attention due to the extremely contagious nature of SARS-CoV-2. Governments and healthcare professionals, along with people and society as a whole, have taken any measures to break the chain of transition and flatten the epidemic curve. In this study, we used multiple data sources, i.e., PubMed and ArXiv, and built several machine learning models to characterize the landscape of current COVID-19 research by identifying the latent topics and analyzing the temporal evolution of the extracted research themes, publications similarity, and sentiments, within the time-frame of January- May 2020. Our findings confirm the types of research available in PubMed and ArXiv differ significantly, with the former exhibiting greater diversity in terms of COVID-19 related issues and the latter focusing more on intelligent systems/tools to predict/diagnose COVID-19. The special attention of the research community to the high-risk groups and people with complications was also confirmed.
Quantization in Relative Gradient Angle Domain For Building Polygon Estimation
Jul 10, 2020
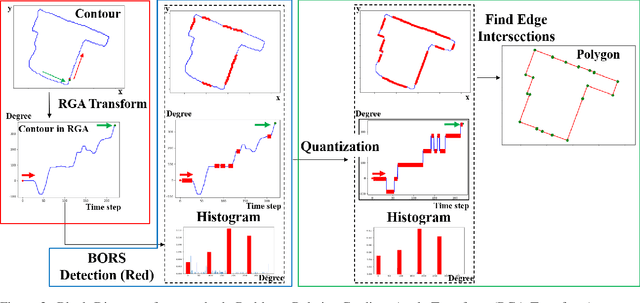
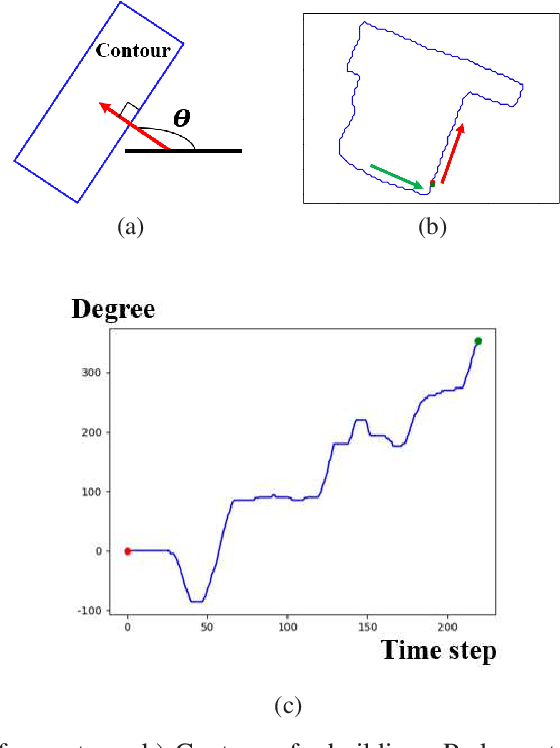
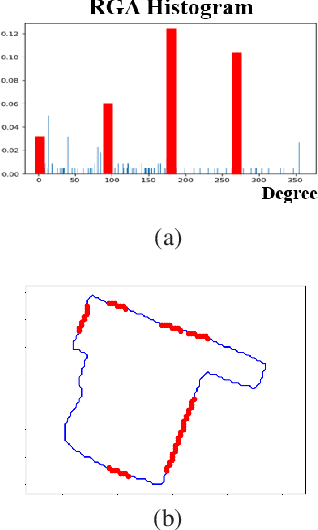
Building footprint extraction in remote sensing data benefits many important applications, such as urban planning and population estimation. Recently, rapid development of Convolutional Neural Networks (CNNs) and open-sourced high resolution satellite building image datasets have pushed the performance boundary further for automated building extractions. However, CNN approaches often generate imprecise building morphologies including noisy edges and round corners. In this paper, we leverage the performance of CNNs, and propose a module that uses prior knowledge of building corners to create angular and concise building polygons from CNN segmentation outputs. We describe a new transform, Relative Gradient Angle Transform (RGA Transform) that converts object contours from time vs. space to time vs. angle. We propose a new shape descriptor, Boundary Orientation Relation Set (BORS), to describe angle relationship between edges in RGA domain, such as orthogonality and parallelism. Finally, we develop an energy minimization framework that makes use of the angle relationship in BORS to straighten edges and reconstruct sharp corners, and the resulting corners create a polygon. Experimental results demonstrate that our method refines CNN output from a rounded approximation to a more clear-cut angular shape of the building footprint.
EmotionNet Nano: An Efficient Deep Convolutional Neural Network Design for Real-time Facial Expression Recognition
Jun 29, 2020
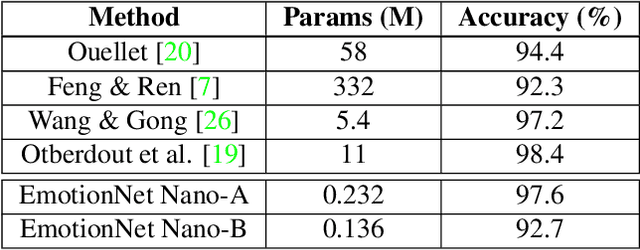
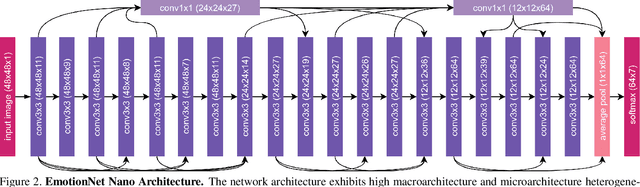
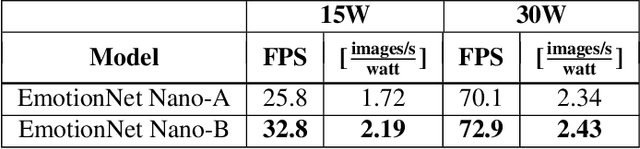
While recent advances in deep learning have led to significant improvements in facial expression classification (FEC), a major challenge that remains a bottleneck for the widespread deployment of such systems is their high architectural and computational complexities. This is especially challenging given the operational requirements of various FEC applications, such as safety, marketing, learning, and assistive living, where real-time requirements on low-cost embedded devices is desired. Motivated by this need for a compact, low latency, yet accurate system capable of performing FEC in real-time on low-cost embedded devices, this study proposes EmotionNet Nano, an efficient deep convolutional neural network created through a human-machine collaborative design strategy, where human experience is combined with machine meticulousness and speed in order to craft a deep neural network design catered towards real-time embedded usage. Two different variants of EmotionNet Nano are presented, each with a different trade-off between architectural and computational complexity and accuracy. Experimental results using the CK+ facial expression benchmark dataset demonstrate that the proposed EmotionNet Nano networks demonstrated accuracies comparable to state-of-the-art in FEC networks, while requiring significantly fewer parameters (e.g., 23$\times$ fewer at a higher accuracy). Furthermore, we demonstrate that the proposed EmotionNet Nano networks achieved real-time inference speeds (e.g. $>25$ FPS and $>70$ FPS at 15W and 30W, respectively) and high energy efficiency (e.g. $>1.7$ images/sec/watt at 15W) on an ARM embedded processor, thus further illustrating the efficacy of EmotionNet Nano for deployment on embedded devices.
Towards computer-aided severity assessment: training and validation of deep neural networks for geographic extent and opacity extent scoring of chest X-rays for SARS-CoV-2 lung disease severity
May 27, 2020
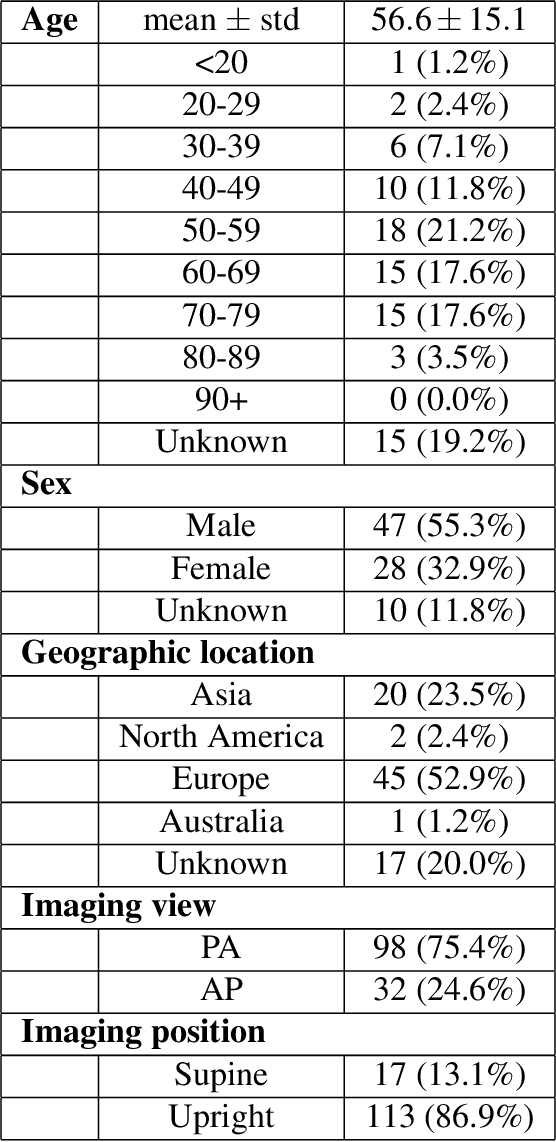
Background: A critical step in effective care and treatment planning for severe acute respiratory syndrome coronavirus 2 (SARS-CoV-2) is the assessment of the severity of disease progression. Chest x-rays (CXRs) are often used to assess SARS-CoV-2 severity, with two important assessment metrics being extent of lung involvement and degree of opacity. In this proof-of-concept study, we assess the feasibility of computer-aided scoring of CXRs of SARS-CoV-2 lung disease severity using a deep learning system. Materials and Methods: Data consisted of 130 CXRs from SARS-CoV-2 positive patient cases from the Cohen study. Geographic extent and opacity extent were scored by two board-certified expert chest radiologists (with 20+ years of experience) and a 2nd-year radiology resident. The deep neural networks used in this study are based on a COVID-Net network architecture. 100 versions of the network were independently learned (50 to perform geographic extent scoring and 50 to perform opacity extent scoring) using random subsets of CXRs from the Cohen study, and evaluated the networks using stratified Monte Carlo cross-validation experiments. Findings: The deep neural networks yielded R$^2$ of 0.673 $\pm$ 0.004 and 0.636 $\pm$ 0.002 between predicted scores and radiologist scores for geographic extent and opacity extent, respectively, in stratified Monte Carlo cross-validation experiments. The best performing networks achieved R$^2$ of 0.865 and 0.746 between predicted scores and radiologist scores for geographic extent and opacity extent, respectively. Interpretation: The results are promising and suggest that the use of deep neural networks on CXRs could be an effective tool for computer-aided assessment of SARS-CoV-2 lung disease severity, although additional studies are needed before adoption for routine clinical use.
DepthNet Nano: A Highly Compact Self-Normalizing Neural Network for Monocular Depth Estimation
Apr 17, 2020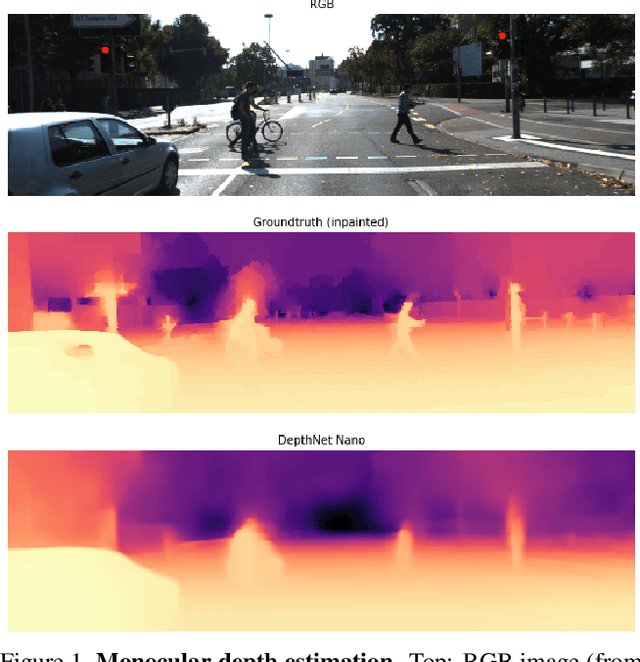
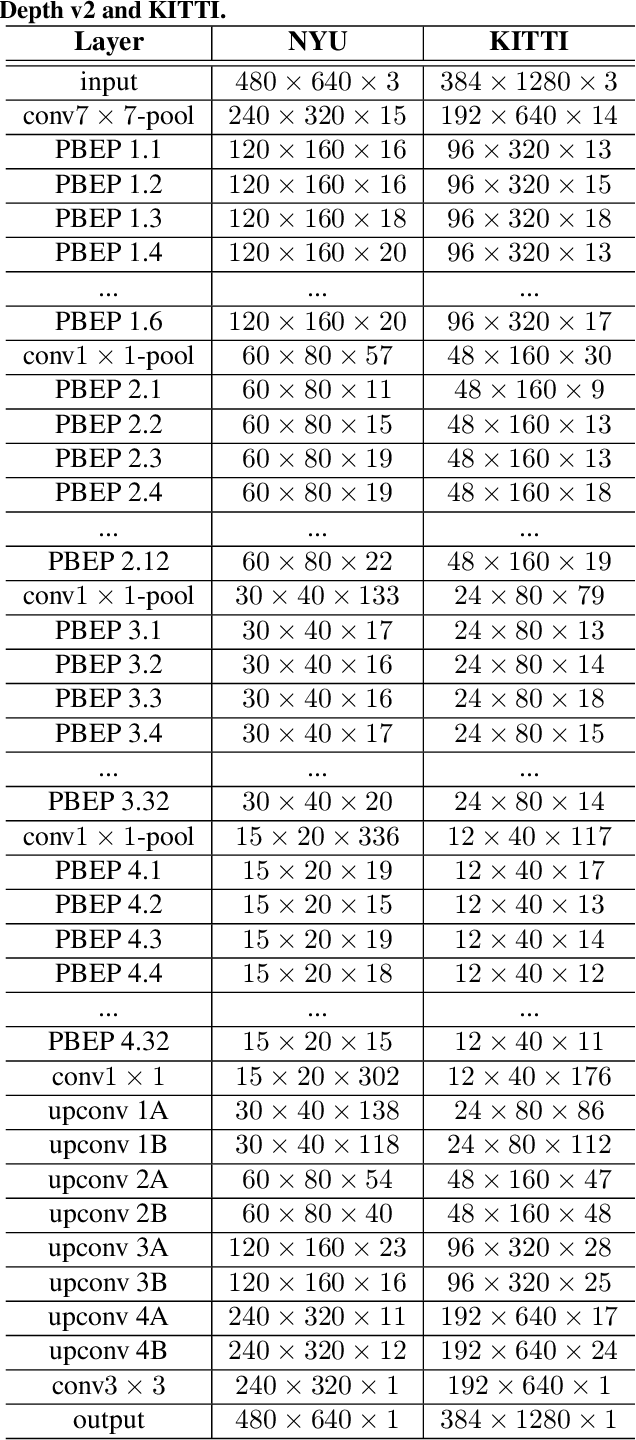
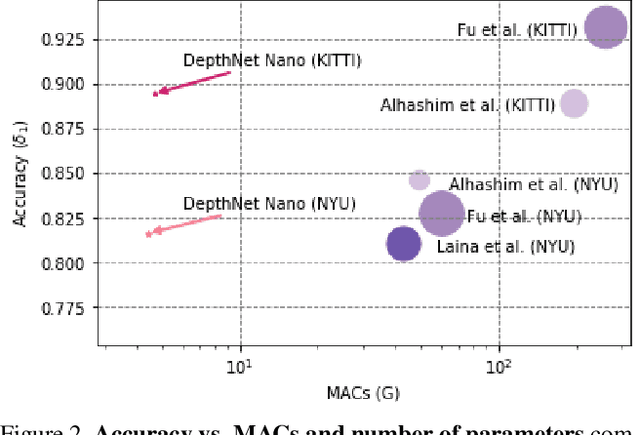

Depth estimation is an active area of research in the field of computer vision, and has garnered significant interest due to its rising demand in a large number of applications ranging from robotics and unmanned aerial vehicles to autonomous vehicles. A particularly challenging problem in this area is monocular depth estimation, where the goal is to infer depth from a single image. An effective strategy that has shown considerable promise in recent years for tackling this problem is the utilization of deep convolutional neural networks. Despite these successes, the memory and computational requirements of such networks have made widespread deployment in embedded scenarios very challenging. In this study, we introduce DepthNet Nano, a highly compact self normalizing network for monocular depth estimation designed using a human machine collaborative design strategy, where principled network design prototyping based on encoder-decoder design principles are coupled with machine-driven design exploration. The result is a compact deep neural network with highly customized macroarchitecture and microarchitecture designs, as well as self-normalizing characteristics, that are highly tailored for the task of embedded depth estimation. The proposed DepthNet Nano possesses a highly efficient network architecture (e.g., 24X smaller and 42X fewer MAC operations than Alhashim et al. on KITTI), while still achieving comparable performance with state-of-the-art networks on the NYU-Depth V2 and KITTI datasets. Furthermore, experiments on inference speed and energy efficiency on a Jetson AGX Xavier embedded module further illustrate the efficacy of DepthNet Nano at different resolutions and power budgets (e.g., ~14 FPS and >0.46 images/sec/watt at 384 X 1280 at a 30W power budget on KITTI).
COVID-Net: A Tailored Deep Convolutional Neural Network Design for Detection of COVID-19 Cases from Chest X-Ray Images
Apr 15, 2020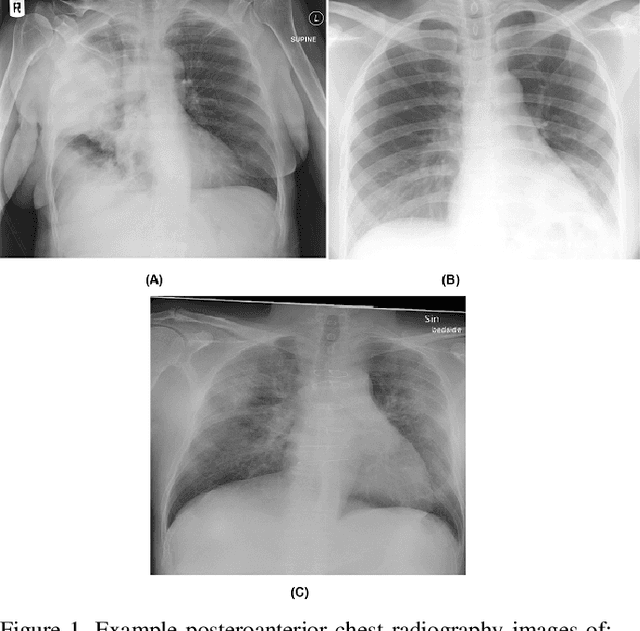
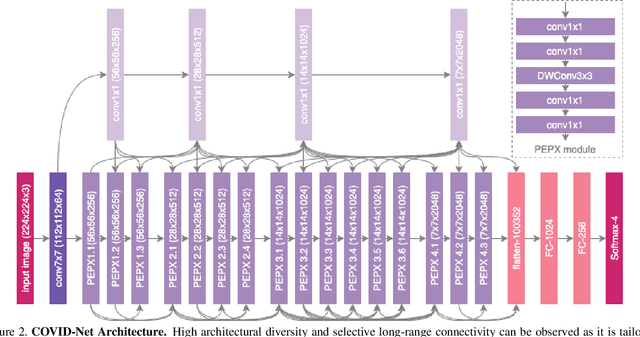
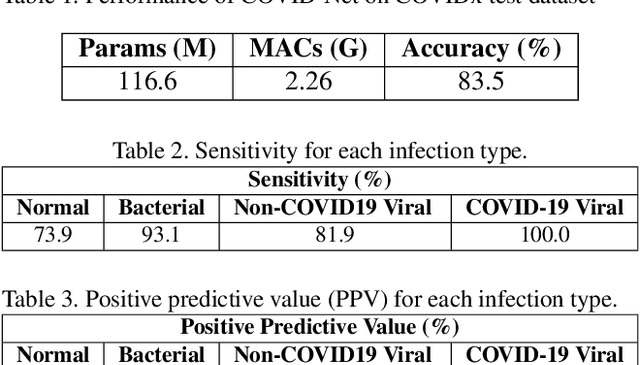
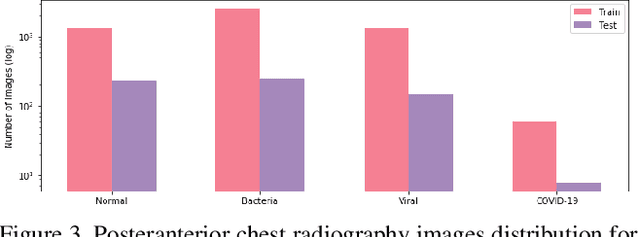
The COVID-19 pandemic continues to have a devastating effect on the health and well-being of the global population. A critical step in the fight against COVID-19 is effective screening of infected patients, with one of the key screening approaches being radiological imaging using chest radiography. Motivated by this, a number of artificial intelligence (AI) systems based on deep learning have been proposed and results have been shown to be quite promising in terms of accuracy in detecting patients infected with COVID-19 using chest radiography images. However, to the best of the authors' knowledge, these developed AI systems have been closed source and unavailable to the research community for deeper understanding and extension, and unavailable for public access and use. Therefore, in this study we introduce COVID-Net, a deep convolutional neural network design tailored for the detection of COVID-19 cases from chest X-ray (CXR) images that is open source and available to the general public. We also describe the CXR dataset leveraged to train COVID-Net, which we will refer to as COVIDx and is comprised of 13,800 chest radiography images across 13,725 patient patient cases from three open access data repositories, one of which we introduced. Furthermore, we investigate how COVID-Net makes predictions using an explainability method in an attempt to gain deeper insights into critical factors associated with COVID cases, which can aid clinicians in improved screening. By no means a production-ready solution, the hope is that the open access COVID-Net, along with the description on constructing the open source COVIDx dataset, will be leveraged and build upon by both researchers and citizen data scientists alike to accelerate the development of highly accurate yet practical deep learning solutions for detecting COVID-19 cases and accelerate treatment of those who need it the most.
Deep Neural Network Perception Models and Robust Autonomous Driving Systems
Mar 04, 2020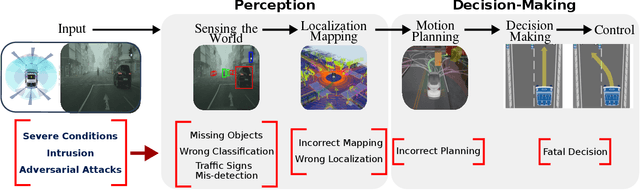


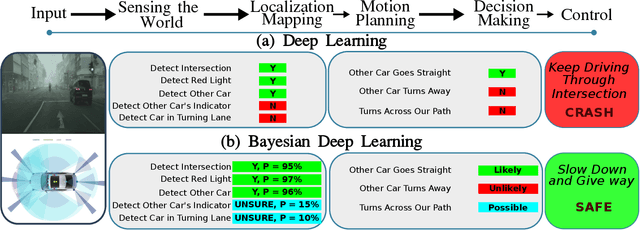
This paper analyzes the robustness of deep learning models in autonomous driving applications and discusses the practical solutions to address that.
TimeConvNets: A Deep Time Windowed Convolution Neural Network Design for Real-time Video Facial Expression Recognition
Mar 03, 2020
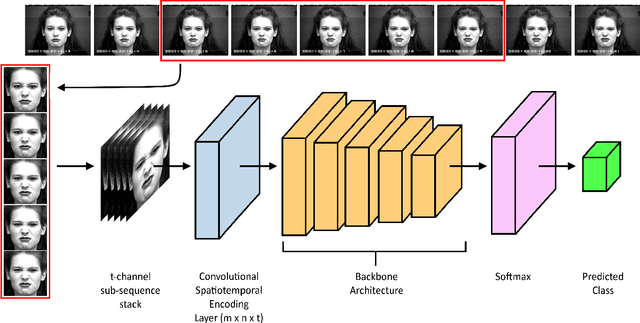
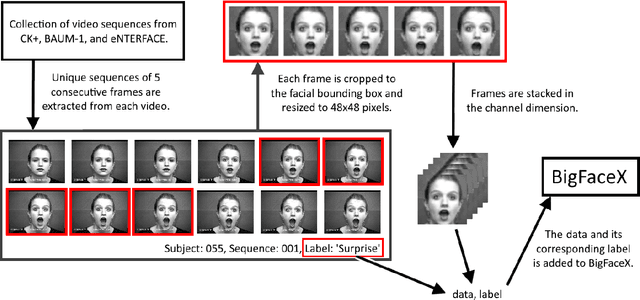
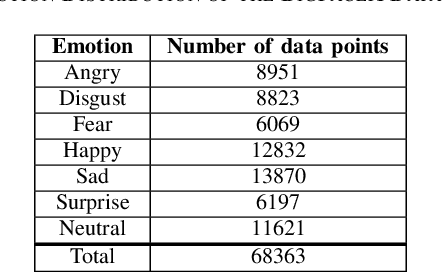
A core challenge faced by the majority of individuals with Autism Spectrum Disorder (ASD) is an impaired ability to infer other people's emotions based on their facial expressions. With significant recent advances in machine learning, one potential approach to leveraging technology to assist such individuals to better recognize facial expressions and reduce the risk of possible loneliness and depression due to social isolation is the design of computer vision-driven facial expression recognition systems. Motivated by this social need as well as the low latency requirement of such systems, this study explores a novel deep time windowed convolutional neural network design (TimeConvNets) for the purpose of real-time video facial expression recognition. More specifically, we explore an efficient convolutional deep neural network design for spatiotemporal encoding of time windowed video frame sub-sequences and study the respective balance between speed and accuracy. Furthermore, to evaluate the proposed TimeConvNet design, we introduce a more difficult dataset called BigFaceX, composed of a modified aggregation of the extended Cohn-Kanade (CK+), BAUM-1, and the eNTERFACE public datasets. Different variants of the proposed TimeConvNet design with different backbone network architectures were evaluated using BigFaceX alongside other network designs for capturing spatiotemporal information, and experimental results demonstrate that TimeConvNets can better capture the transient nuances of facial expressions and boost classification accuracy while maintaining a low inference time.
Learn2Perturb: an End-to-end Feature Perturbation Learning to Improve Adversarial Robustness
Mar 03, 2020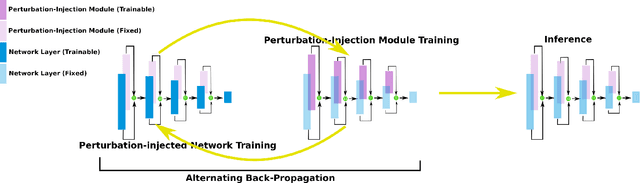

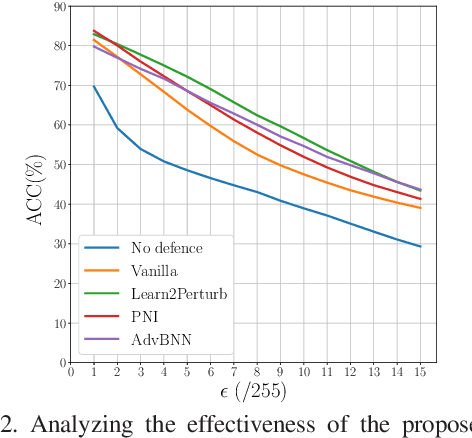
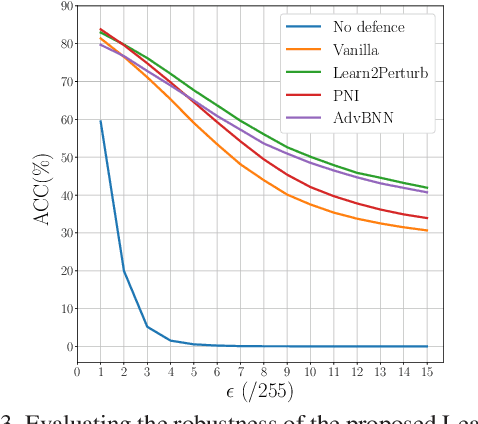
While deep neural networks have been achieving state-of-the-art performance across a wide variety of applications, their vulnerability to adversarial attacks limits their widespread deployment for safety-critical applications. Alongside other adversarial defense approaches being investigated, there has been a very recent interest in improving adversarial robustness in deep neural networks through the introduction of perturbations during the training process. However, such methods leverage fixed, pre-defined perturbations and require significant hyper-parameter tuning that makes them very difficult to leverage in a general fashion. In this study, we introduce Learn2Perturb, an end-to-end feature perturbation learning approach for improving the adversarial robustness of deep neural networks. More specifically, we introduce novel perturbation-injection modules that are incorporated at each layer to perturb the feature space and increase uncertainty in the network. This feature perturbation is performed at both the training and the inference stages. Furthermore, inspired by the Expectation-Maximization, an alternating back-propagation training algorithm is introduced to train the network and noise parameters consecutively. Experimental results on CIFAR-10 and CIFAR-100 datasets show that the proposed Learn2Perturb method can result in deep neural networks which are $4-7\%$ more robust on $l_{\infty}$ FGSM and PDG adversarial attacks and significantly outperforms the state-of-the-art against $l_2$ $C\&W$ attack and a wide range of well-known black-box attacks.