 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Explicit Object-Centric Representations with Vision Transformers
Oct 25, 2022



With the recent successful adaptation of transformers to the vision domain, particularly when trained in a self-supervised fashion, it has been shown that vision transformers can learn impressive object-reasoning-like behaviour and features expressive for the task of object segmentation in images. In this paper, we build on the self-supervision task of masked autoencoding and explore its effectiveness for explicitly learning object-centric representations with transformers. To this end, we design an object-centric autoencoder using transformers only and train it end-to-end to reconstruct full images from unmasked patches. We show that the model efficiently learns to decompose simple scenes as measured by segmentation metrics on several multi-object benchmarks.
Continuous Monte Carlo Graph Search
Oct 04, 2022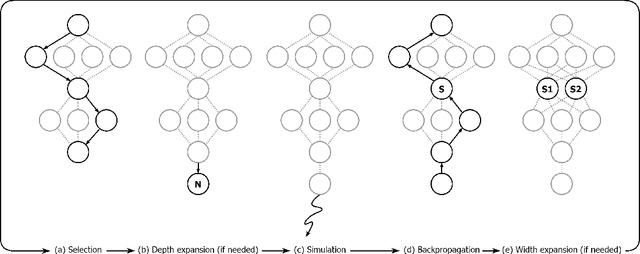

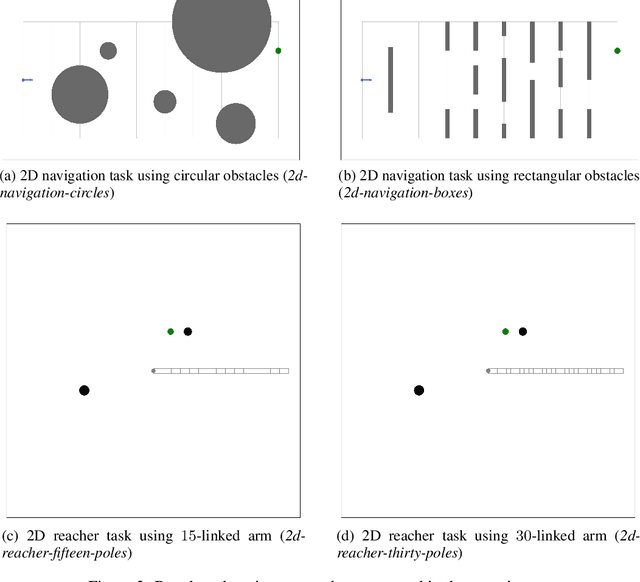

In many complex sequential decision making tasks, online planning is crucial for high-performance. For efficient online planning, Monte Carlo Tree Search (MCTS) employs a principled mechanism for trading off between exploration and exploitation. MCTS outperforms comparison methods in various discrete decision making domains such as Go, Chess, and Shogi. Following, extensions of MCTS to continuous domains have been proposed. However, the inherent high branching factor and the resulting explosion of search tree size is limiting existing methods. To solve this problem, this paper proposes Continuous Monte Carlo Graph Search (CMCGS), a novel extension of MCTS to online planning in environments with continuous state and action spaces. CMCGS takes advantage of the insight that, during planning, sharing the same action policy between several states can yield high performance. To implement this idea, at each time step CMCGS clusters similar states into a limited number of stochastic action bandit nodes, which produce a layered graph instead of an MCTS search tree. Experimental evaluation with limited sample budgets shows that CMCGS outperforms comparison methods in several complex continuous DeepMind Control Suite benchmarks and a 2D navigation task.
Compositional Generalization in Grounded Language Learning via Induced Model Sparsity
Jul 06, 2022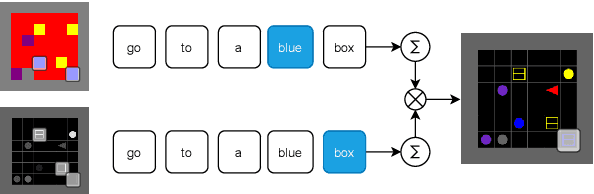
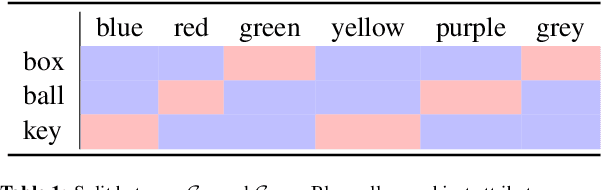
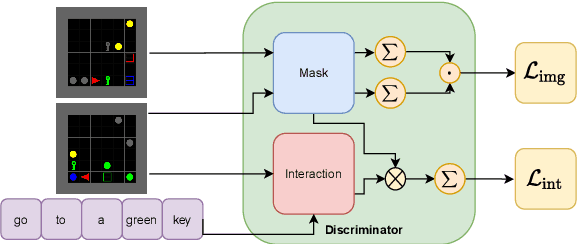
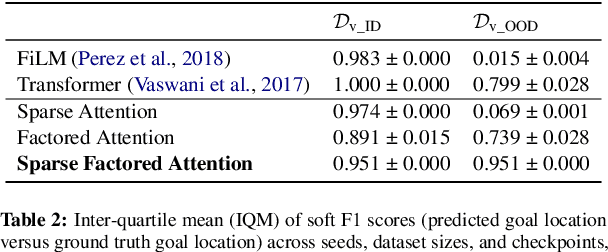
We provide a study of how induced model sparsity can help achieve compositional generalization and better sample efficiency in grounded language learning problems. We consider simple language-conditioned navigation problems in a grid world environment with disentangled observations. We show that standard neural architectures do not always yield compositional generalization. To address this, we design an agent that contains a goal identification module that encourages sparse correlations between words in the instruction and attributes of objects, composing them together to find the goal. The output of the goal identification module is the input to a value iteration network planner. Our agent maintains a high level of performance on goals containing novel combinations of properties even when learning from a handful of demonstrations. We examine the internal representations of our agent and find the correct correspondences between words in its dictionary and attributes in the environment.
Improved Training of Physics-Informed Neural Networks with Model Ensembles
Apr 11, 2022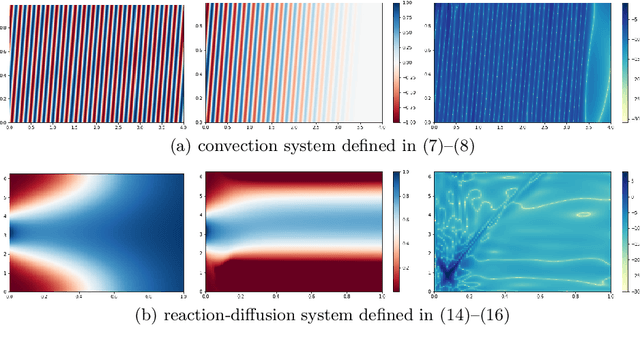

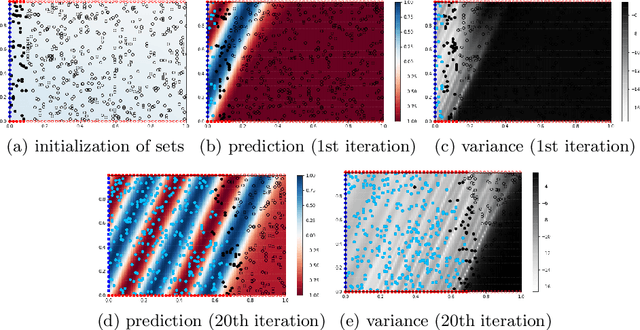
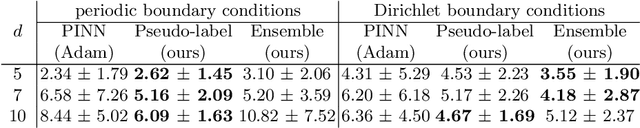
Learning the solution of partial differential equations (PDEs) with a neural network (known in the literature as a physics-informed neural network, PINN) is an attractive alternative to traditional solvers due to its elegancy, greater flexibility and the ease of incorporating observed data. However, training PINNs is notoriously difficult in practice. One problem is the existence of multiple simple (but wrong) solutions which are attractive for PINNs when the solution interval is too large. In this paper, we propose to expand the solution interval gradually to make the PINN converge to the correct solution. To find a good schedule for the solution interval expansion, we train an ensemble of PINNs. The idea is that all ensemble members converge to the same solution in the vicinity of observed data (e.g., initial conditions) while they may be pulled towards different wrong solutions farther away from the observations. Therefore, we use the ensemble agreement as the criterion for including new points for computing the loss derived from PDEs. We show experimentally that the proposed method can improve the accuracy of the found solution.
Learning Trajectories of Hamiltonian Systems with Neural Networks
Apr 11, 2022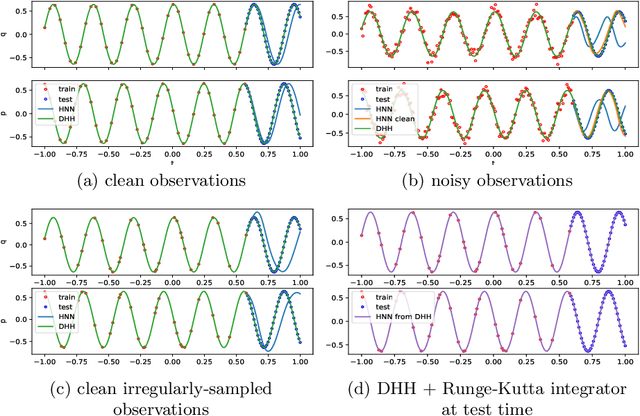
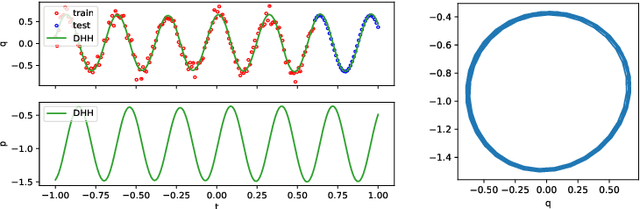
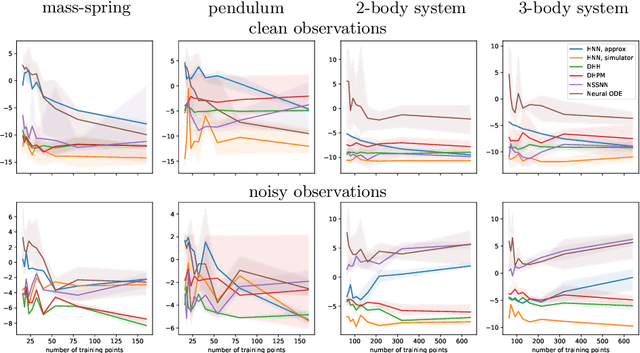
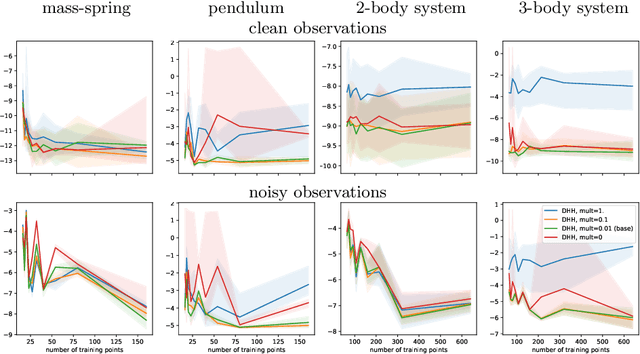
Modeling of conservative systems with neural networks is an area of active research. A popular approach is to use Hamiltonian neural networks (HNNs) which rely on the assumptions that a conservative system is described with Hamilton's equations of motion. Many recent works focus on improving the integration schemes used when training HNNs. In this work, we propose to enhance HNNs with an estimation of a continuous-time trajectory of the modeled system using an additional neural network, called a deep hidden physics model in the literature. We demonstrate that the proposed integration scheme works well for HNNs, especially with low sampling rates, noisy and irregular observations.
A Grid-Structured Model of Tubular Reactors
Dec 13, 2021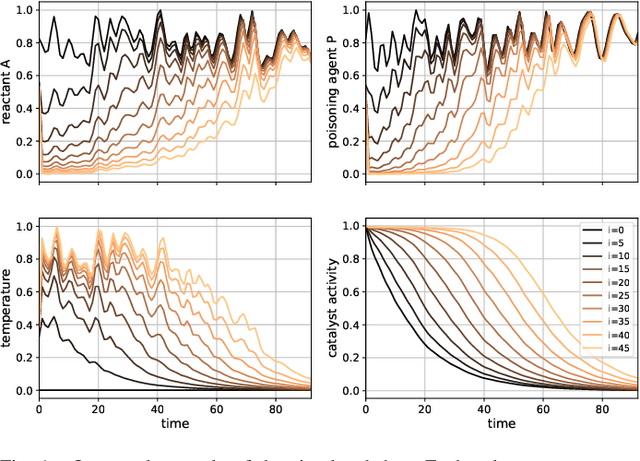
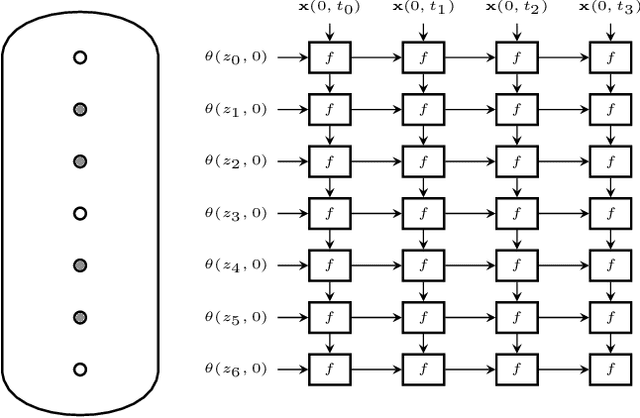
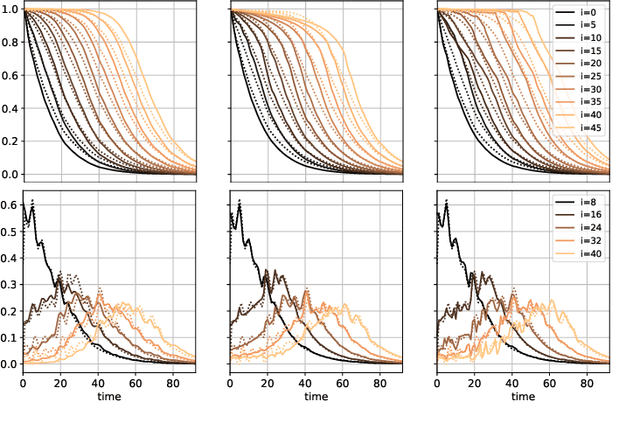
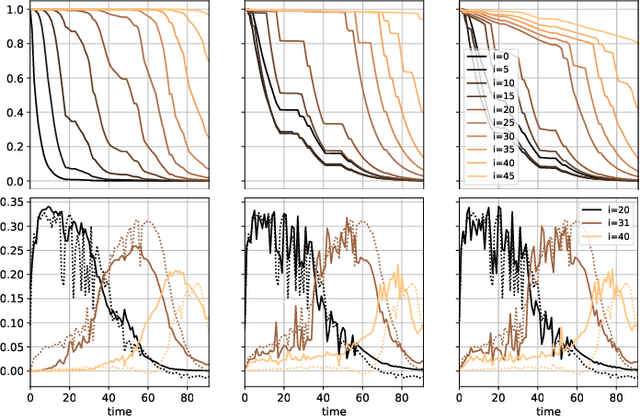
We propose a grid-like computational model of tubular reactors. The architecture is inspired by the computations performed by solvers of partial differential equations which describe the dynamics of the chemical process inside a tubular reactor. The proposed model may be entirely based on the known form of the partial differential equations or it may contain generic machine learning components such as multi-layer perceptrons. We show that the proposed model can be trained using limited amounts of data to describe the state of a fixed-bed catalytic reactor. The trained model can reconstruct unmeasured states such as the catalyst activity using the measurements of inlet concentrations and temperatures along the reactor.
A Relational Model for One-Shot Classification
Nov 08, 2021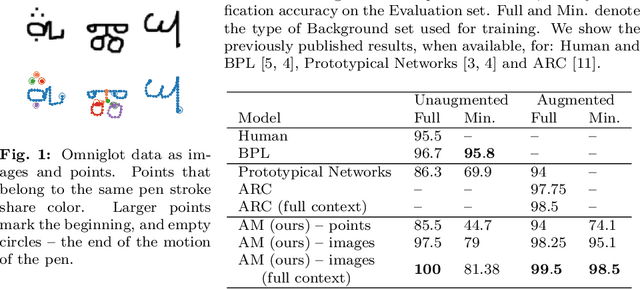
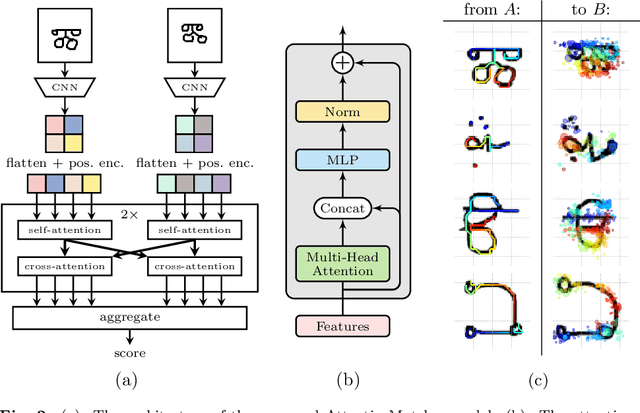
We show that a deep learning model with built-in relational inductive bias can bring benefits to sample-efficient learning, without relying on extensive data augmentation. The proposed one-shot classification model performs relational matching of a pair of inputs in the form of local and pairwise attention. Our approach solves perfectly the one-shot image classification Omniglot challenge. Our model exceeds human level accuracy, as well as the previous state of the art, with no data augmentation.
Automating Privilege Escalation with Deep Reinforcement Learning
Oct 04, 2021
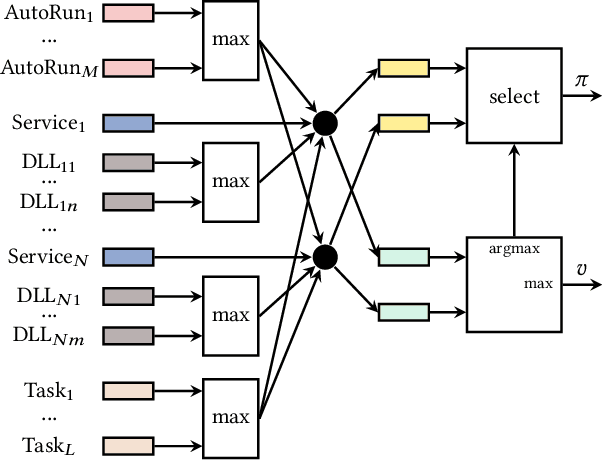
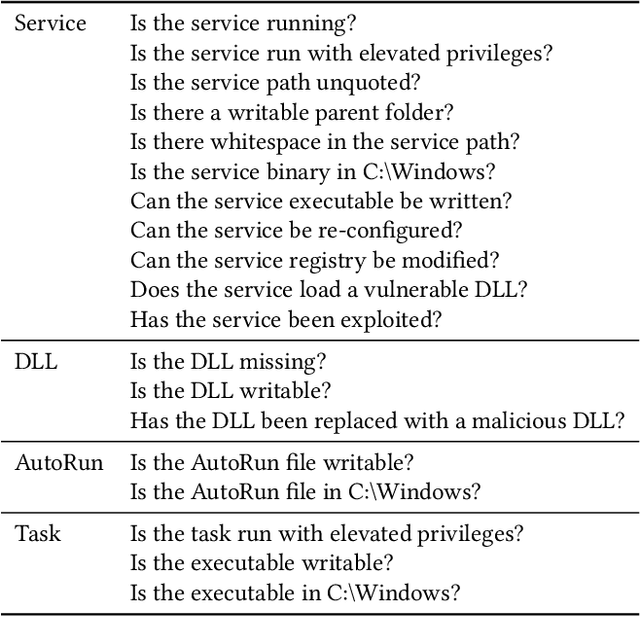
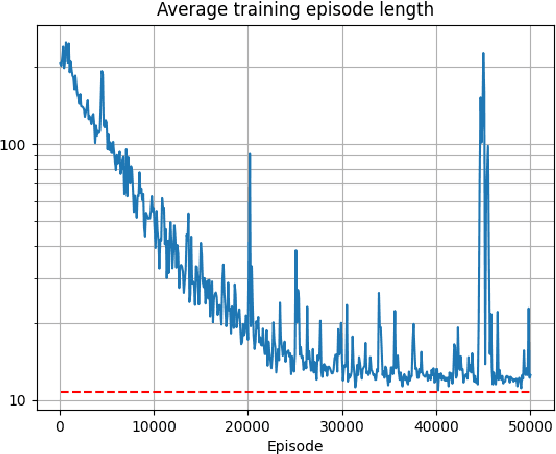
AI-based defensive solutions are necessary to defend networks and information assets against intelligent automated attacks. Gathering enough realistic data for training machine learning-based defenses is a significant practical challenge. An intelligent red teaming agent capable of performing realistic attacks can alleviate this problem. However, there is little scientific evidence demonstrating the feasibility of fully automated attacks using machine learning. In this work, we exemplify the potential threat of malicious actors using deep reinforcement learning to train automated agents. We present an agent that uses a state-of-the-art reinforcement learning algorithm to perform local privilege escalation. Our results show that the autonomous agent can escalate privileges in a Windows 7 environment using a wide variety of different techniques depending on the environment configuration it encounters. Hence, our agent is usable for generating realistic attack sensor data for training and evaluating intrusion detection systems.
Learning to Assist Agents by Observing Them
Oct 04, 2021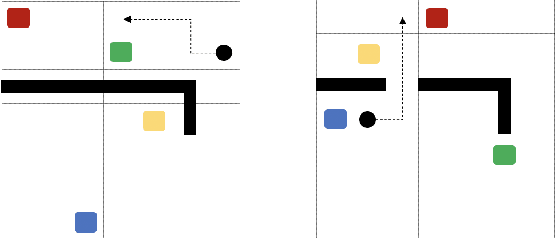

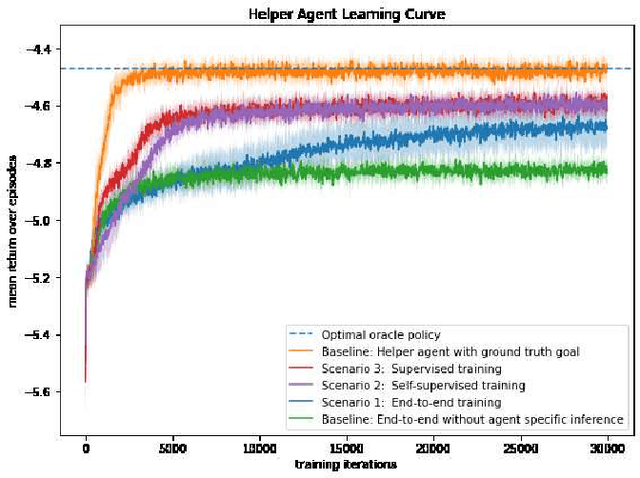
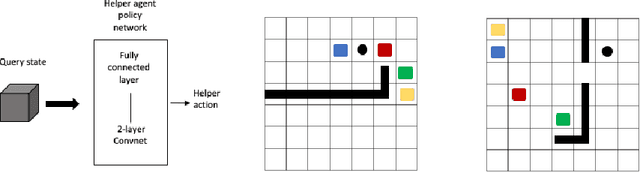
The ability of an AI agent to assist other agents, such as humans, is an important and challenging goal, which requires the assisting agent to reason about the behavior and infer the goals of the assisted agent. Training such an ability by using reinforcement learning usually requires large amounts of online training, which is difficult and costly. On the other hand, offline data about the behavior of the assisted agent might be available, but is non-trivial to take advantage of by methods such as offline reinforcement learning. We introduce methods where the capability to create a representation of the behavior is first pre-trained with offline data, after which only a small amount of interaction data is needed to learn an assisting policy. We test the setting in a gridworld where the helper agent has the capability to manipulate the environment of the assisted artificial agents, and introduce three different scenarios where the assistance considerably improves the performance of the assisted agents.
Behaviour-conditioned policies for cooperative reinforcement learning tasks
Oct 04, 2021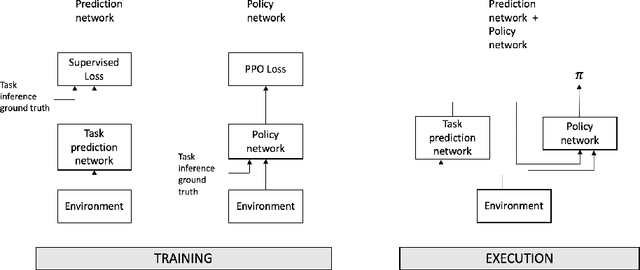

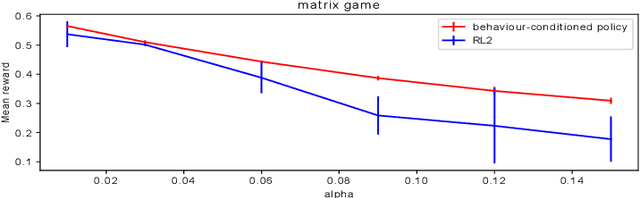
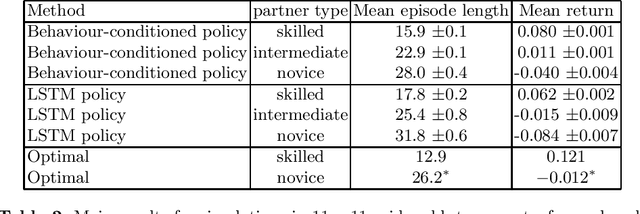
The cooperation among AI systems, and between AI systems and humans is becoming increasingly important. In various real-world tasks, an agent needs to cooperate with unknown partner agent types. This requires the agent to assess the behaviour of the partner agent during a cooperative task and to adjust its own policy to support the cooperation. Deep reinforcement learning models can be trained to deliver the required functionality but are known to suffer from sample inefficiency and slow learning. However, adapting to a partner agent behaviour during the ongoing task requires ability to assess the partner agent type quickly. We suggest a method, where we synthetically produce populations of agents with different behavioural patterns together with ground truth data of their behaviour, and use this data for training a meta-learner. We additionally suggest an agent architecture, which can efficiently use the generated data and gain the meta-learning capability. When an agent is equipped with such a meta-learner, it is capable of quickly adapting to cooperation with unknown partner agent types in new situations. This method can be used to automatically form a task distribution for meta-training from emerging behaviours that arise, for example, through self-play.