 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Reasoning Bottleneck in Graph-RAG: Structured Prompting and Context Compression for Multi-Hop QA
Mar 14, 2026Graph-RAG systems achieve strong multi-hop question answering by indexing documents into knowledge graphs, but strong retrieval does not guarantee strong answers. Evaluating KET-RAG, a leading Graph-RAG system, on three multi-hop QA benchmarks (HotpotQA, MuSiQue, 2WikiMultiHopQA), we find that 77% to 91% of questions have the gold answer in the retrieved context, yet accuracy is only 35% to 78%, and 73% to 84% of errors are reasoning failures. We propose two augmentations: (i) SPARQL chain-of-thought prompting, which decomposes questions into triple-pattern queries aligned with the entity-relationship context, and (ii) graph-walk compression, which compresses the context by ~60% via knowledge-graph traversal with no LLM calls. SPARQL CoT improves accuracy by +2 to +14 pp; graph-walk compression adds +6 pp on average when paired with structured prompting on smaller models. Surprisingly, we show that, with question-type routing, a fully augmented budget open-weight Llama-8B model matches or exceeds the unaugmented Llama-70B baseline on all three benchmarks at ~12x lower cost. A replication on LightRAG confirms that our augmentations transfer across Graph-RAG systems.
Gender and Race Bias in Consumer Product Recommendations by Large Language Models
Feb 08, 2026Large Language Models are increasingly employed in generating consumer product recommendations, yet their potential for embedding and amplifying gender and race biases remains underexplored. This paper serves as one of the first attempts to examine these biases within LLM-generated recommendations. We leverage prompt engineering to elicit product suggestions from LLMs for various race and gender groups and employ three analytical methods-Marked Words, Support Vector Machines, and Jensen-Shannon Divergence-to identify and quantify biases. Our findings reveal significant disparities in the recommendations for demographic groups, underscoring the need for more equitable LLM recommendation systems.
* Accepted at the 39th International Conference on Advanced Information Networking and Applications (AINA 2025)
Multi-Stage Graph Peeling Algorithm for Probabilistic Core Decomposition
Aug 13, 2021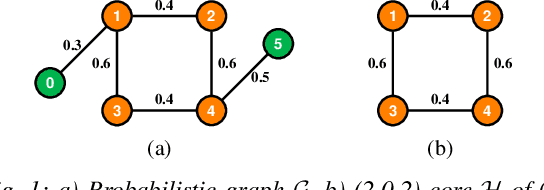
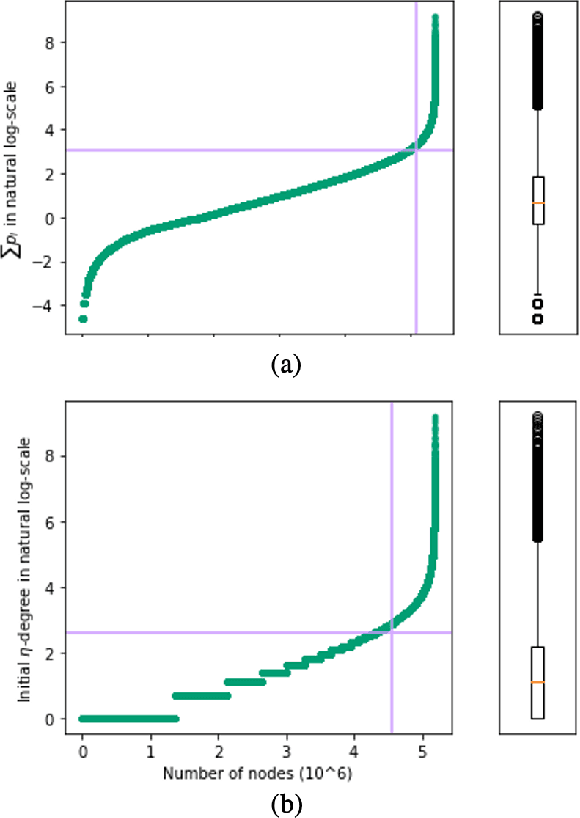
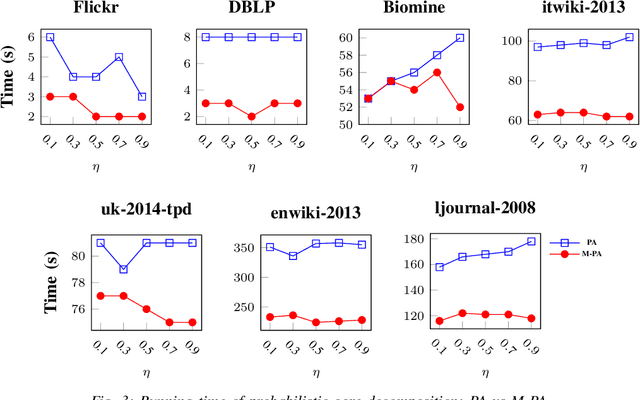
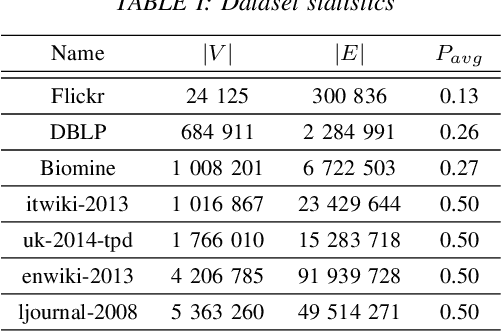
Mining dense subgraphs where vertices connect closely with each other is a common task when analyzing graphs. A very popular notion in subgraph analysis is core decomposition. Recently, Esfahani et al. presented a probabilistic core decomposition algorithm based on graph peeling and Central Limit Theorem (CLT) that is capable of handling very large graphs. Their proposed peeling algorithm (PA) starts from the lowest degree vertices and recursively deletes these vertices, assigning core numbers, and updating the degree of neighbour vertices until it reached the maximum core. However, in many applications, particularly in biology, more valuable information can be obtained from dense sub-communities and we are not interested in small cores where vertices do not interact much with others. To make the previous PA focus more on dense subgraphs, we propose a multi-stage graph peeling algorithm (M-PA) that has a two-stage data screening procedure added before the previous PA. After removing vertices from the graph based on the user-defined thresholds, we can reduce the graph complexity largely and without affecting the vertices in subgraphs that we are interested in. We show that M-PA is more efficient than the previous PA and with the properly set filtering threshold, can produce very similar if not identical dense subgraphs to the previous PA (in terms of graph density and clustering coefficient).