 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Reasoning Bottleneck in Graph-RAG: Structured Prompting and Context Compression for Multi-Hop QA
Mar 14, 2026Graph-RAG systems achieve strong multi-hop question answering by indexing documents into knowledge graphs, but strong retrieval does not guarantee strong answers. Evaluating KET-RAG, a leading Graph-RAG system, on three multi-hop QA benchmarks (HotpotQA, MuSiQue, 2WikiMultiHopQA), we find that 77% to 91% of questions have the gold answer in the retrieved context, yet accuracy is only 35% to 78%, and 73% to 84% of errors are reasoning failures. We propose two augmentations: (i) SPARQL chain-of-thought prompting, which decomposes questions into triple-pattern queries aligned with the entity-relationship context, and (ii) graph-walk compression, which compresses the context by ~60% via knowledge-graph traversal with no LLM calls. SPARQL CoT improves accuracy by +2 to +14 pp; graph-walk compression adds +6 pp on average when paired with structured prompting on smaller models. Surprisingly, we show that, with question-type routing, a fully augmented budget open-weight Llama-8B model matches or exceeds the unaugmented Llama-70B baseline on all three benchmarks at ~12x lower cost. A replication on LightRAG confirms that our augmentations transfer across Graph-RAG systems.
Multi-Stage Graph Peeling Algorithm for Probabilistic Core Decomposition
Aug 13, 2021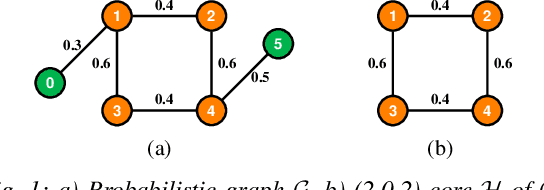
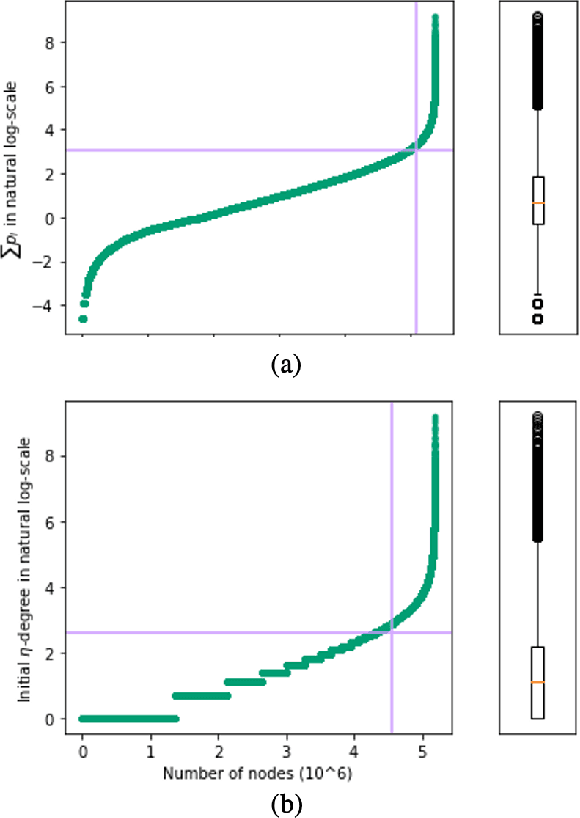
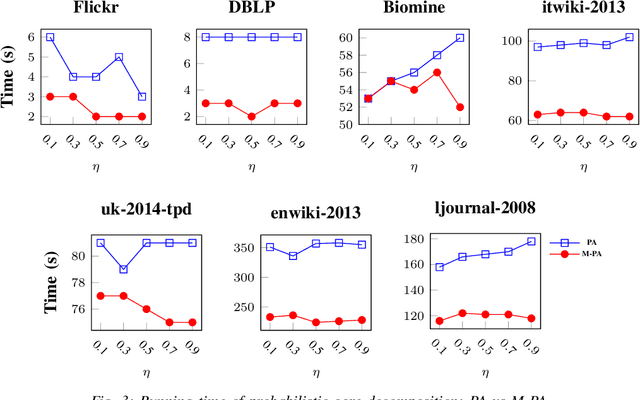
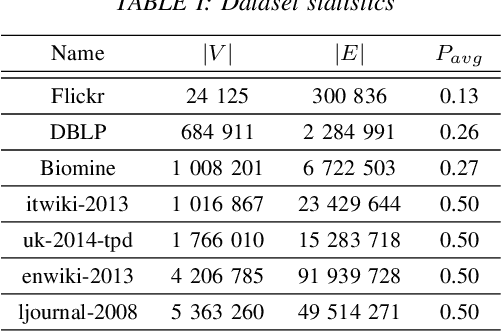
Mining dense subgraphs where vertices connect closely with each other is a common task when analyzing graphs. A very popular notion in subgraph analysis is core decomposition. Recently, Esfahani et al. presented a probabilistic core decomposition algorithm based on graph peeling and Central Limit Theorem (CLT) that is capable of handling very large graphs. Their proposed peeling algorithm (PA) starts from the lowest degree vertices and recursively deletes these vertices, assigning core numbers, and updating the degree of neighbour vertices until it reached the maximum core. However, in many applications, particularly in biology, more valuable information can be obtained from dense sub-communities and we are not interested in small cores where vertices do not interact much with others. To make the previous PA focus more on dense subgraphs, we propose a multi-stage graph peeling algorithm (M-PA) that has a two-stage data screening procedure added before the previous PA. After removing vertices from the graph based on the user-defined thresholds, we can reduce the graph complexity largely and without affecting the vertices in subgraphs that we are interested in. We show that M-PA is more efficient than the previous PA and with the properly set filtering threshold, can produce very similar if not identical dense subgraphs to the previous PA (in terms of graph density and clustering coefficient).
Predicting the Programming Language of Questions and Snippets of StackOverflow Using Natural Language Processing
Sep 21, 2018


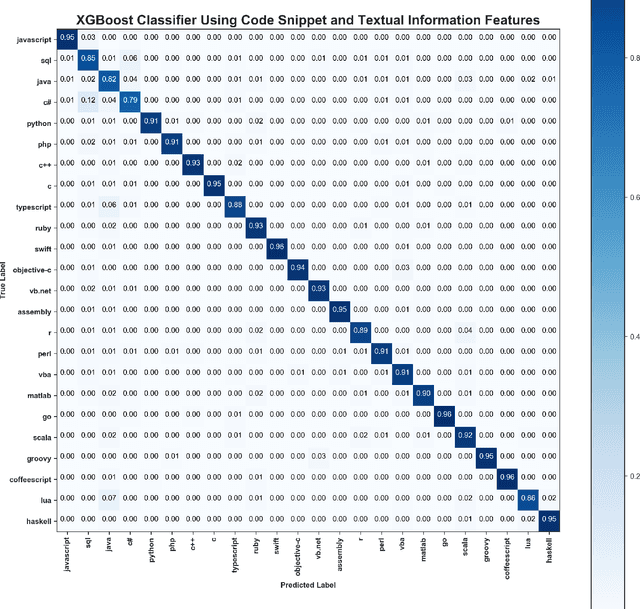
Stack Overflow is the most popular Q&A website among software developers. As a platform for knowledge sharing and acquisition, the questions posted in Stack Overflow usually contain a code snippet. Stack Overflow relies on users to properly tag the programming language of a question and it simply assumes that the programming language of the snippets inside a question is the same as the tag of the question itself. In this paper, we propose a classifier to predict the programming language of questions posted in Stack Overflow using Natural Language Processing (NLP) and Machine Learning (ML). The classifier achieves an accuracy of 91.1% in predicting the 24 most popular programming languages by combining features from the title, body and the code snippets of the question. We also propose a classifier that only uses the title and body of the question and has an accuracy of 81.1%. Finally, we propose a classifier of code snippets only that achieves an accuracy of 77.7%. These results show that deploying Machine Learning techniques on the combination of text and the code snippets of a question provides the best performance. These results demonstrate also that it is possible to identify the programming language of a snippet of few lines of source code. We visualize the feature space of two programming languages Java and SQL in order to identify some special properties of information inside the questions in Stack Overflow corresponding to these languages.
SCC: Automatic Classification of Code Snippets
Sep 21, 2018



Determining the programming language of a source code file has been considered in the research community; it has been shown that Machine Learning (ML) and Natural Language Processing (NLP) algorithms can be effective in identifying the programming language of source code files. However, determining the programming language of a code snippet or a few lines of source code is still a challenging task. Online forums such as Stack Overflow and code repositories such as GitHub contain a large number of code snippets. In this paper, we describe Source Code Classification (SCC), a classifier that can identify the programming language of code snippets written in 21 different programming languages. A Multinomial Naive Bayes (MNB) classifier is employed which is trained using Stack Overflow posts. It is shown to achieve an accuracy of 75% which is higher than that with Programming Languages Identification (PLI a proprietary online classifier of snippets) whose accuracy is only 55.5%. The average score for precision, recall and the F1 score with the proposed tool are 0.76, 0.75 and 0.75, respectively. In addition, it can distinguish between code snippets from a family of programming languages such as C, C++ and C#, and can also identify the programming language version such as C# 3.0, C# 4.0 and C# 5.0.