 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGoogle's Neural Machine Translation System: Bridging the Gap between Human and Machine Translation
Oct 08, 2016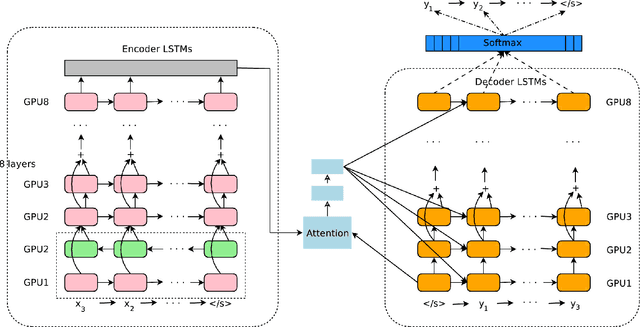

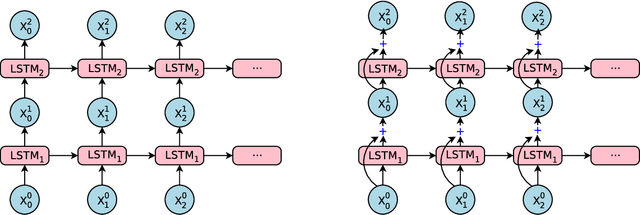
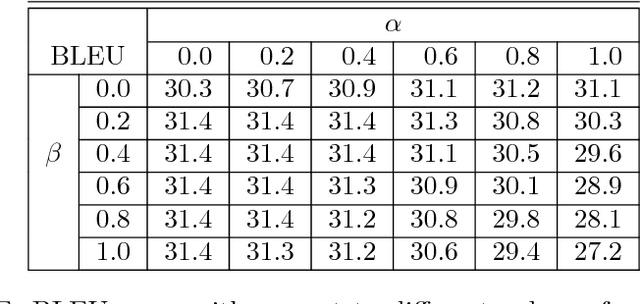
Neural Machine Translation (NMT) is an end-to-end learning approach for automated translation, with the potential to overcome many of the weaknesses of conventional phrase-based translation systems. Unfortunately, NMT systems are known to be computationally expensive both in training and in translation inference. Also, most NMT systems have difficulty with rare words. These issues have hindered NMT's use in practical deployments and services, where both accuracy and speed are essential. In this work, we present GNMT, Google's Neural Machine Translation system, which attempts to address many of these issues. Our model consists of a deep LSTM network with 8 encoder and 8 decoder layers using attention and residual connections. To improve parallelism and therefore decrease training time, our attention mechanism connects the bottom layer of the decoder to the top layer of the encoder. To accelerate the final translation speed, we employ low-precision arithmetic during inference computations. To improve handling of rare words, we divide words into a limited set of common sub-word units ("wordpieces") for both input and output. This method provides a good balance between the flexibility of "character"-delimited models and the efficiency of "word"-delimited models, naturally handles translation of rare words, and ultimately improves the overall accuracy of the system. Our beam search technique employs a length-normalization procedure and uses a coverage penalty, which encourages generation of an output sentence that is most likely to cover all the words in the source sentence. On the WMT'14 English-to-French and English-to-German benchmarks, GNMT achieves competitive results to state-of-the-art. Using a human side-by-side evaluation on a set of isolated simple sentences, it reduces translation errors by an average of 60% compared to Google's phrase-based production system.
Transition-Based Dependency Parsing With Pluggable Classifiers
Nov 01, 2012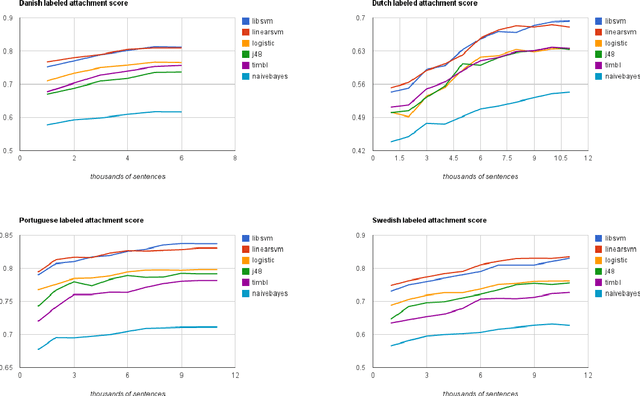
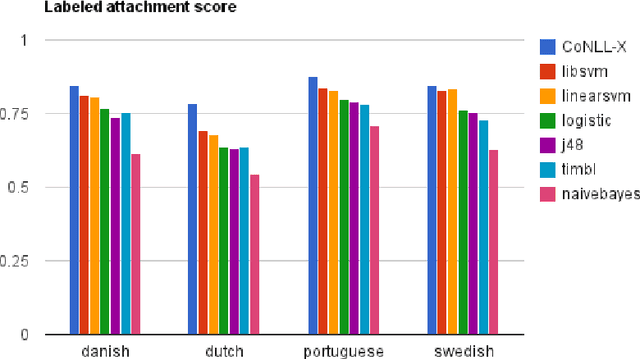

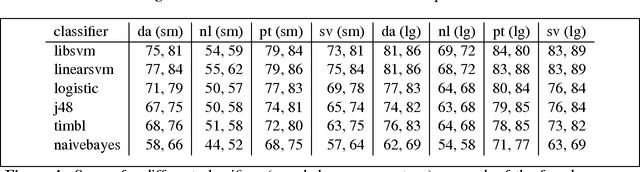
In principle, the design of transition-based dependency parsers makes it possible to experiment with any general-purpose classifier without other changes to the parsing algorithm. In practice, however, it often takes substantial software engineering to bridge between the different representations used by two software packages. Here we present extensions to MaltParser that allow the drop-in use of any classifier conforming to the interface of the Weka machine learning package, a wrapper for the TiMBL memory-based learner to this interface, and experiments on multilingual dependency parsing with a variety of classifiers. While earlier work had suggested that memory-based learners might be a good choice for low-resource parsing scenarios, we cannot support that hypothesis in this work. We observed that support-vector machines give better parsing performance than the memory-based learner, regardless of the size of the training set.
Tree Transducers, Machine Translation, and Cross-Language Divergences
Mar 28, 2012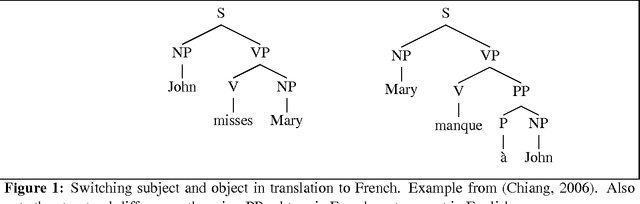
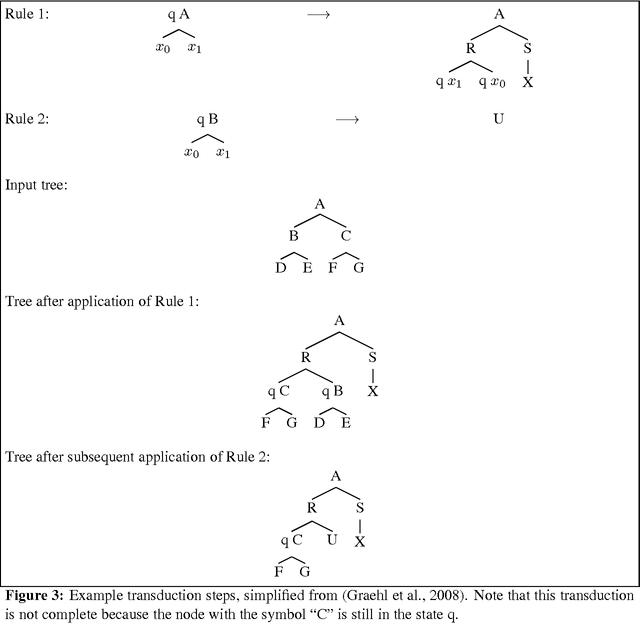
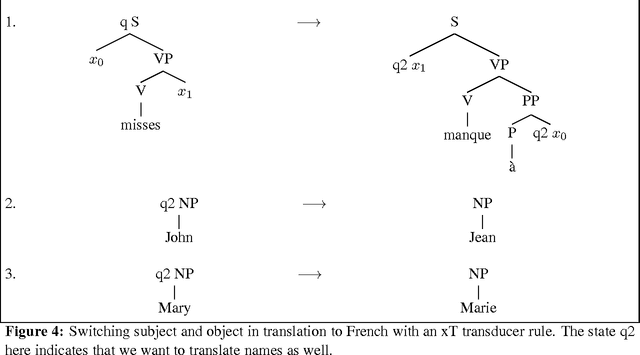

Tree transducers are formal automata that transform trees into other trees. Many varieties of tree transducers have been explored in the automata theory literature, and more recently, in the machine translation literature. In this paper I review T and xT transducers, situate them among related formalisms, and show how they can be used to implement rules for machine translation systems that cover all of the cross-language structural divergences described in Bonnie Dorr's influential article on the topic. I also present an implementation of xT transduction, suitable and convenient for experimenting with translation rules.
Considering a resource-light approach to learning verb valencies
Feb 06, 2012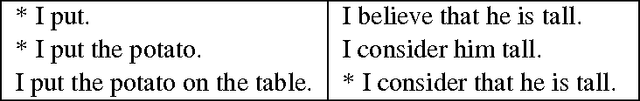

Here we describe work on learning the subcategories of verbs in a morphologically rich language using only minimal linguistic resources. Our goal is to learn verb subcategorizations for Quechua, an under-resourced morphologically rich language, from an unannotated corpus. We compare results from applying this approach to an unannotated Arabic corpus with those achieved by processing the same text in treebank form. The original plan was to use only a morphological analyzer and an unannotated corpus, but experiments suggest that this approach by itself will not be effective for learning the combinatorial potential of Arabic verbs in general. The lower bound on resources for acquiring this information is somewhat higher, apparently requiring a a part-of-speech tagger and chunker for most languages, and a morphological disambiguater for Arabic.