 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInterpretable Stochastic Block Influence Model: measuring social influence among homophilous communities
Jun 01, 2020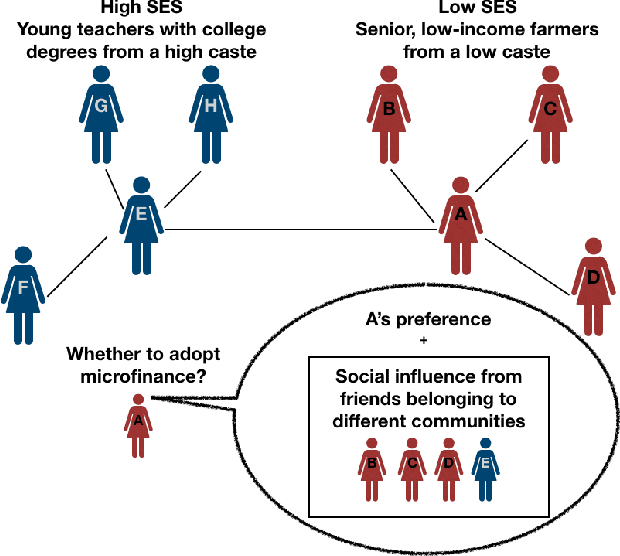
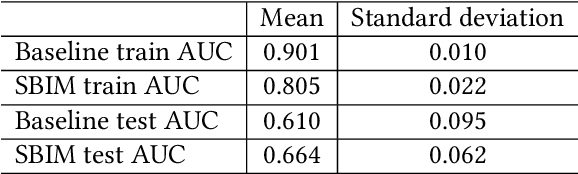
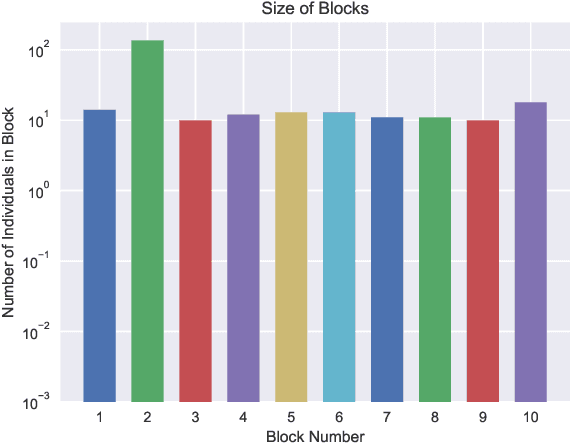
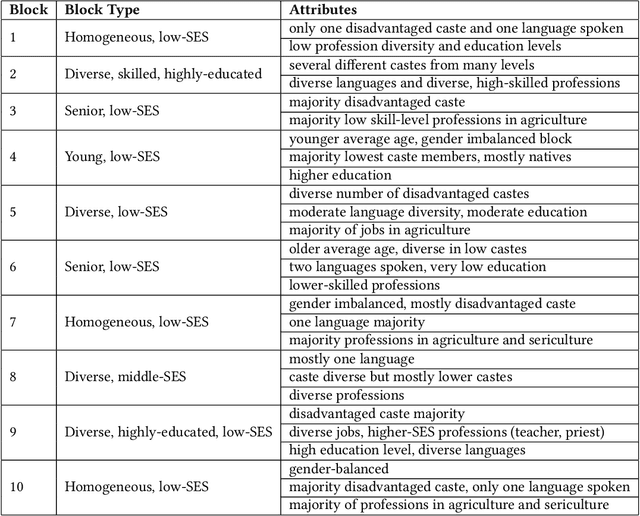
Decision-making on networks can be explained by both homophily and social influence. While homophily drives the formation of communities with similar characteristics, social influence occurs both within and between communities. Social influence can be reasoned through role theory, which indicates that the influences among individuals depend on their roles and the behavior of interest. To operationalize these social science theories, we empirically identify the homophilous communities and use the community structures to capture the "roles", which affect the particular decision-making processes. We propose a generative model named Stochastic Block Influence Model and jointly analyze both the network formation and the behavioral influence within and between different empirically-identified communities. To evaluate the performance and demonstrate the interpretability of our method, we study the adoption decisions of microfinance in an Indian village. We show that although individuals tend to form links within communities, there are strong positive and negative social influences between communities, supporting the weak tie theory. Moreover, we find that communities with shared characteristics are associated with positive influence. In contrast, the communities with a lack of overlap are associated with negative influence. Our framework facilitates the quantification of the influences underlying decision communities and is thus a useful tool for driving information diffusion, viral marketing, and technology adoptions.
DADI: Dynamic Discovery of Fair Information with Adversarial Reinforcement Learning
Oct 30, 2019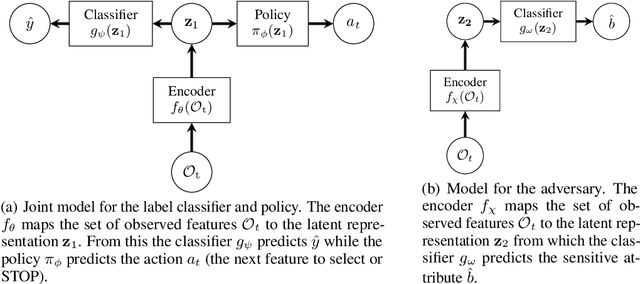
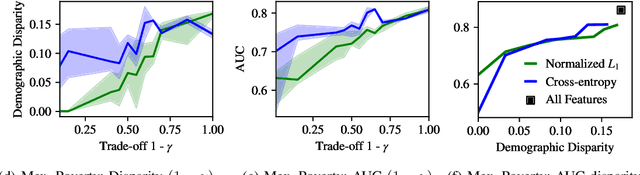
We introduce a framework for dynamic adversarial discovery of information (DADI), motivated by a scenario where information (a feature set) is used by third parties with unknown objectives. We train a reinforcement learning agent to sequentially acquire a subset of the information while balancing accuracy and fairness of predictors downstream. Based on the set of already acquired features, the agent decides dynamically to either collect more information from the set of available features or to stop and predict using the information that is currently available. Building on previous work exploring adversarial representation learning, we attain group fairness (demographic parity) by rewarding the agent with the adversary's loss, computed over the final feature set. Importantly, however, the framework provides a more general starting point for fair or private dynamic information discovery. Finally, we demonstrate empirically, using two real-world datasets, that we can trade-off fairness and predictive performance
Thompson Sampling on Symmetric $α$-Stable Bandits
Jul 08, 2019
Thompson Sampling provides an efficient technique to introduce prior knowledge in the multi-armed bandit problem, along with providing remarkable empirical performance. In this paper, we revisit the Thompson Sampling algorithm under rewards drawn from symmetric $\alpha$-stable distributions, which are a class of heavy-tailed probability distributions utilized in finance and economics, in problems such as modeling stock prices and human behavior. We present an efficient framework for posterior inference, which leads to two algorithms for Thompson Sampling in this setting. We prove finite-time regret bounds for both algorithms, and demonstrate through a series of experiments the stronger performance of Thompson Sampling in this setting. With our results, we provide an exposition of symmetric $\alpha$-stable distributions in sequential decision-making, and enable sequential Bayesian inference in applications from diverse fields in finance and complex systems that operate on heavy-tailed features.
Communication Topologies Between Learning Agents in Deep Reinforcement Learning
Feb 16, 2019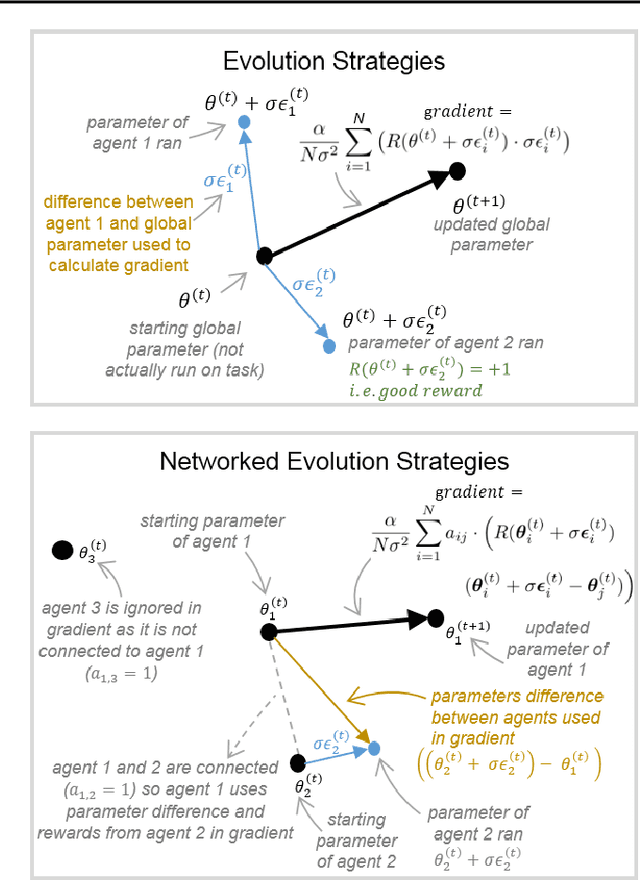

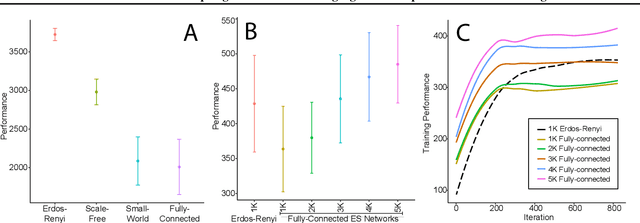
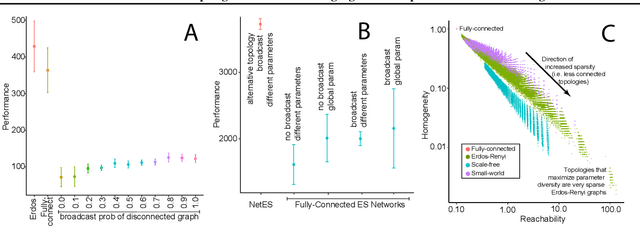
A common technique to improve speed and robustness of learning in deep reinforcement learning (DRL) and many other machine learning algorithms is to run multiple learning agents in parallel. A neglected component in the development of these algorithms has been how best to arrange the learning agents involved to better facilitate distributed search. Here we draw upon results from the networked optimization and collective intelligence literatures suggesting that arranging learning agents in less than fully connected topologies (the implicit way agents are commonly arranged in) can improve learning. We explore the relative performance of four popular families of graphs and observe that one such family (Erdos-Renyi random graphs) empirically outperforms the standard fully-connected communication topology across several DRL benchmark tasks. We observe that 1000 learning agents arranged in an Erdos-Renyi graph can perform as well as 3000 agents arranged in the standard fully-connected topology, showing the large learning improvement possible when carefully designing the topology over which agents communicate. We complement these empirical results with a preliminary theoretical investigation of why less than fully connected topologies can perform better. Overall, our work suggests that distributed machine learning algorithms could be made more efficient if the communication topology between learning agents was optimized.
Learning Quadratic Games on Networks
Nov 21, 2018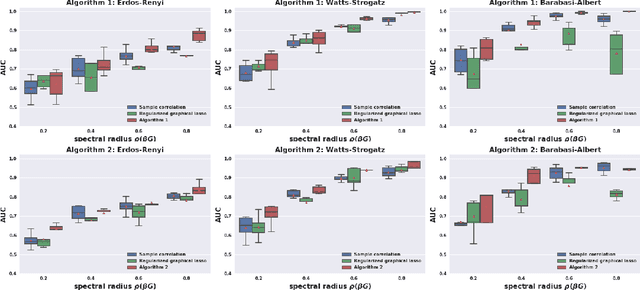
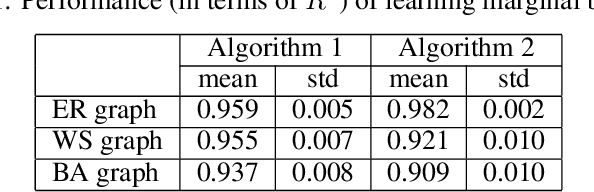
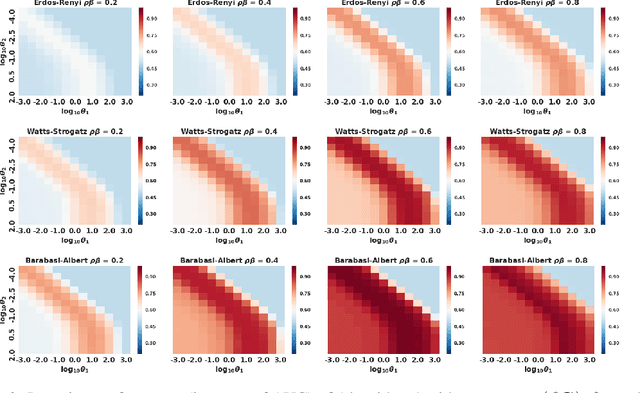
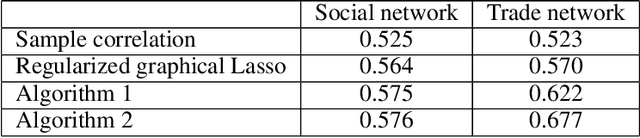
Individuals, or organizations, cooperate with or compete against one another in a wide range of practical situations. Such strategic interactions may be modeled as games played on networks, where an individual's payoff depends not only on her action but also that of her neighbors. The current literature has predominantly focused on analyzing the characteristics of network games in the scenario where the structure of the network, which is represented by a graph, is known beforehand. It is often the case, however, that the actions of the players are readily observable while the underlying interaction network remains hidden. In this paper, we propose two novel frameworks for learning, from the observations on individual actions, network games with linear-quadratic payoffs, and in particular the structure of the interaction network. Our frameworks are based on the Nash equilibrium of such games and involve solving a joint optimization problem for the graph structure and the individual marginal benefits. We test the proposed frameworks in synthetic settings and further study several factors that affect their learning performance. Moreover, with experiments on three real-world examples, we show that our methods can effectively and more accurately learn the games than the baselines. The proposed approach is among the first of its kind for learning quadratic games, and have both theoretical and practical implications for understanding strategic interactions in a network environment.
Active Fairness in Algorithmic Decision Making
Sep 28, 2018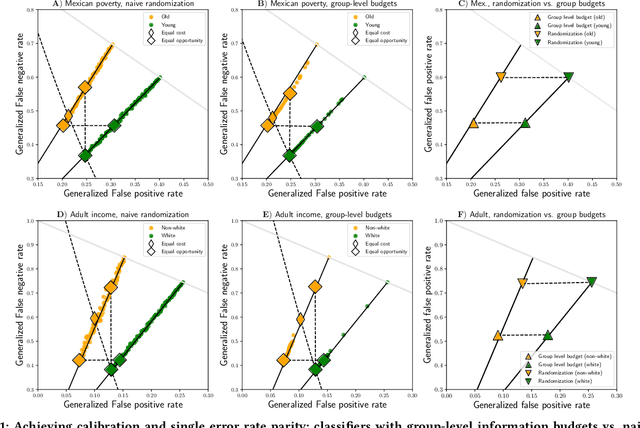
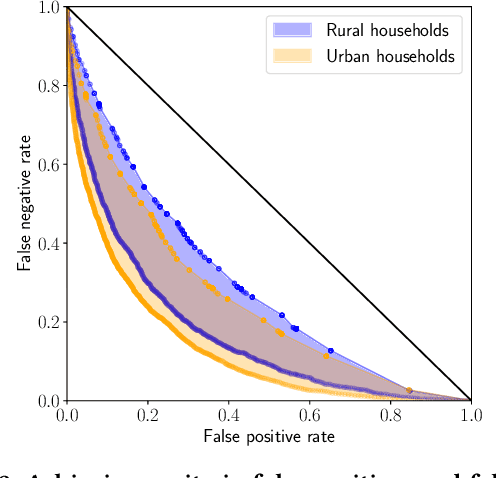
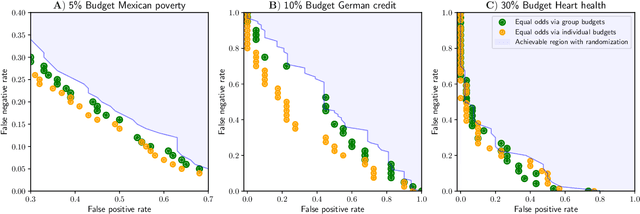
Society increasingly relies on machine learning models for automated decision making. Yet, efficiency gains from automation have come paired with concern for algorithmic discrimination that can systematize inequality. Substantial work in algorithmic fairness has surged, focusing on either post-processing trained models, constraining learning processes, or pre-processing training data. Recent work has proposed optimal post-processing methods that randomize classification decisions on a fraction of individuals in order to achieve fairness measures related to parity in errors and calibration. These methods, however, have raised concern due to the information inefficiency, intra-group unfairness, and Pareto sub-optimality they entail. The present work proposes an alternative active framework for fair classification, where, in deployment, a decision-maker adaptively acquires information according to the needs of different groups or individuals, towards balancing disparities in classification performance. We propose two such methods, where information collection is adapted to group- and individual-level needs respectively. We show on real-world datasets that these can achieve: 1) calibration and single error parity (e.g., equal opportunity); and 2) parity in both false positive and false negative rates (i.e., equal odds). Moreover, we show that, by leveraging their additional degree of freedom, active approaches can outperform randomization-based classifiers previously considered optimal, while also avoiding limitations such as intra-group unfairness.
RoboChain: A Secure Data-Sharing Framework for Human-Robot Interaction
Mar 26, 2018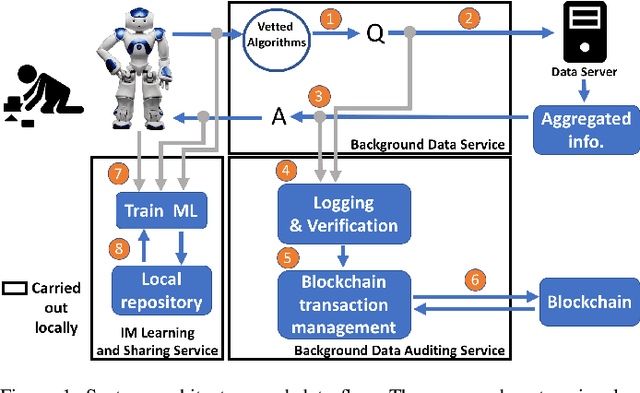
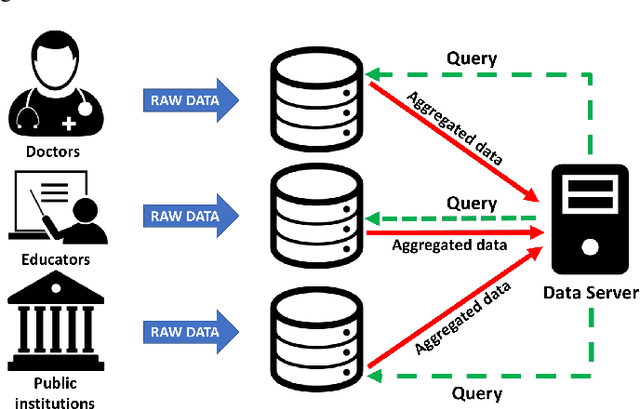
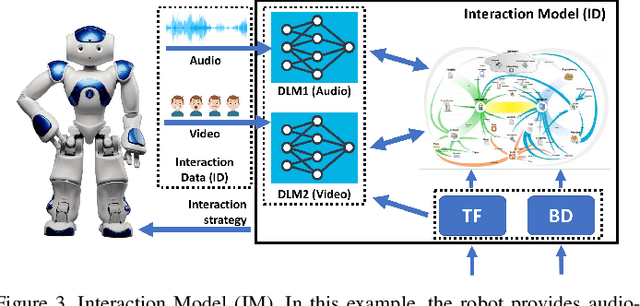
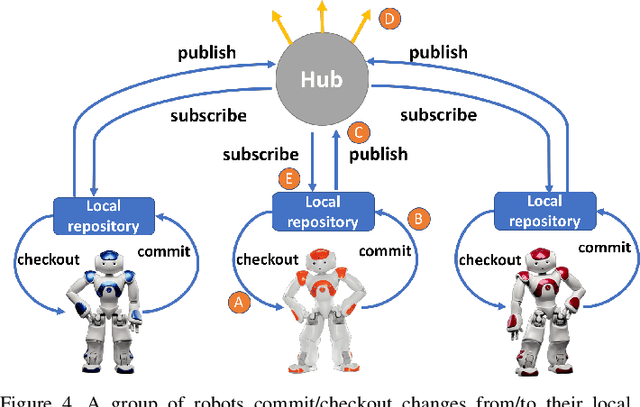
Robots have potential to revolutionize the way we interact with the world around us. One of their largest potentials is in the domain of mobile health where they can be used to facilitate clinical interventions. However, to accomplish this, robots need to have access to our private data in order to learn from these data and improve their interaction capabilities. Furthermore, to enhance this learning process, the knowledge sharing among multiple robot units is the natural step forward. However, to date, there is no well-established framework which allows for such data sharing while preserving the privacy of the users (e.g., the hospital patients). To this end, we introduce RoboChain - the first learning framework for secure, decentralized and computationally efficient data and model sharing among multiple robot units installed at multiple sites (e.g., hospitals). RoboChain builds upon and combines the latest advances in open data access and blockchain technologies, as well as machine learning. We illustrate this framework using the example of a clinical intervention conducted in a private network of hospitals. Specifically, we lay down the system architecture that allows multiple robot units, conducting the interventions at different hospitals, to perform efficient learning without compromising the data privacy.
Improved Learning in Evolution Strategies via Sparser Inter-Agent Network Topologies
Nov 30, 2017

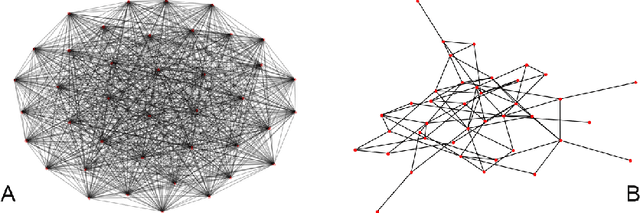
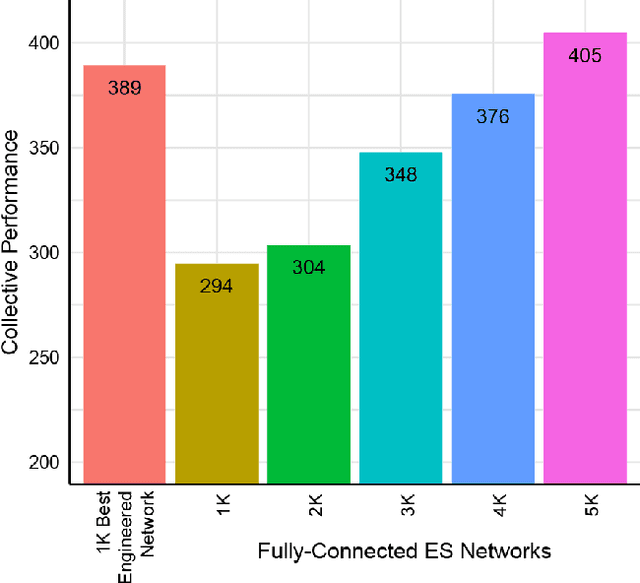
We draw upon a previously largely untapped literature on human collective intelligence as a source of inspiration for improving deep learning. Implicit in many algorithms that attempt to solve Deep Reinforcement Learning (DRL) tasks is the network of processors along which parameter values are shared. So far, existing approaches have implicitly utilized fully-connected networks, in which all processors are connected. However, the scientific literature on human collective intelligence suggests that complete networks may not always be the most effective information network structures for distributed search through complex spaces. Here we show that alternative topologies can improve deep neural network training: we find that sparser networks learn higher rewards faster, leading to learning improvements at lower communication costs.
Stigmergy-based modeling to discover urban activity patterns from positioning data
Apr 12, 2017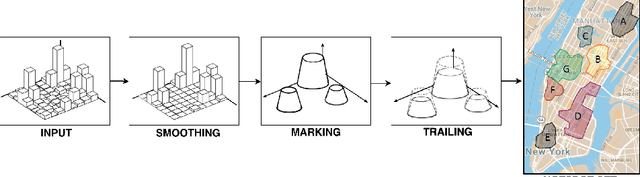

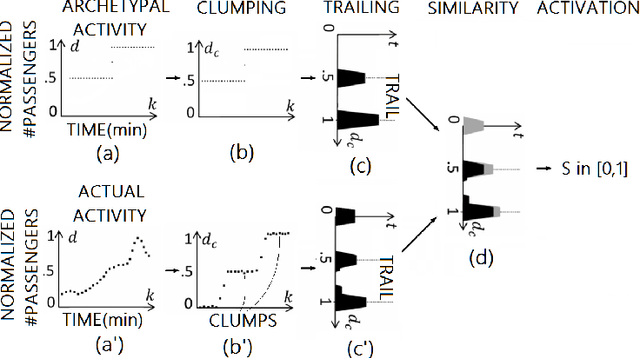
Positioning data offer a remarkable source of information to analyze crowds urban dynamics. However, discovering urban activity patterns from the emergent behavior of crowds involves complex system modeling. An alternative approach is to adopt computational techniques belonging to the emergent paradigm, which enables self-organization of data and allows adaptive analysis. Specifically, our approach is based on stigmergy. By using stigmergy each sample position is associated with a digital pheromone deposit, which progressively evaporates and aggregates with other deposits according to their spatiotemporal proximity. Based on this principle, we exploit positioning data to identify high density areas (hotspots) and characterize their activity over time. This characterization allows the comparison of dynamics occurring in different days, providing a similarity measure exploitable by clustering techniques. Thus, we cluster days according to their activity behavior, discovering unexpected urban activity patterns. As a case study, we analyze taxi traces in New York City during 2015.
Optimal Dynamic Coverage Infrastructure for Large-Scale Fleets of Reconnaissance UAVs
Nov 17, 2016

Current state of the art in the field of UAV activation relies solely on human operators for the design and adaptation of the drones' flying routes. Furthermore, this is being done today on an individual level (one vehicle per operators), with some exceptions of a handful of new systems, that are comprised of a small number of self-organizing swarms, manually guided by a human operator. Drones-based monitoring is of great importance in variety of civilian domains, such as road safety, homeland security, and even environmental control. In its military aspect, efficiently detecting evading targets by a fleet of unmanned drones has an ever increasing impact on the ability of modern armies to engage in warfare. The latter is true both traditional symmetric conflicts among armies as well as asymmetric ones. Be it a speeding driver, a polluting trailer or a covert convoy, the basic challenge remains the same -- how can its detection probability be maximized using as little number of drones as possible. In this work we propose a novel approach for the optimization of large scale swarms of reconnaissance drones -- capable of producing on-demand optimal coverage strategies for any given search scenario. Given an estimation cost of the threat's potential damages, as well as types of monitoring drones available and their comparative performance, our proposed method generates an analytically provable strategy, stating the optimal number and types of drones to be deployed, in order to cost-efficiently monitor a pre-defined region for targets maneuvering using a given roads networks. We demonstrate our model using a unique dataset of the Israeli transportation network, on which different deployment schemes for drones deployment are evaluated.