 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnabling Self-Improving Agents to Learn at Test Time With Human-In-The-Loop Guidance
Jul 23, 2025Large language model (LLM) agents often struggle in environments where rules and required domain knowledge frequently change, such as regulatory compliance and user risk screening. Current approaches, like offline fine-tuning and standard prompting, are insufficient because they cannot effectively adapt to new knowledge during actual operation. To address this limitation, we propose the Adaptive Reflective Interactive Agent (ARIA), an LLM agent framework designed specifically to continuously learn updated domain knowledge at test time. ARIA assesses its own uncertainty through structured self-dialogue, proactively identifying knowledge gaps and requesting targeted explanations or corrections from human experts. It then systematically updates an internal, timestamped knowledge repository with provided human guidance, detecting and resolving conflicting or outdated knowledge through comparisons and clarification queries. We evaluate ARIA on the realistic customer due diligence name screening task on TikTok Pay, alongside publicly available dynamic knowledge tasks. Results demonstrate significant improvements in adaptability and accuracy compared to baselines using standard offline fine-tuning and existing self-improving agents. ARIA is deployed within TikTok Pay serving over 150 million monthly active users, confirming its practicality and effectiveness for operational use in rapidly evolving environments.
DMind Benchmark: The First Comprehensive Benchmark for LLM Evaluation in the Web3 Domain
Apr 18, 2025
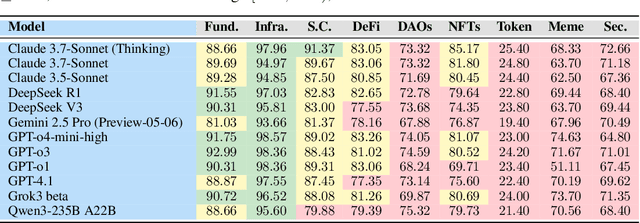
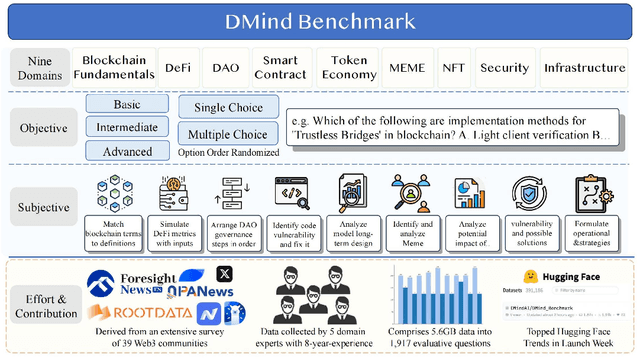
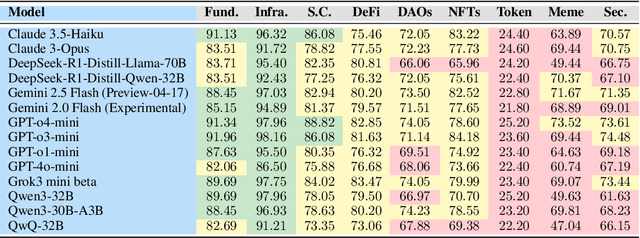
Recent advances in Large Language Models (LLMs) have led to significant progress on a wide range of natural language processing tasks. However, their effectiveness in specialized and rapidly evolving domains such as Web3 remains underexplored. In this paper, we introduce DMind Benchmark, a novel framework that systematically tests LLMs across nine key categories encompassing blockchain fundamentals, infrastructure, smart contract analysis, decentralized finance (DeFi), decentralized autonomous organizations (DAOs), non-fungible tokens (NFTs), token economics, meme concepts, and security vulnerabilities. DMind Benchmark goes beyond conventional multiple-choice questions by incorporating domain-specific subjective tasks (e.g., smart contract code auditing and repair, numeric reasoning on on-chain data, and fill-in assessments), thereby capturing real-world complexities and stress-testing model adaptability. We evaluate fifteen popular LLMs (from ChatGPT, DeepSeek, Claude, and Gemini series) on DMind Benchmark, uncovering performance gaps in Web3-specific reasoning and application, particularly in emerging areas like token economics and meme concepts. Even the strongest models face significant challenges in identifying subtle security vulnerabilities and analyzing complex DeFi mechanisms. To foster progress in this area, we publicly release our benchmark dataset, evaluation pipeline, and annotated results at http://www.dmind.ai, offering a valuable resource for advancing specialized domain adaptation and the development of more robust Web3-enabled LLMs.
Causal Discovery on Dependent Binary Data
Dec 28, 2024



The assumption of independence between observations (units) in a dataset is prevalent across various methodologies for learning causal graphical models. However, this assumption often finds itself in conflict with real-world data, posing challenges to accurate structure learning. We propose a decorrelation-based approach for causal graph learning on dependent binary data, where the local conditional distribution is defined by a latent utility model with dependent errors across units. We develop a pairwise maximum likelihood method to estimate the covariance matrix for the dependence among the units. Then, leveraging the estimated covariance matrix, we develop an EM-like iterative algorithm to generate and decorrelate samples of the latent utility variables, which serve as decorrelated data. Any standard causal discovery method can be applied on the decorrelated data to learn the underlying causal graph. We demonstrate that the proposed decorrelation approach significantly improves the accuracy in causal graph learning, through numerical experiments on both synthetic and real-world datasets.
Location-based Radiology Report-Guided Semi-supervised Learning for Prostate Cancer Detection
Jun 18, 2024Prostate cancer is one of the most prevalent malignancies in the world. While deep learning has potential to further improve computer-aided prostate cancer detection on MRI, its efficacy hinges on the exhaustive curation of manually annotated images. We propose a novel methodology of semisupervised learning (SSL) guided by automatically extracted clinical information, specifically the lesion locations in radiology reports, allowing for use of unannotated images to reduce the annotation burden. By leveraging lesion locations, we refined pseudo labels, which were then used to train our location-based SSL model. We show that our SSL method can improve prostate lesion detection by utilizing unannotated images, with more substantial impacts being observed when larger proportions of unannotated images are used.
Multimodal Clinical Pseudo-notes for Emergency Department Prediction Tasks using Multiple Embedding Model for EHR (MEME)
Jan 31, 2024



In this work, we introduce Multiple Embedding Model for EHR (MEME), an approach that views Electronic Health Records (EHR) as multimodal data. This approach incorporates "pseudo-notes", textual representations of tabular EHR concepts such as diagnoses and medications, and allows us to effectively employ Large Language Models (LLMs) for EHR representation. This framework also adopts a multimodal approach, embedding each EHR modality separately. We demonstrate the effectiveness of MEME by applying it to several tasks within the Emergency Department across multiple hospital systems. Our findings show that MEME surpasses the performance of both single modality embedding methods and traditional machine learning approaches. However, we also observe notable limitations in generalizability across hospital institutions for all tested models.