 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSystematic Evaluation of Time-Frequency Features for Binaural Sound Source Localization
Nov 18, 2025This study presents a systematic evaluation of time-frequency feature design for binaural sound source localization (SSL), focusing on how feature selection influences model performance across diverse conditions. We investigate the performance of a convolutional neural network (CNN) model using various combinations of amplitude-based features (magnitude spectrogram, interaural level difference - ILD) and phase-based features (phase spectrogram, interaural phase difference - IPD). Evaluations on in-domain and out-of-domain data with mismatched head-related transfer functions (HRTFs) reveal that carefully chosen feature combinations often outperform increases in model complexity. While two-feature sets such as ILD + IPD are sufficient for in-domain SSL, generalization to diverse content requires richer inputs combining channel spectrograms with both ILD and IPD. Using the optimal feature sets, our low-complexity CNN model achieves competitive performance. Our findings underscore the importance of feature design in binaural SSL and provide practical guidance for both domain-specific and general-purpose localization.
BINAQUAL: A Full-Reference Objective Localization Similarity Metric for Binaural Audio
May 17, 2025Spatial audio enhances immersion in applications such as virtual reality, augmented reality, gaming, and cinema by creating a three-dimensional auditory experience. Ensuring the spatial fidelity of binaural audio is crucial, given that processes such as compression, encoding, or transmission can alter localization cues. While subjective listening tests like MUSHRA remain the gold standard for evaluating spatial localization quality, they are costly and time-consuming. This paper introduces BINAQUAL, a full-reference objective metric designed to assess localization similarity in binaural audio recordings. BINAQUAL adapts the AMBIQUAL metric, originally developed for localization quality assessment in ambisonics audio format to the binaural domain. We evaluate BINAQUAL across five key research questions, examining its sensitivity to variations in sound source locations, angle interpolations, surround speaker layouts, audio degradations, and content diversity. Results demonstrate that BINAQUAL effectively differentiates between subtle spatial variations and correlates strongly with subjective listening tests, making it a reliable metric for binaural localization quality assessment. The proposed metric provides a robust benchmark for ensuring spatial accuracy in binaural audio processing, paving the way for improved objective evaluations in immersive audio applications.
Binamix -- A Python Library for Generating Binaural Audio Datasets
May 02, 2025The increasing demand for spatial audio in applications such as virtual reality, immersive media, and spatial audio research necessitates robust solutions to generate binaural audio data sets for use in testing and validation. Binamix is an open-source Python library designed to facilitate programmatic binaural mixing using the extensive SADIE II Database, which provides Head Related Impulse Response (HRIR) and Binaural Room Impulse Response (BRIR) data for 20 subjects. The Binamix library provides a flexible and repeatable framework for creating large-scale spatial audio datasets, making it an invaluable resource for codec evaluation, audio quality metric development, and machine learning model training. A range of pre-built example scripts, utility functions, and visualization plots further streamline the process of custom pipeline creation. This paper presents an overview of the library's capabilities, including binaural rendering, impulse response interpolation, and multi-track mixing for various speaker layouts. The tools utilize a modified Delaunay triangulation technique to achieve accurate HRIR/BRIR interpolation where desired angles are not present in the data. By supporting a wide range of parameters such as azimuth, elevation, subject Impulse Responses (IRs), speaker layouts, mixing controls, and more, the library enables researchers to create large binaural datasets for any downstream purpose. Binamix empowers researchers and developers to advance spatial audio applications with reproducible methodologies by offering an open-source solution for binaural rendering and dataset generation. We release the library under the Apache 2.0 License at https://github.com/QxLabIreland/Binamix/
SCOREQ: Speech Quality Assessment with Contrastive Regression
Oct 09, 2024In this paper, we present SCOREQ, a novel approach for speech quality prediction. SCOREQ is a triplet loss function for contrastive regression that addresses the domain generalisation shortcoming exhibited by state of the art no-reference speech quality metrics. In the paper we: (i) illustrate the problem of L2 loss training failing at capturing the continuous nature of the mean opinion score (MOS) labels; (ii) demonstrate the lack of generalisation through a benchmarking evaluation across several speech domains; (iii) outline our approach and explore the impact of the architectural design decisions through incremental evaluation; (iv) evaluate the final model against state of the art models for a wide variety of data and domains. The results show that the lack of generalisation observed in state of the art speech quality metrics is addressed by SCOREQ. We conclude that using a triplet loss function for contrastive regression improves generalisation for speech quality prediction models but also has potential utility across a wide range of applications using regression-based predictive models.
Dialogue Understandability: Why are we streaming movies with subtitles?
Mar 22, 2024



Watching movies and TV shows with subtitles enabled is not simply down to audibility or speech intelligibility. A variety of evolving factors related to technological advances, cinema production and social behaviour challenge our perception and understanding. This study seeks to formalise and give context to these influential factors under a wider and novel term referred to as Dialogue Understandability. We propose a working definition for Dialogue Understandability being a listener's capacity to follow the story without undue cognitive effort or concentration being required that impacts their Quality of Experience (QoE). The paper identifies, describes and categorises the factors that influence Dialogue Understandability mapping them over the QoE framework, a media streaming lifecycle, and the stakeholders involved. We then explore available measurement tools in the literature and link them to the factors they could potentially be used for. The maturity and suitability of these tools is evaluated over a set of pilot experiments. Finally, we reflect on the gaps that still need to be filled, what we can measure and what not, future subjective experiments, and new research trends that could help us to fully characterise Dialogue Understandability.
NOMAD: Unsupervised Learning of Perceptual Embeddings for Speech Enhancement and Non-matching Reference Audio Quality Assessment
Sep 28, 2023This paper presents NOMAD (Non-Matching Audio Distance), a differentiable perceptual similarity metric that measures the distance of a degraded signal against non-matching references. The proposed method is based on learning deep feature embeddings via a triplet loss guided by the Neurogram Similarity Index Measure (NSIM) to capture degradation intensity. During inference, the similarity score between any two audio samples is computed through Euclidean distance of their embeddings. NOMAD is fully unsupervised and can be used in general perceptual audio tasks for audio analysis e.g. quality assessment and generative tasks such as speech enhancement and speech synthesis. The proposed method is evaluated with 3 tasks. Ranking degradation intensity, predicting speech quality, and as a loss function for speech enhancement. Results indicate NOMAD outperforms other non-matching reference approaches in both ranking degradation intensity and quality assessment, exhibiting competitive performance with full-reference audio metrics. NOMAD demonstrates a promising technique that mimics human capabilities in assessing audio quality with non-matching references to learn perceptual embeddings without the need for human-generated labels.
Reduce, Reuse, Recycle: Is Perturbed Data better than Other Language augmentation for Low Resource Self-Supervised Speech Models
Sep 22, 2023



Self-supervised representation learning (SSRL) has improved the performance on downstream phoneme recognition versus supervised models. Training SSRL models requires a large amount of pre-training data and this poses a challenge for low resource languages. A common approach is transferring knowledge from other languages. Instead, we propose to use audio augmentation to pre-train SSRL models in a low resource condition and evaluate phoneme recognition as downstream task. We performed a systematic comparison of augmentation techniques, namely: pitch variation, noise addition, accented target-language speech and other language speech. We found combined augmentations (noise/pitch) was the best augmentation strategy outperforming accent and language knowledge transfer. We compared the performance with various quantities and types of pre-training data. We examined the scaling factor of augmented data to achieve equivalent performance to models pre-trained with target domain speech. Our findings suggest that for resource constrained languages, in-domain synthetic augmentation can outperform knowledge transfer from accented or other language speech.
Learning Music Representations with wav2vec 2.0
Oct 27, 2022



Learning music representations that are general-purpose offers the flexibility to finetune several downstream tasks using smaller datasets. The wav2vec 2.0 speech representation model showed promising results in many downstream speech tasks, but has been less effective when adapted to music. In this paper, we evaluate whether pre-training wav2vec 2.0 directly on music data can be a better solution instead of finetuning the speech model. We illustrate that when pre-training on music data, the discrete latent representations are able to encode the semantic meaning of musical concepts such as pitch and instrument. Our results show that finetuning wav2vec 2.0 pre-trained on music data allows us to achieve promising results on music classification tasks that are competitive with prior work on audio representations. In addition, the results are superior to the pre-trained model on speech embeddings, demonstrating that wav2vec 2.0 pre-trained on music data can be a promising music representation model.
Using Rater and System Metadata to Explain Variance in the VoiceMOS Challenge 2022 Dataset
Sep 14, 2022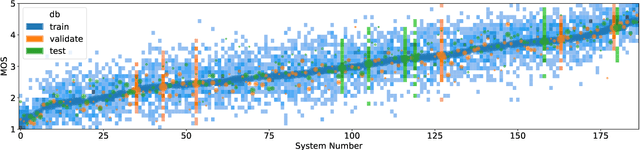
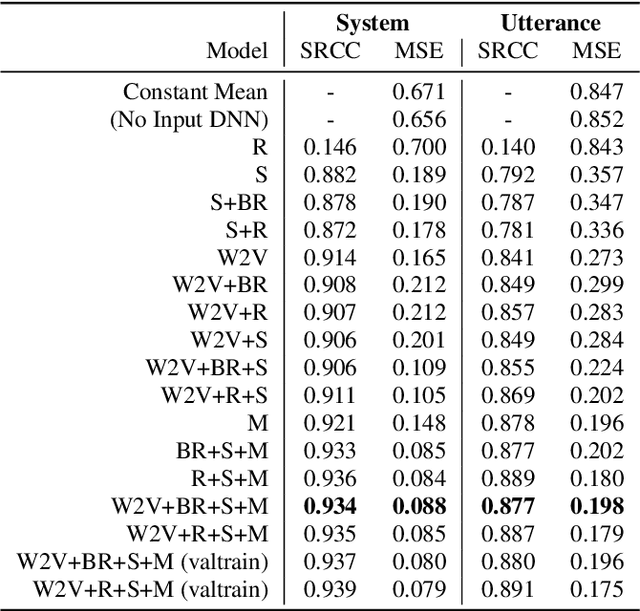
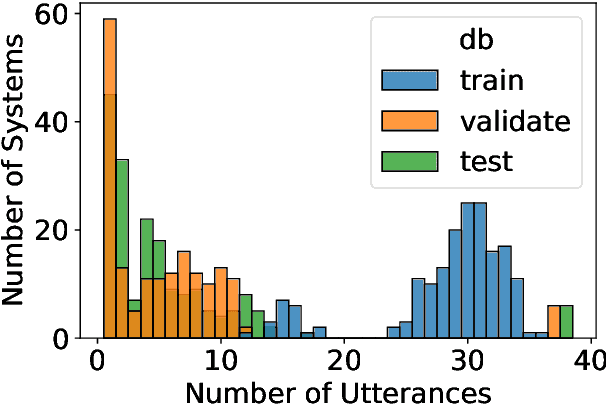
Non-reference speech quality models are important for a growing number of applications. The VoiceMOS 2022 challenge provided a dataset of synthetic voice conversion and text-to-speech samples with subjective labels. This study looks at the amount of variance that can be explained in subjective ratings of speech quality from metadata and the distribution imbalances of the dataset. Speech quality models were constructed using wav2vec 2.0 with additional metadata features that included rater groups and system identifiers and obtained competitive metrics including a Spearman rank correlation coefficient (SRCC) of 0.934 and MSE of 0.088 at the system-level, and 0.877 and 0.198 at the utterance-level. Using data and metadata that the test restricted or blinded further improved the metrics. A metadata analysis showed that the system-level metrics do not represent the model's system-level prediction as a result of the wide variation in the number of utterances used for each system on the validation and test datasets. We conclude that, in general, conditions should have enough utterances in the test set to bound the sample mean error, and be relatively balanced in utterance count between systems, otherwise the utterance-level metrics may be more reliable and interpretable.
A Comparison of Deep Learning MOS Predictors for Speech Synthesis Quality
Apr 05, 2022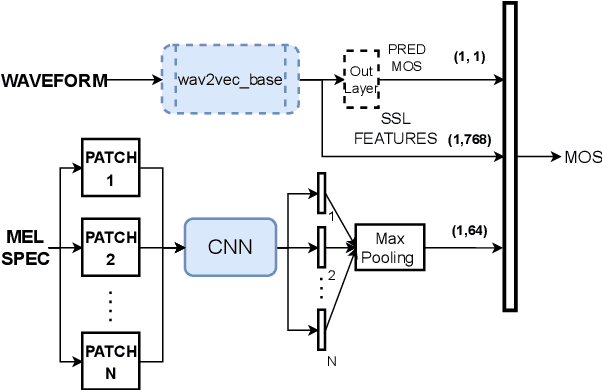
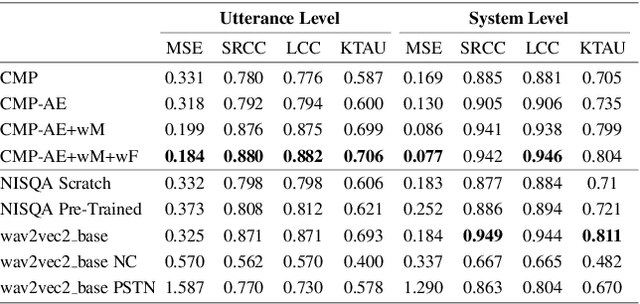
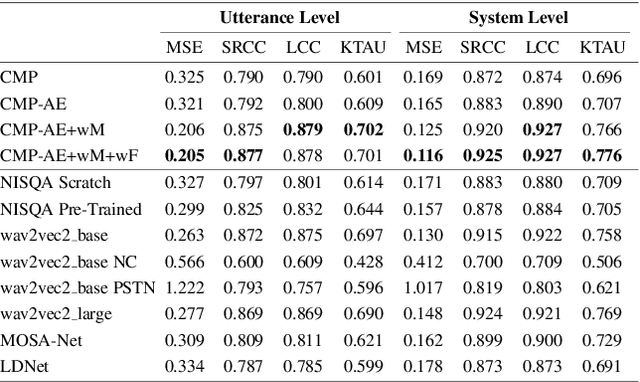
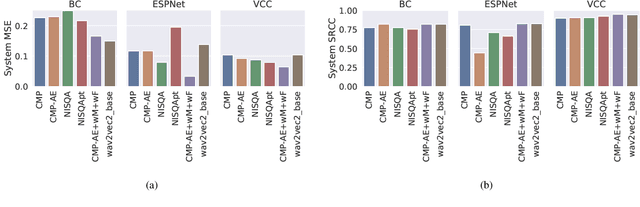
This paper introduces a comparison of deep learning-based techniques for the MOS prediction task of synthesised speech in the Interspeech VoiceMOS challenge. Using the data from the main track of the VoiceMOS challenge we explore both existing predictors and propose new ones. We evaluate two groups of models: NISQA-based models and techniques based on fine-tuning the self-supervised learning (SSL) model wav2vec2_base. Our findings show that a simplified version of NISQA with 40% fewer parameters achieves results close to the original NISQA architecture on both utterance-level and system-level performances. Pre-training NISQA with the NISQA corpus improves utterance-level performance but shows no benefit on the system-level performance. Also, the NISQA-based models perform close to LDNet and MOSANet, 2 out of 3 baselines of the challenge. Fine-tuning wav2vec2_base shows superior performance than the NISQA-based models. We explore the mismatch between natural and synthetic speech and discovered that the performance of the SSL model drops consistently when fine-tuned on natural speech samples. We show that adding CNN features with the SSL model does not improve the baseline performance. Finally, we show that the system type has an impact on the predictions of the non-SSL models.