 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNoise to the Rescue: Escaping Local Minima in Neurosymbolic Local Search
Mar 03, 2025



Deep learning has achieved remarkable success across various domains, largely thanks to the efficiency of backpropagation (BP). However, BP's reliance on differentiability poses challenges in neurosymbolic learning, where discrete computation is combined with neural models. We show that applying BP to Godel logic, which represents conjunction and disjunction as min and max, is equivalent to a local search algorithm for SAT solving, enabling the optimisation of discrete Boolean formulas without sacrificing differentiability. However, deterministic local search algorithms get stuck in local optima. Therefore, we propose the Godel Trick, which adds noise to the model's logits to escape local optima. We evaluate the Godel Trick on SATLIB, and demonstrate its ability to solve a broad range of SAT problems. Additionally, we apply it to neurosymbolic models and achieve state-of-the-art performance on Visual Sudoku, all while avoiding expensive probabilistic reasoning. These results highlight the Godel Trick's potential as a robust, scalable approach for integrating symbolic reasoning with neural architectures.
Simple and Effective Transfer Learning for Neuro-Symbolic Integration
Feb 21, 2024



Deep Learning (DL) techniques have achieved remarkable successes in recent years. However, their ability to generalize and execute reasoning tasks remains a challenge. A potential solution to this issue is Neuro-Symbolic Integration (NeSy), where neural approaches are combined with symbolic reasoning. Most of these methods exploit a neural network to map perceptions to symbols and a logical reasoner to predict the output of the downstream task. These methods exhibit superior generalization capacity compared to fully neural architectures. However, they suffer from several issues, including slow convergence, learning difficulties with complex perception tasks, and convergence to local minima. This paper proposes a simple yet effective method to ameliorate these problems. The key idea involves pretraining a neural model on the downstream task. Then, a NeSy model is trained on the same task via transfer learning, where the weights of the perceptual part are injected from the pretrained network. The key observation of our work is that the neural network fails to generalize only at the level of the symbolic part while being perfectly capable of learning the mapping from perceptions to symbols. We have tested our training strategy on various SOTA NeSy methods and datasets, demonstrating consistent improvements in the aforementioned problems.
Deep Symbolic Learning: Discovering Symbols and Rules from Perceptions
Aug 24, 2022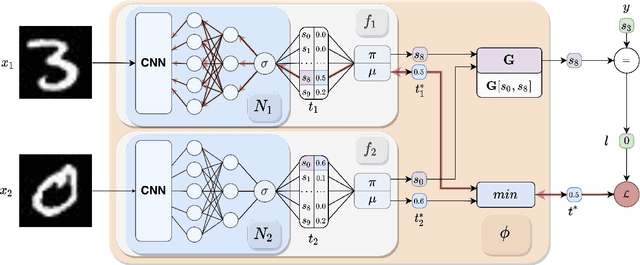
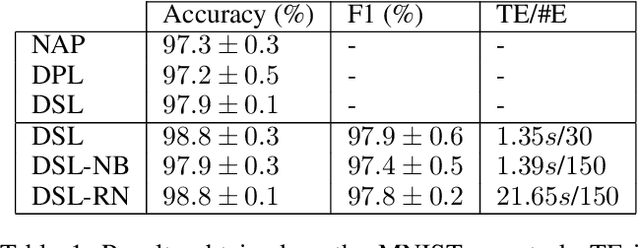
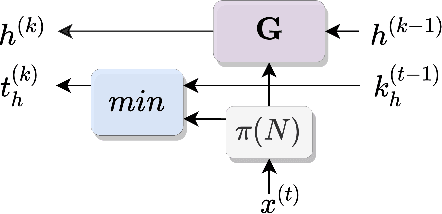
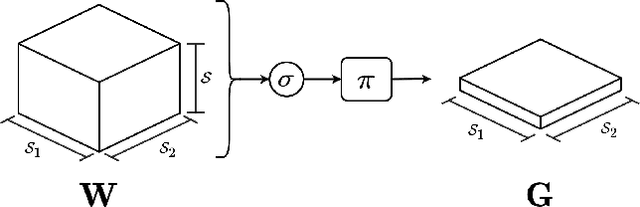
Neuro-Symbolic (NeSy) integration combines symbolic reasoning with Neural Networks (NNs) for tasks requiring perception and reasoning. Most NeSy systems rely on continuous relaxation of logical knowledge and no discrete decisions are made within the model pipeline. Furthermore, these methods assume that the symbolic rules are given. In this paper, we propose Deep Symbolic Learning (DSL), a NeSy system that learns NeSy-functions, i.e., the composition of a (set of) perception functions which map continuous data to discrete symbols, and a symbolic function over the set of symbols. DSL learns simultaneously the perception and symbolic functions, while being trained only on their composition (NeSy-function). The key novelty of DSL is that it can create internal (interpretable) symbolic representations and map them to perception inputs within a differentiable NN learning pipeline. The created symbols are automatically selected to generate symbolic functions that best explain the data. We provide experimental analysis to substantiate the efficacy of DSL in simultaneously learning perception and symbolic functions.
Refining neural network predictions using background knowledge
Jun 10, 2022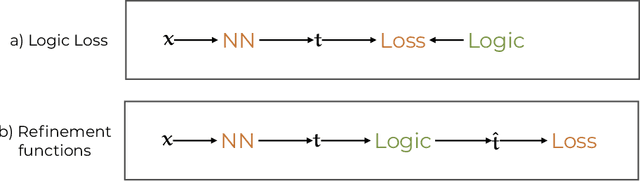
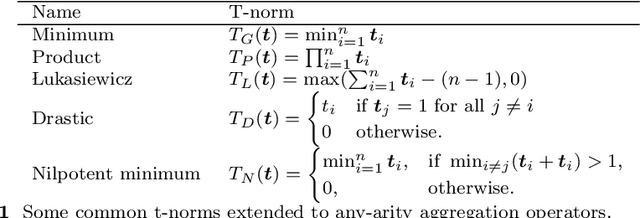
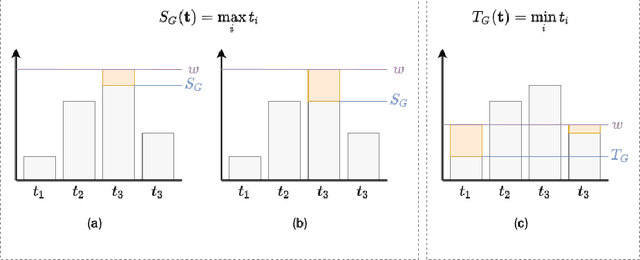
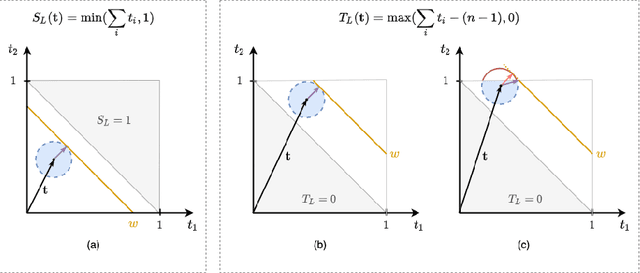
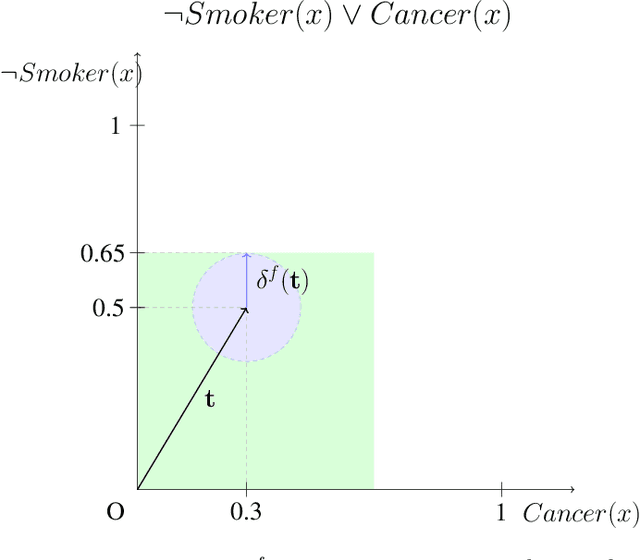
Recent work has showed we can use logical background knowledge in learning system to compensate for a lack of labeled training data. Many such methods work by creating a loss function that encodes this knowledge. However, often the logic is discarded after training, even if it is still useful at test-time. Instead, we ensure neural network predictions satisfy the knowledge by refining the predictions with an extra computation step. We introduce differentiable refinement functions that find a corrected prediction close to the original prediction. We study how to effectively and efficiently compute these refinement functions. Using a new algorithm, we combine refinement functions to find refined predictions for logical formulas of any complexity. This algorithm finds optimal refinements on complex SAT formulas in significantly fewer iterations and frequently finds solutions where gradient descent can not.
Knowledge Enhanced Neural Networks for relational domains
May 31, 2022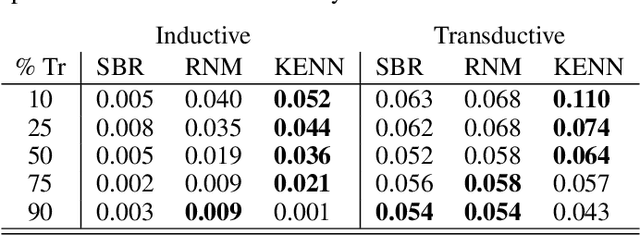
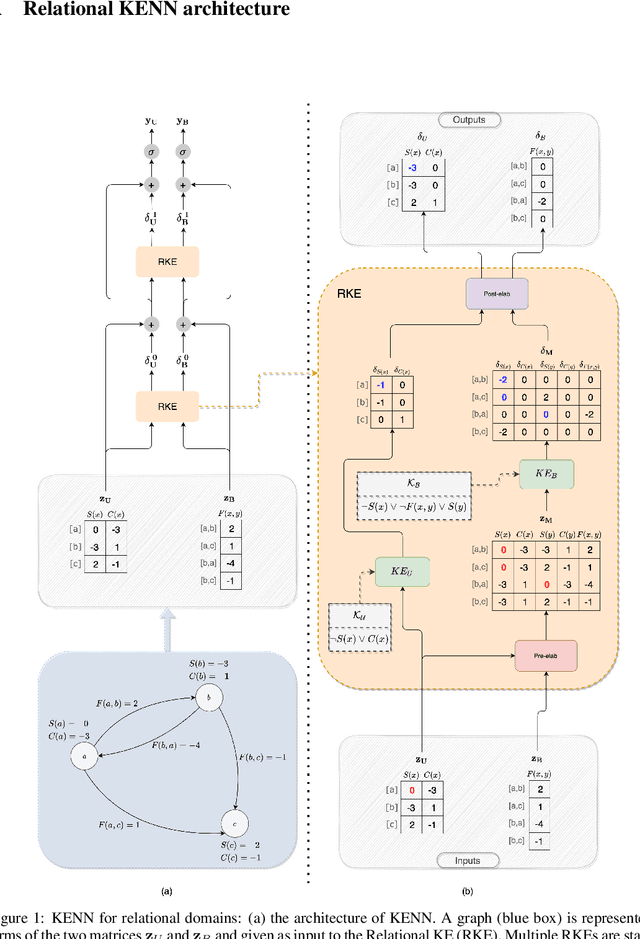
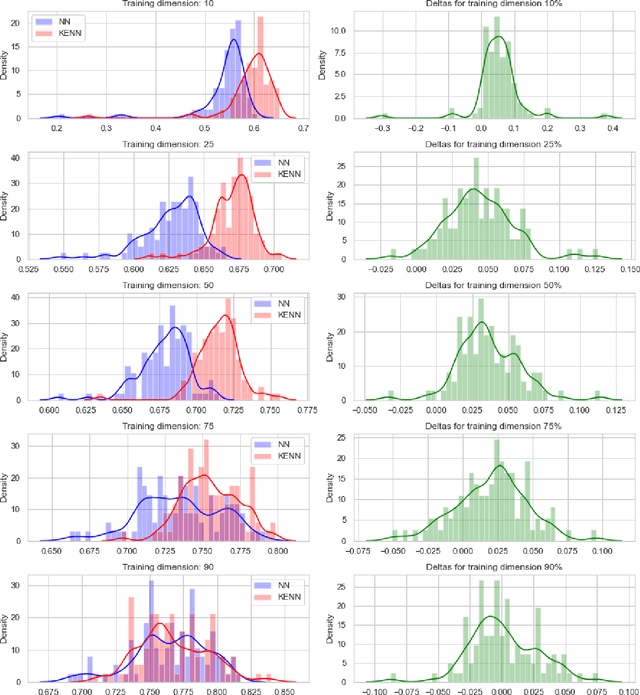
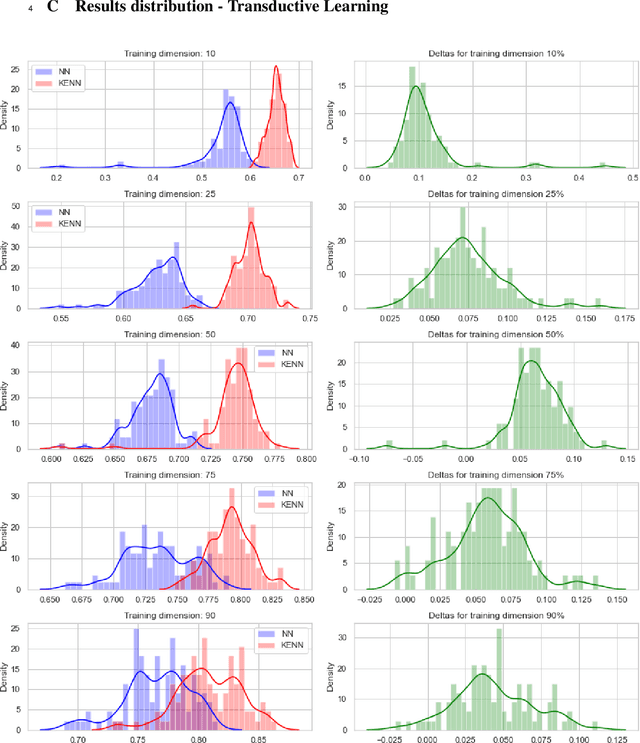
In the recent past, there has been a growing interest in Neural-Symbolic Integration frameworks, i.e., hybrid systems that integrate connectionist and symbolic approaches to obtain the best of both worlds. In this work we focus on a specific method, KENN (Knowledge Enhanced Neural Networks), a Neural-Symbolic architecture that injects prior logical knowledge into a neural network by adding on its top a residual layer that modifies the initial predictions accordingly to the knowledge. Among the advantages of this strategy, there is the inclusion of clause weights, learnable parameters that represent the strength of the clauses, meaning that the model can learn the impact of each rule on the final predictions. As a special case, if the training data contradicts a constraint, KENN learns to ignore it, making the system robust to the presence of wrong knowledge. In this paper, we propose an extension of KENN for relational data. One of the main advantages of KENN resides in its scalability, thanks to a flexible treatment of dependencies between the rules obtained by stacking multiple logical layers. We show experimentally the efficacy of this strategy. The results show that KENN is capable of increasing the performances of the underlying neural network, obtaining better or comparable accuracies in respect to other two related methods that combine learning with logic, requiring significantly less time for learning.
Neural Networks Enhancement through Prior Logical Knowledge
Sep 13, 2020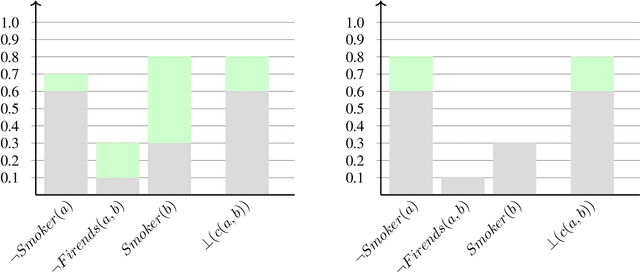
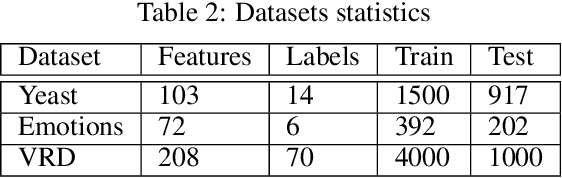
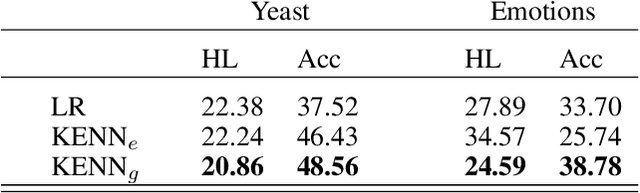
In the recent past, there has been a growing interest in Neural-Symbolic Integration frameworks, i.e., hybrid systems that integrate connectionist and symbolic approaches: on the one hand, neural networks show remarkable abilities to learn from a large amount of data in presence of noise, on the other, pure symbolic methods can perform reasoning as well as learning from few samples. By combining the two paradigms, it should be possible to obtain a system that can both learn from data and apply inference over some background knowledge. Here we propose KENN (Knowledge Enhanced Neural Networks), a Neural-Symbolic architecture that injects prior knowledge, codified in a set of universally quantified FOL clauses, into a neural network model. In KENN, clauses are used to generate a new final layer of the neural network which modifies the initial predictions based on the knowledge. Among the advantages of this strategy, there is the possibility to include additional learnable parameters, the clause weights, each of which represents the strength of a specific clause. We evaluated KENN on two standard datasets for multi-label classification, showing that the injection of clauses, automatically extracted from the training data, sensibly improves the performances. In a further experiment with manually curated knowledge, KENN outperformed state-of-the-art methods on the VRD Dataset, where the task is to classify relationships between detected objects in images. Finally, to evaluate how KENN deals with relational data, we tested it with different learning configurations on Citeseer, a standard dataset for Collective Classification. The obtained results show that KENN is capable of increasing the performances of the underlying neural network even in the presence of relational data obtaining results in line with other methods that combine learning with logic.