 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNeuro-symbolic Rule Learning in Real-world Classification Tasks
Mar 29, 2023



Neuro-symbolic rule learning has attracted lots of attention as it offers better interpretability than pure neural models and scales better than symbolic rule learning. A recent approach named pix2rule proposes a neural Disjunctive Normal Form (neural DNF) module to learn symbolic rules with feed-forward layers. Although proved to be effective in synthetic binary classification, pix2rule has not been applied to more challenging tasks such as multi-label and multi-class classifications over real-world data. In this paper, we address this limitation by extending the neural DNF module to (i) support rule learning in real-world multi-class and multi-label classification tasks, (ii) enforce the symbolic property of mutual exclusivity (i.e. predicting exactly one class) in multi-class classification, and (iii) explore its scalability over large inputs and outputs. We train a vanilla neural DNF model similar to pix2rule's neural DNF module for multi-label classification, and we propose a novel extended model called neural DNF-EO (Exactly One) which enforces mutual exclusivity in multi-class classification. We evaluate the classification performance, scalability and interpretability of our neural DNF-based models, and compare them against pure neural models and a state-of-the-art symbolic rule learner named FastLAS. We demonstrate that our neural DNF-based models perform similarly to neural networks, but provide better interpretability by enabling the extraction of logical rules. Our models also scale well when the rule search space grows in size, in contrast to FastLAS, which fails to learn in multi-class classification tasks with 200 classes and in all multi-label settings.
Sparse Relational Reasoning with Object-Centric Representations
Jul 15, 2022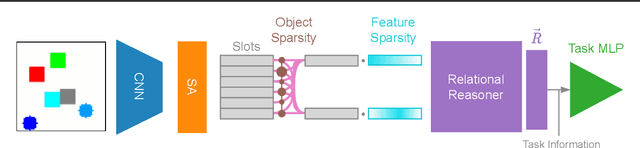
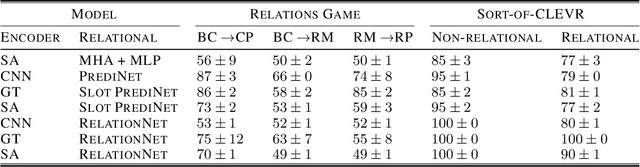
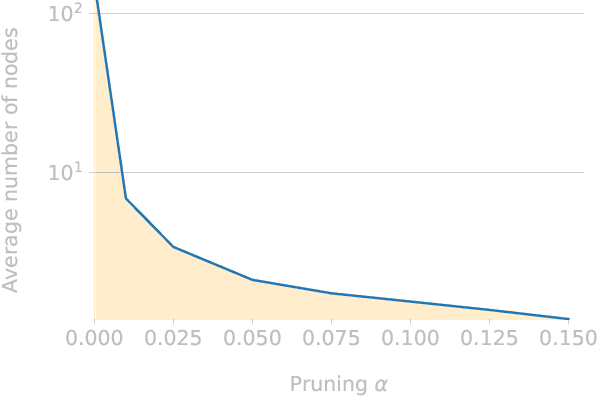

We investigate the composability of soft-rules learned by relational neural architectures when operating over object-centric (slot-based) representations, under a variety of sparsity-inducing constraints. We find that increasing sparsity, especially on features, improves the performance of some models and leads to simpler relations. Additionally, we observe that object-centric representations can be detrimental when not all objects are fully captured; a failure mode to which CNNs are less prone. These findings demonstrate the trade-offs between interpretability and performance, even for models designed to tackle relational tasks.
Automatic Concept Extraction for Concept Bottleneck-based Video Classification
Jun 21, 2022
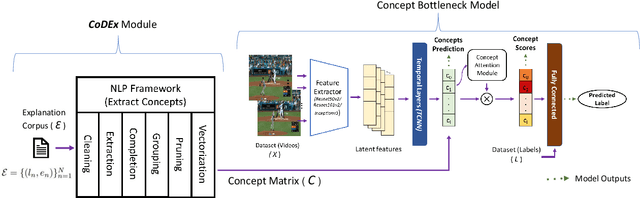
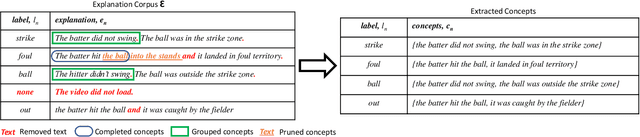

Recent efforts in interpretable deep learning models have shown that concept-based explanation methods achieve competitive accuracy with standard end-to-end models and enable reasoning and intervention about extracted high-level visual concepts from images, e.g., identifying the wing color and beak length for bird-species classification. However, these concept bottleneck models rely on a necessary and sufficient set of predefined concepts-which is intractable for complex tasks such as video classification. For complex tasks, the labels and the relationship between visual elements span many frames, e.g., identifying a bird flying or catching prey-necessitating concepts with various levels of abstraction. To this end, we present CoDEx, an automatic Concept Discovery and Extraction module that rigorously composes a necessary and sufficient set of concept abstractions for concept-based video classification. CoDEx identifies a rich set of complex concept abstractions from natural language explanations of videos-obviating the need to predefine the amorphous set of concepts. To demonstrate our method's viability, we construct two new public datasets that combine existing complex video classification datasets with short, crowd-sourced natural language explanations for their labels. Our method elicits inherent complex concept abstractions in natural language to generalize concept-bottleneck methods to complex tasks.
Hierarchies of Reward Machines
May 31, 2022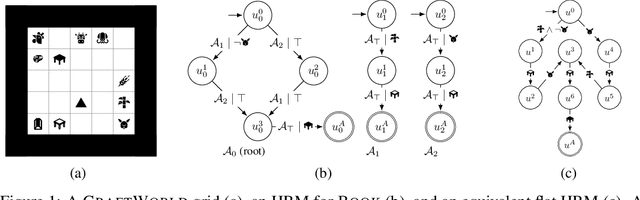

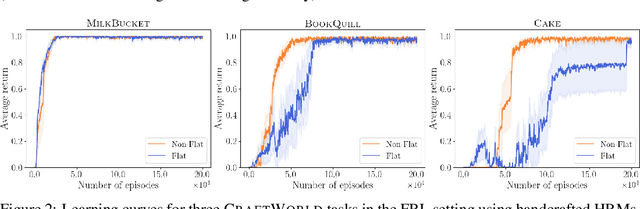
Reward machines (RMs) are a recent formalism for representing the reward function of a reinforcement learning task through a finite-state machine whose edges encode landmarks of the task using high-level events. The structure of RMs enables the decomposition of a task into simpler and independently solvable subtasks that help tackle long-horizon and/or sparse reward tasks. We propose a formalism for further abstracting the subtask structure by endowing an RM with the ability to call other RMs, thus composing a hierarchy of RMs (HRM). We exploit HRMs by treating each call to an RM as an independently solvable subtask using the options framework, and describe a curriculum-based method to induce HRMs from example traces observed by the agent. Our experiments reveal that exploiting a handcrafted HRM leads to faster convergence than with a flat HRM, and that learning an HRM is more scalable than learning an equivalent flat HRM.
Inductive Learning of Complex Knowledge from Raw Data
May 25, 2022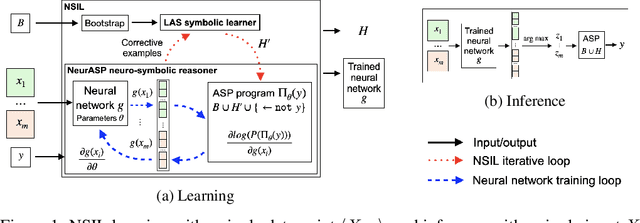
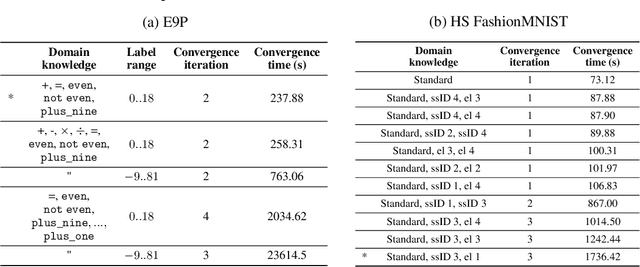
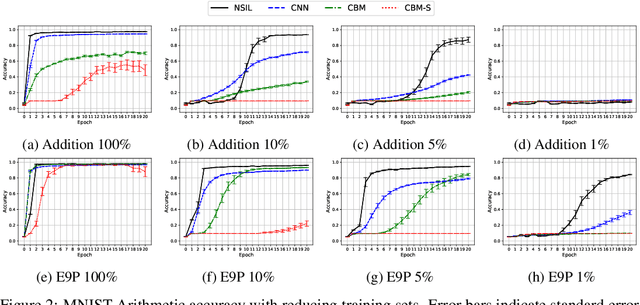
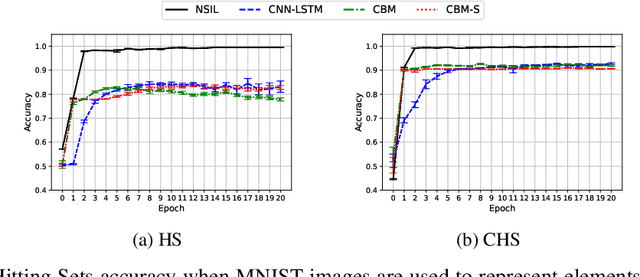
One of the ultimate goals of Artificial Intelligence is to learn generalised and human-interpretable knowledge from raw data. Neuro-symbolic reasoning approaches partly tackle this problem by improving the training of a neural network using a manually engineered symbolic knowledge base. In the case where symbolic knowledge is learned from raw data, this knowledge lacks the expressivity required to solve complex problems. In this paper, we introduce Neuro-Symbolic Inductive Learner (NSIL), an approach that trains a neural network to extract latent concepts from raw data, whilst learning symbolic knowledge that solves complex problems, defined in terms of these latent concepts. The novelty of our approach is a method for biasing a symbolic learner to learn improved knowledge, based on the in-training performance of both neural and symbolic components. We evaluate NSIL on two problem domains that require learning knowledge with different levels of complexity, and demonstrate that NSIL learns knowledge that is not possible to learn with other neuro-symbolic systems, whilst outperforming baseline models in terms of accuracy and data efficiency.
Numerical reasoning in machine reading comprehension tasks: are we there yet?
Sep 16, 2021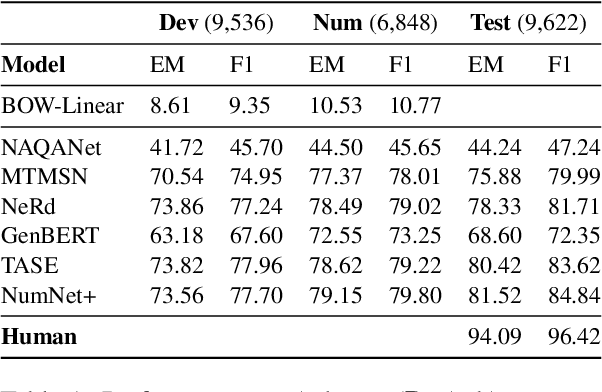
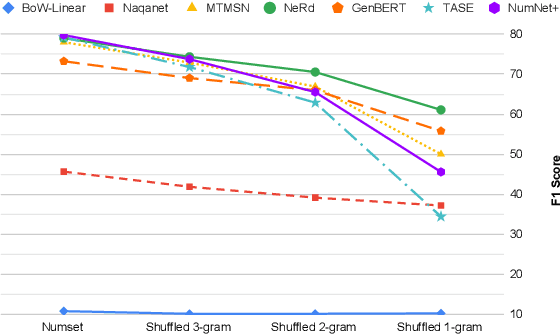
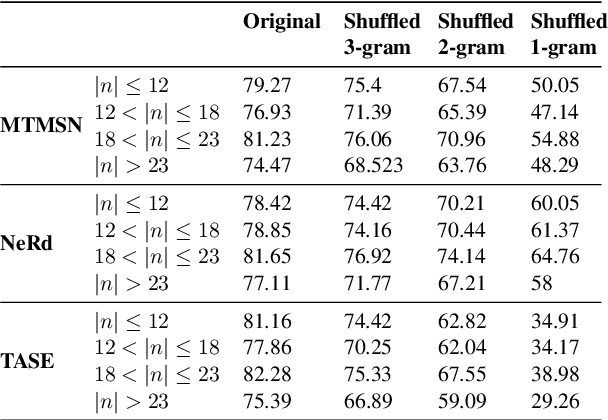
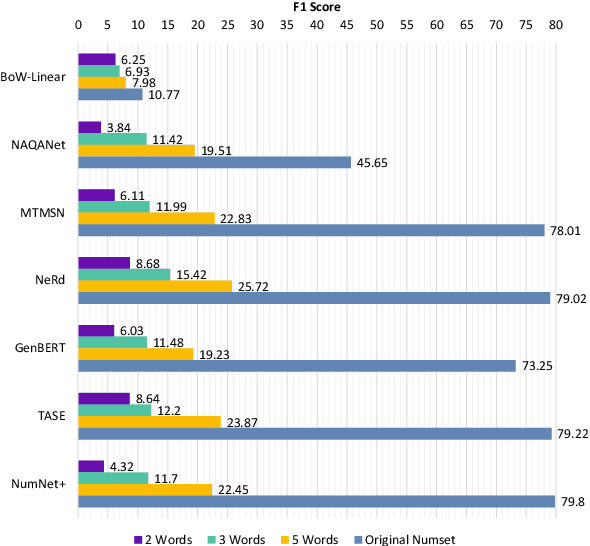
Numerical reasoning based machine reading comprehension is a task that involves reading comprehension along with using arithmetic operations such as addition, subtraction, sorting, and counting. The DROP benchmark (Dua et al., 2019) is a recent dataset that has inspired the design of NLP models aimed at solving this task. The current standings of these models in the DROP leaderboard, over standard metrics, suggest that the models have achieved near-human performance. However, does this mean that these models have learned to reason? In this paper, we present a controlled study on some of the top-performing model architectures for the task of numerical reasoning. Our observations suggest that the standard metrics are incapable of measuring progress towards such tasks.
FF-NSL: Feed-Forward Neural-Symbolic Learner
Jul 02, 2021
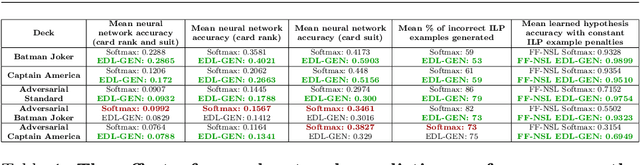

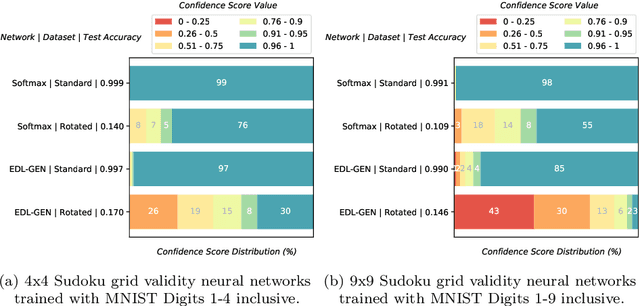
Inductive Logic Programming (ILP) aims to learn generalised, interpretable hypotheses in a data-efficient manner. However, current ILP systems require training examples to be specified in a structured logical form. To address this problem, this paper proposes a neural-symbolic learning framework, called Feed-Forward Neural-Symbolic Learner (FF-NSL), that integrates state-of-the-art ILP systems, based on the Answer Set semantics, with Neural Networks (NNs), in order to learn interpretable hypotheses from labelled unstructured data. To demonstrate the generality and robustness of FF-NSL, we use two datasets subject to distributional shifts, for which pre-trained NNs may give incorrect predictions with high confidence. Experimental results show that FF-NSL outperforms tree-based and neural-based approaches by learning more accurate and interpretable hypotheses with fewer examples.
pix2rule: End-to-end Neuro-symbolic Rule Learning
Jun 14, 2021

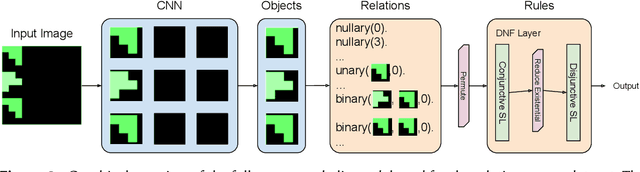
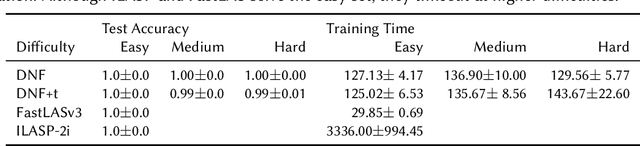
Humans have the ability to seamlessly combine low-level visual input with high-level symbolic reasoning often in the form of recognising objects, learning relations between them and applying rules. Neuro-symbolic systems aim to bring a unifying approach to connectionist and logic-based principles for visual processing and abstract reasoning respectively. This paper presents a complete neuro-symbolic method for processing images into objects, learning relations and logical rules in an end-to-end fashion. The main contribution is a differentiable layer in a deep learning architecture from which symbolic relations and rules can be extracted by pruning and thresholding. We evaluate our model using two datasets: subgraph isomorphism task for symbolic rule learning and an image classification domain with compound relations for learning objects, relations and rules. We demonstrate that our model scales beyond state-of-the-art symbolic learners and outperforms deep relational neural network architectures.
Discrete Reasoning Templates for Natural Language Understanding
Apr 05, 2021

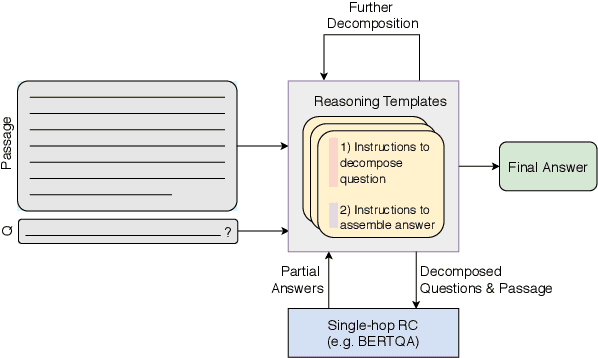
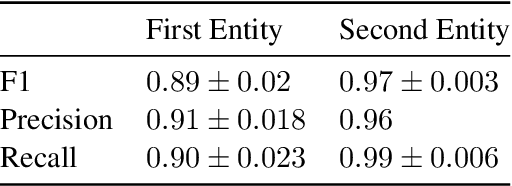
Reasoning about information from multiple parts of a passage to derive an answer is an open challenge for reading-comprehension models. In this paper, we present an approach that reasons about complex questions by decomposing them to simpler subquestions that can take advantage of single-span extraction reading-comprehension models, and derives the final answer according to instructions in a predefined reasoning template. We focus on subtraction-based arithmetic questions and evaluate our approach on a subset of the DROP dataset. We show that our approach is competitive with the state-of-the-art while being interpretable and requires little supervision
HySTER: A Hybrid Spatio-Temporal Event Reasoner
Jan 17, 2021
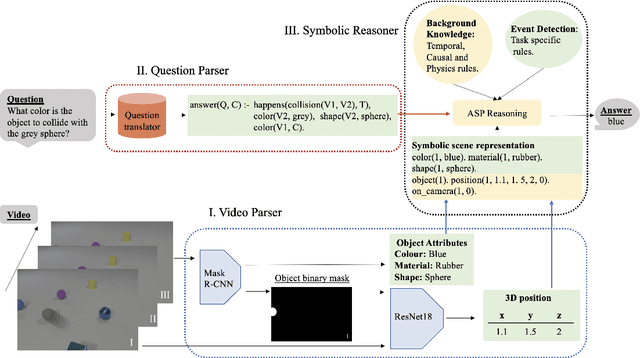

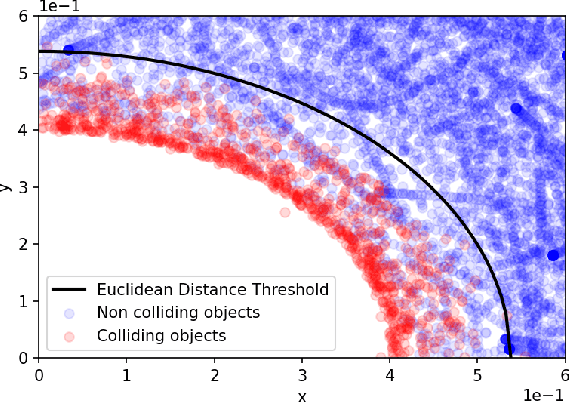
The task of Video Question Answering (VideoQA) consists in answering natural language questions about a video and serves as a proxy to evaluate the performance of a model in scene sequence understanding. Most methods designed for VideoQA up-to-date are end-to-end deep learning architectures which struggle at complex temporal and causal reasoning and provide limited transparency in reasoning steps. We present the HySTER: a Hybrid Spatio-Temporal Event Reasoner to reason over physical events in videos. Our model leverages the strength of deep learning methods to extract information from video frames with the reasoning capabilities and explainability of symbolic artificial intelligence in an answer set programming framework. We define a method based on general temporal, causal and physics rules which can be transferred across tasks. We apply our model to the CLEVRER dataset and demonstrate state-of-the-art results in question answering accuracy. This work sets the foundations for the incorporation of inductive logic programming in the field of VideoQA.