 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFlatland Competition 2020: MAPF and MARL for Efficient Train Coordination on a Grid World
Mar 30, 2021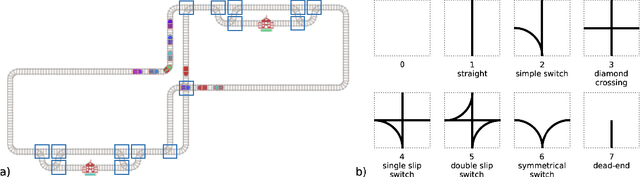
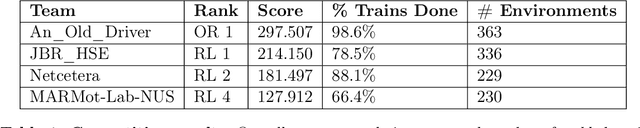
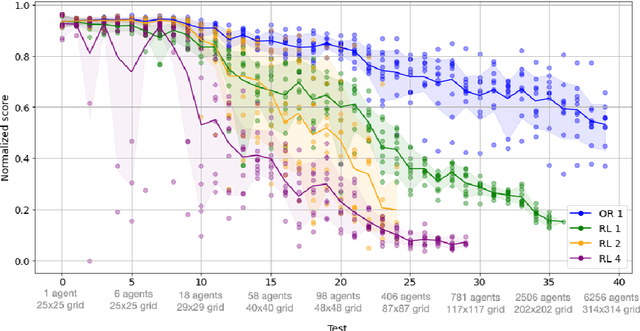
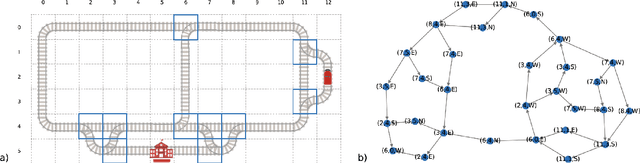
The Flatland competition aimed at finding novel approaches to solve the vehicle re-scheduling problem (VRSP). The VRSP is concerned with scheduling trips in traffic networks and the re-scheduling of vehicles when disruptions occur, for example the breakdown of a vehicle. While solving the VRSP in various settings has been an active area in operations research (OR) for decades, the ever-growing complexity of modern railway networks makes dynamic real-time scheduling of traffic virtually impossible. Recently, multi-agent reinforcement learning (MARL) has successfully tackled challenging tasks where many agents need to be coordinated, such as multiplayer video games. However, the coordination of hundreds of agents in a real-life setting like a railway network remains challenging and the Flatland environment used for the competition models these real-world properties in a simplified manner. Submissions had to bring as many trains (agents) to their target stations in as little time as possible. While the best submissions were in the OR category, participants found many promising MARL approaches. Using both centralized and decentralized learning based approaches, top submissions used graph representations of the environment to construct tree-based observations. Further, different coordination mechanisms were implemented, such as communication and prioritization between agents. This paper presents the competition setup, four outstanding solutions to the competition, and a cross-comparison between them.
Balancing Rational and Other-Regarding Preferences in Cooperative-Competitive Environments
Feb 24, 2021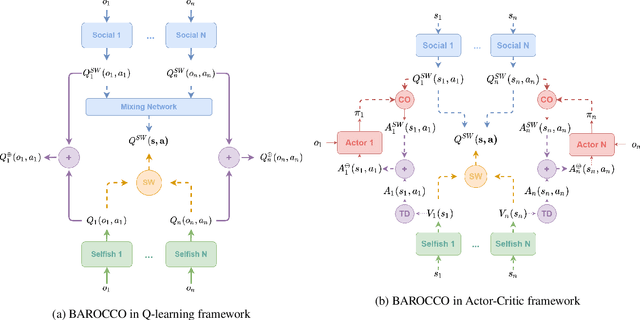


Recent reinforcement learning studies extensively explore the interplay between cooperative and competitive behaviour in mixed environments. Unlike cooperative environments where agents strive towards a common goal, mixed environments are notorious for the conflicts of selfish and social interests. As a consequence, purely rational agents often struggle to achieve and maintain cooperation. A prevalent approach to induce cooperative behaviour is to assign additional rewards based on other agents' well-being. However, this approach suffers from the issue of multi-agent credit assignment, which can hinder performance. This issue is efficiently alleviated in cooperative setting with such state-of-the-art algorithms as QMIX and COMA. Still, when applied to mixed environments, these algorithms may result in unfair allocation of rewards. We propose BAROCCO, an extension of these algorithms capable to balance individual and social incentives. The mechanism behind BAROCCO is to train two distinct but interwoven components that jointly affect each agent's decisions. Our meta-algorithm is compatible with both Q-learning and Actor-Critic frameworks. We experimentally confirm the advantages over the existing methods and explore the behavioural aspects of BAROCCO in two mixed multi-agent setups.
Solving Black-Box Optimization Challenge via Learning Search Space Partition for Local Bayesian Optimization
Dec 18, 2020


This paper describes our approach to solving the black-box optimization challenge through learning search space partition for local Bayesian optimization. We develop an algorithm for low budget optimization. We further optimize the hyper-parameters of our algorithm using Bayesian optimization. Our approach has been ranked 3rd in the competition.
End-to-end Deep Object Tracking with Circular Loss Function for Rotated Bounding Box
Dec 17, 2020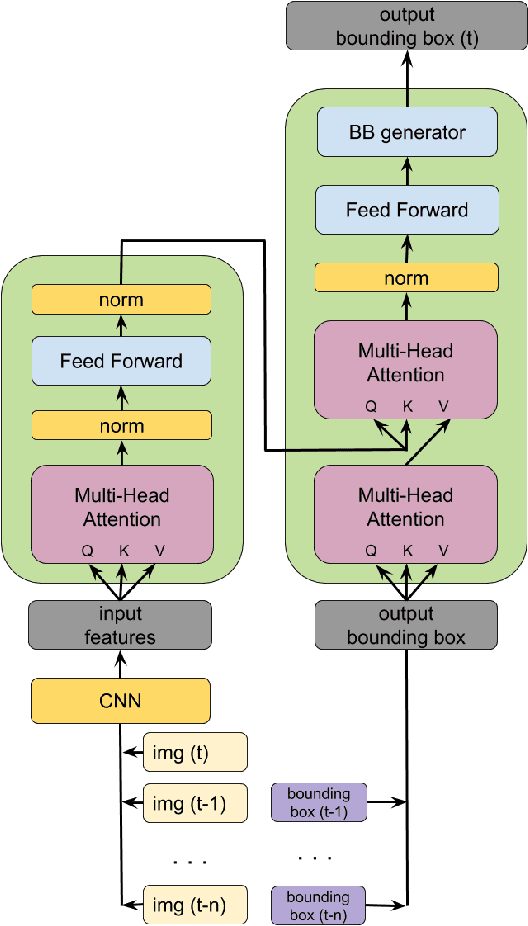
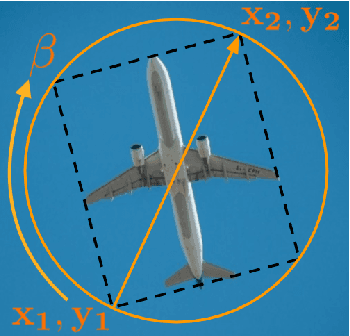
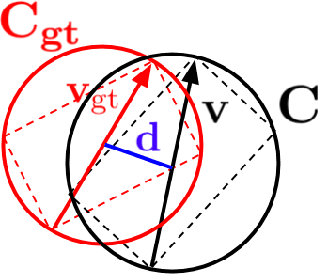
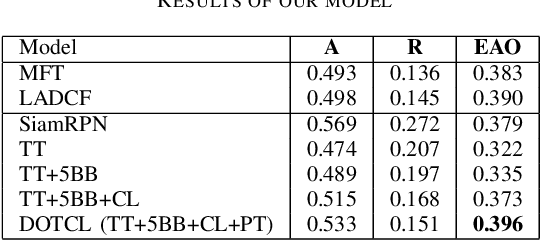
The task object tracking is vital in numerous applications such as autonomous driving, intelligent surveillance, robotics, etc. This task entails the assigning of a bounding box to an object in a video stream, given only the bounding box for that object on the first frame. In 2015, a new type of video object tracking (VOT) dataset was created that introduced rotated bounding boxes as an extension of axis-aligned ones. In this work, we introduce a novel end-to-end deep learning method based on the Transformer Multi-Head Attention architecture. We also present a new type of loss function, which takes into account the bounding box overlap and orientation. Our Deep Object Tracking model with Circular Loss Function (DOTCL) shows an considerable improvement in terms of robustness over current state-of-the-art end-to-end deep learning models. It also outperforms state-of-the-art object tracking methods on VOT2018 dataset in terms of expected average overlap (EAO) metric.
MAGNet: Multi-agent Graph Network for Deep Multi-agent Reinforcement Learning
Dec 17, 2020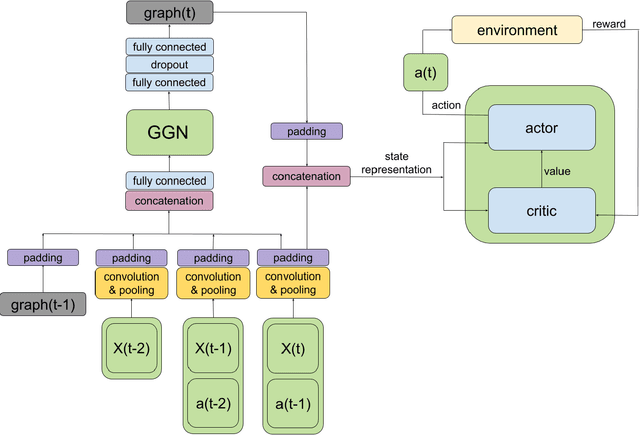
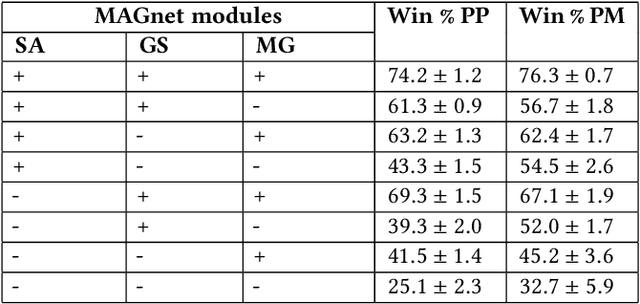

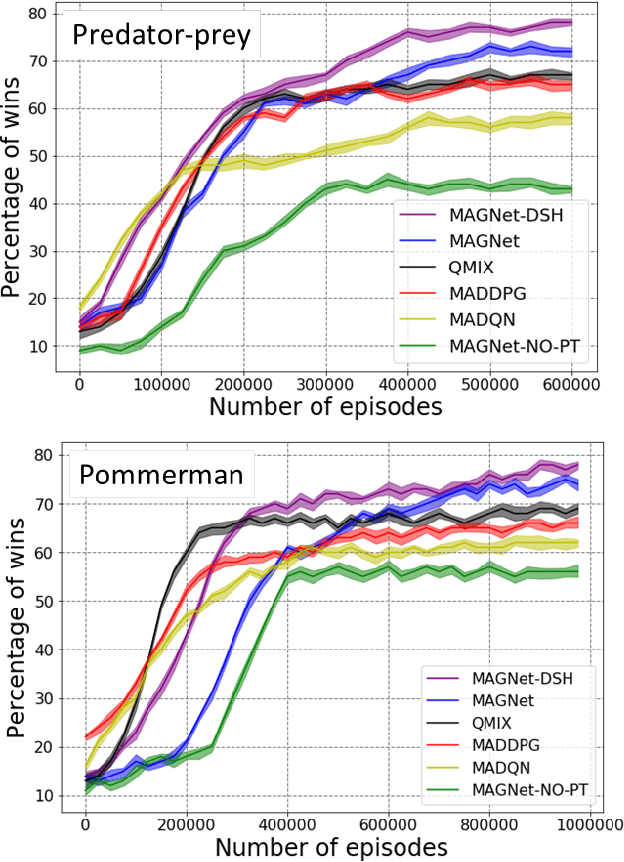
Over recent years, deep reinforcement learning has shown strong successes in complex single-agent tasks, and more recently this approach has also been applied to multi-agent domains. In this paper, we propose a novel approach, called MAGNet, to multi-agent reinforcement learning that utilizes a relevance graph representation of the environment obtained by a self-attention mechanism, and a message-generation technique. We applied our MAGnet approach to the synthetic predator-prey multi-agent environment and the Pommerman game and the results show that it significantly outperforms state-of-the-art MARL solutions, including Multi-agent Deep Q-Networks (MADQN), Multi-agent Deep Deterministic Policy Gradient (MADDPG), and QMIX
Learning to Run with Potential-Based Reward Shaping and Demonstrations from Video Data
Dec 16, 2020
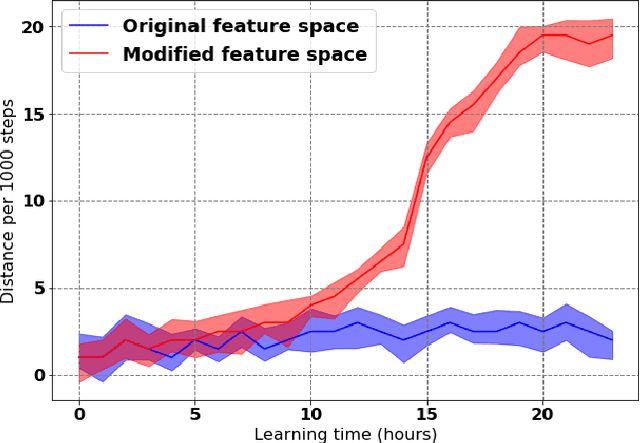
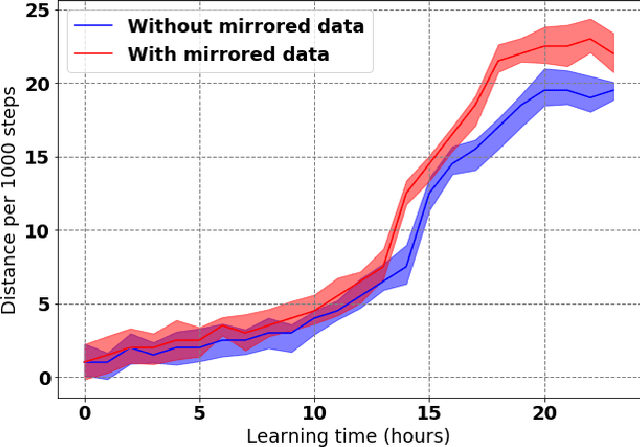
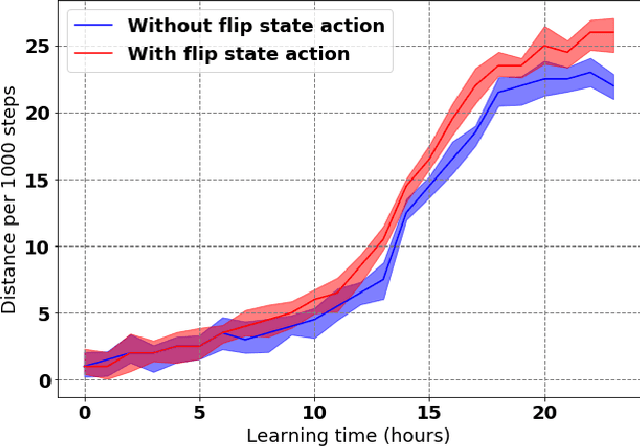
Learning to produce efficient movement behaviour for humanoid robots from scratch is a hard problem, as has been illustrated by the "Learning to run" competition at NIPS 2017. The goal of this competition was to train a two-legged model of a humanoid body to run in a simulated race course with maximum speed. All submissions took a tabula rasa approach to reinforcement learning (RL) and were able to produce relatively fast, but not optimal running behaviour. In this paper, we demonstrate how data from videos of human running (e.g. taken from YouTube) can be used to shape the reward of the humanoid learning agent to speed up the learning and produce a better result. Specifically, we are using the positions of key body parts at regular time intervals to define a potential function for potential-based reward shaping (PBRS). Since PBRS does not change the optimal policy, this approach allows the RL agent to overcome sub-optimalities in the human movements that are shown in the videos. We present experiments in which we combine selected techniques from the top ten approaches from the NIPS competition with further optimizations to create an high-performing agent as a baseline. We then demonstrate how video-based reward shaping improves the performance further, resulting in an RL agent that runs twice as fast as the baseline in 12 hours of training. We furthermore show that our approach can overcome sub-optimal running behaviour in videos, with the learned policy significantly outperforming that of the running agent from the video.
A comparative evaluation of machine learning methods for robot navigation through human crowds
Dec 16, 2020

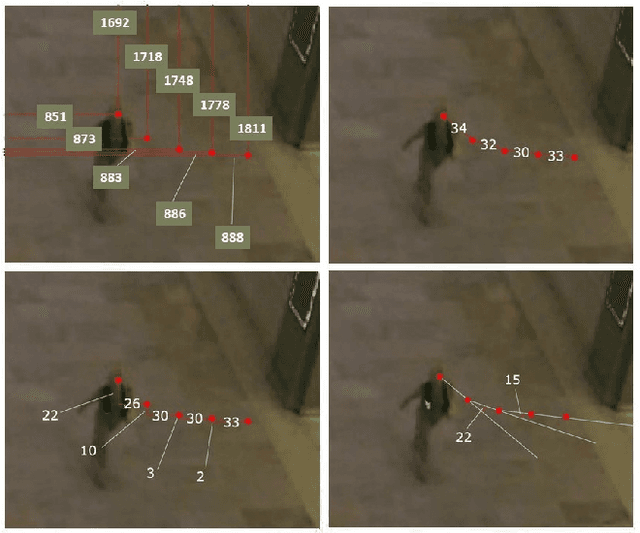
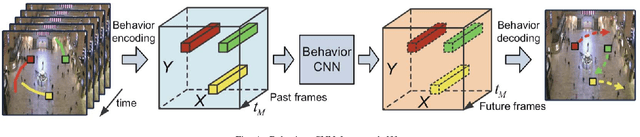
Robot navigation through crowds poses a difficult challenge to AI systems, since the methods should result in fast and efficient movement but at the same time are not allowed to compromise safety. Most approaches to date were focused on the combination of pathfinding algorithms with machine learning for pedestrian walking prediction. More recently, reinforcement learning techniques have been proposed in the research literature. In this paper, we perform a comparative evaluation of pathfinding/prediction and reinforcement learning approaches on a crowd movement dataset collected from surveillance videos taken at Grand Central Station in New York. The results demonstrate the strong superiority of state-of-the-art reinforcement learning approaches over pathfinding with state-of-the-art behaviour prediction techniques.
Deep Learning of Cell Classification using Microscope Images of Intracellular Microtubule Networks
Dec 16, 2020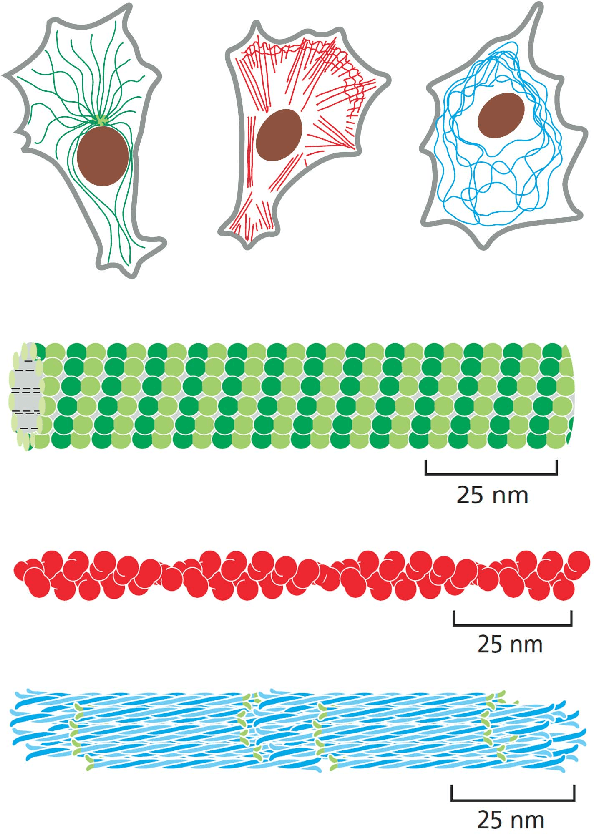
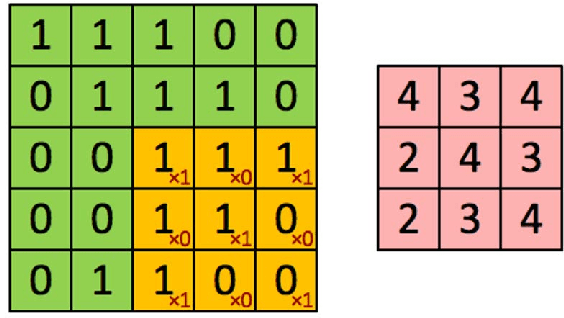
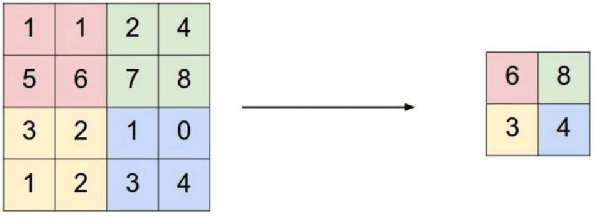
Microtubule networks (MTs) are a component of a cell that may indicate the presence of various chemical compounds and can be used to recognize properties such as treatment resistance. Therefore, the classification of MT images is of great relevance for cell diagnostics. Human experts find it particularly difficult to recognize the levels of chemical compound exposure of a cell. Improving the accuracy with automated techniques would have a significant impact on cell therapy. In this paper we present the application of Deep Learning to MT image classification and evaluate it on a large MT image dataset of animal cells with three degrees of exposure to a chemical agent. The results demonstrate that the learned deep network performs on par or better at the corresponding cell classification task than human experts. Specifically, we show that the task of recognizing different levels of chemical agent exposure can be handled significantly better by the neural network than by human experts.
Continuous Gesture Recognition from sEMG Sensor Data with Recurrent Neural Networks and Adversarial Domain Adaptation
Dec 16, 2020
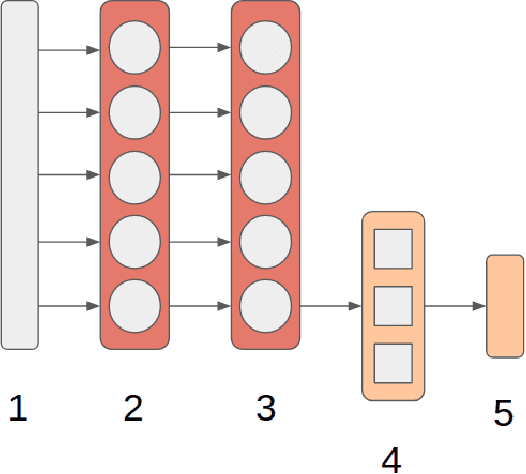
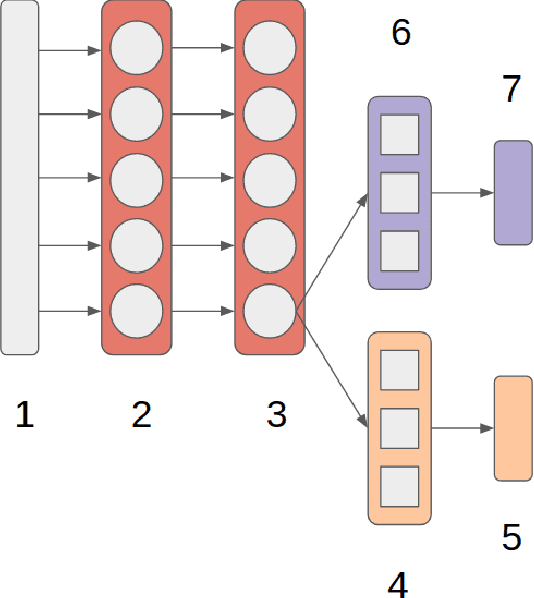
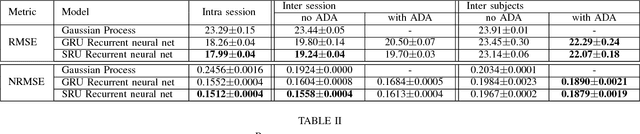
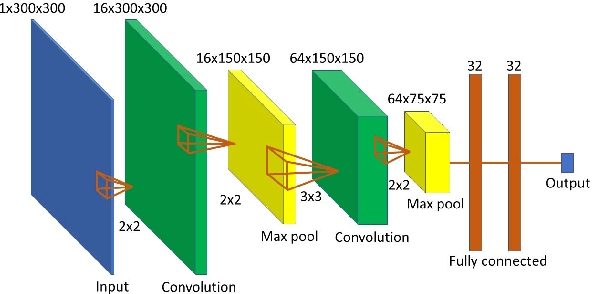
Movement control of artificial limbs has made big advances in recent years. New sensor and control technology enhanced the functionality and usefulness of artificial limbs to the point that complex movements, such as grasping, can be performed to a limited extent. To date, the most successful results were achieved by applying recurrent neural networks (RNNs). However, in the domain of artificial hands, experiments so far were limited to non-mobile wrists, which significantly reduces the functionality of such prostheses. In this paper, for the first time, we present empirical results on gesture recognition with both mobile and non-mobile wrists. Furthermore, we demonstrate that recurrent neural networks with simple recurrent units (SRU) outperform regular RNNs in both cases in terms of gesture recognition accuracy, on data acquired by an arm band sensing electromagnetic signals from arm muscles (via surface electromyography or sEMG). Finally, we show that adding domain adaptation techniques to continuous gesture recognition with RNN improves the transfer ability between subjects, where a limb controller trained on data from one person is used for another person.
Lipophilicity Prediction with Multitask Learning and Molecular Substructures Representation
Nov 24, 2020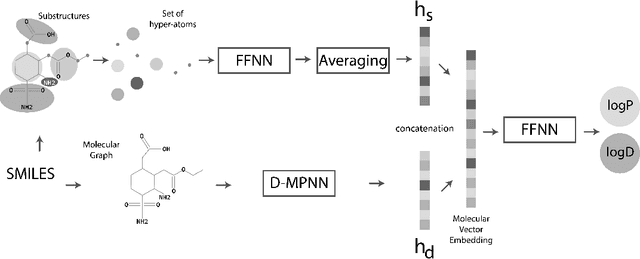

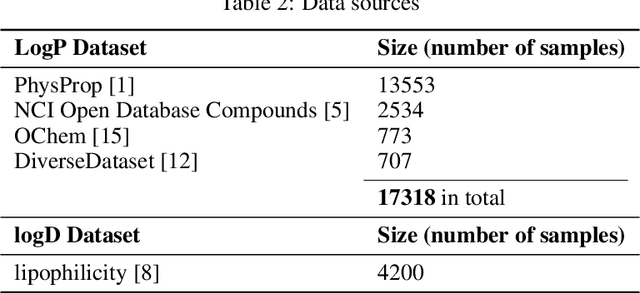

Lipophilicity is one of the factors determining the permeability of the cell membrane to a drug molecule. Hence, accurate lipophilicity prediction is an essential step in the development of new drugs. In this paper, we introduce a novel approach to encoding additional graph information by extracting molecular substructures. By adding a set of generalized atomic features of these substructures to an established Direct Message Passing Neural Network (D-MPNN) we were able to achieve a new state-of-the-art result at the task of prediction of two main lipophilicity coefficients, namely logP and logD descriptors. We further improve our approach by employing a multitask approach to predict logP and logD values simultaneously. Additionally, we present a study of the model performance on symmetric and asymmetric molecules, that may yield insight for further research.