 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeABI Neural Ensemble Model for Gender Prediction Adapt Bar-Ilan Submission for the CLIN29 Shared Task on Gender Prediction
Feb 23, 2019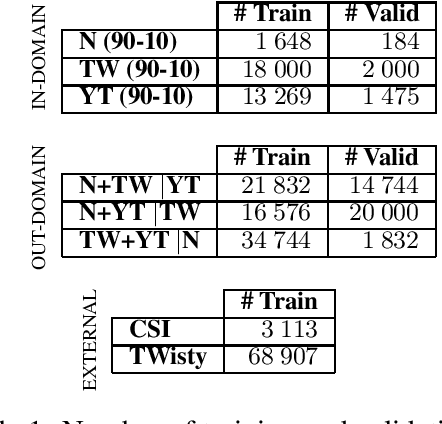

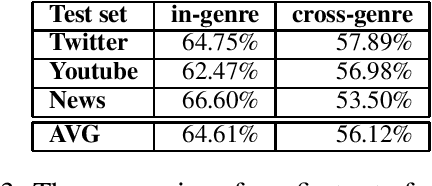
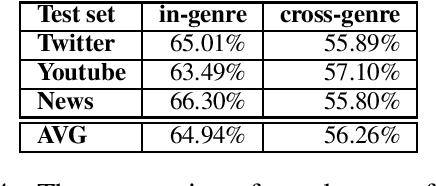
We present our system for the CLIN29 shared task on cross-genre gender detection for Dutch. We experimented with a multitude of neural models (CNN, RNN, LSTM, etc.), more "traditional" models (SVM, RF, LogReg, etc.), different feature sets as well as data pre-processing. The final results suggested that using tokenized, non-lowercased data works best for most of the neural models, while a combination of word clusters, character trigrams and word lists showed to be most beneficial for the majority of the more "traditional" (that is, non-neural) models, beating features used in previous tasks such as n-grams, character n-grams, part-of-speech tags and combinations thereof. In contradiction with the results described in previous comparable shared tasks, our neural models performed better than our best traditional approaches with our best feature set-up. Our final model consisted of a weighted ensemble model combining the top 25 models. Our final model won both the in-domain gender prediction task and the cross-genre challenge, achieving an average accuracy of 64.93% on the in-domain gender prediction task, and 56.26% on cross-genre gender prediction.
The ADAPT System Description for the IWSLT 2018 Basque to English Translation Task
Nov 14, 2018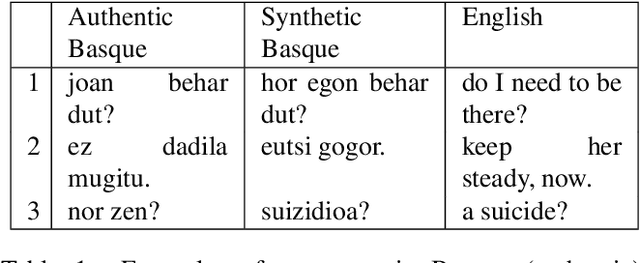
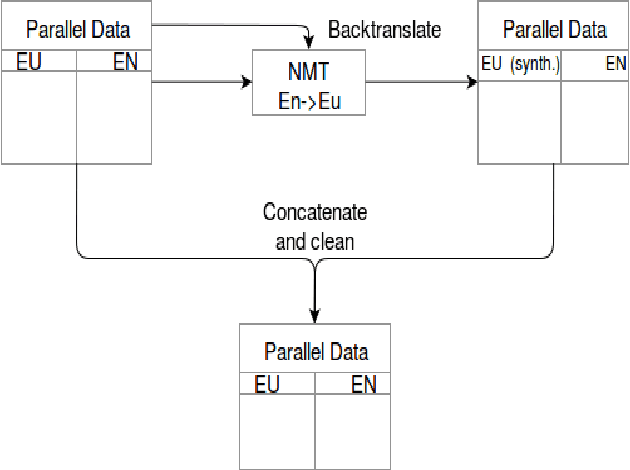
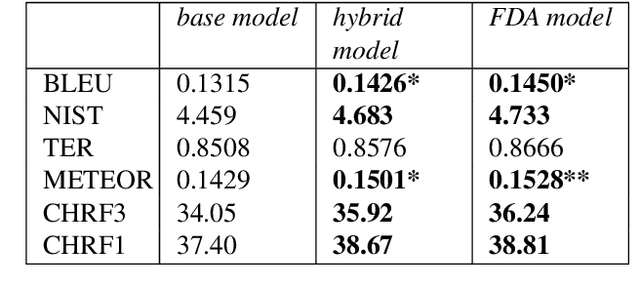
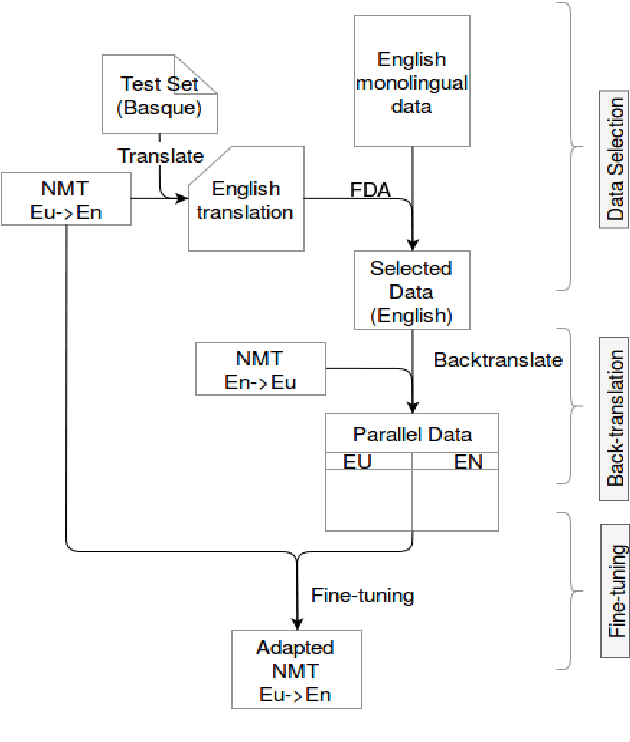
In this paper we present the ADAPT system built for the Basque to English Low Resource MT Evaluation Campaign. Basque is a low-resourced, morphologically-rich language. This poses a challenge for Neural Machine Translation models which usually achieve better performance when trained with large sets of data. Accordingly, we used synthetic data to improve the translation quality produced by a model built using only authentic data. Our proposal uses back-translated data to: (a) create new sentences, so the system can be trained with more data; and (b) translate sentences that are close to the test set, so the model can be fine-tuned to the document to be translated.
Data Selection with Feature Decay Algorithms Using an Approximated Target Side
Nov 07, 2018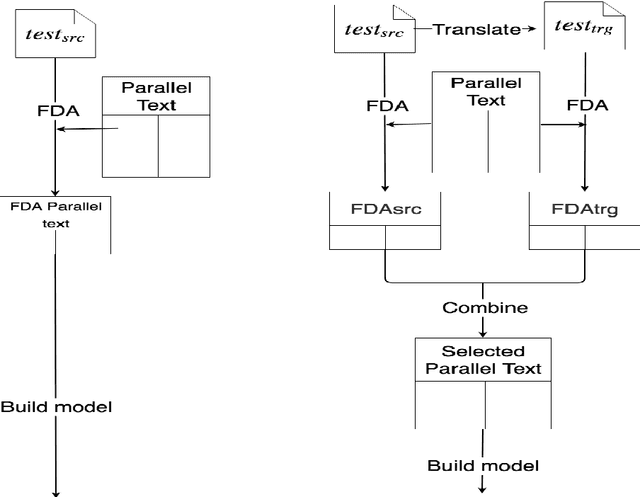
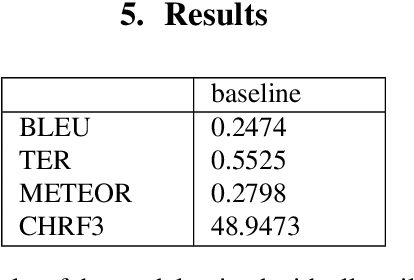
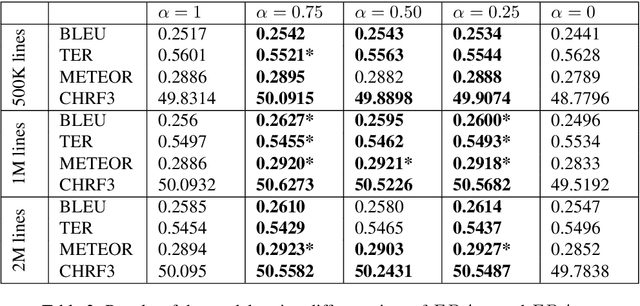
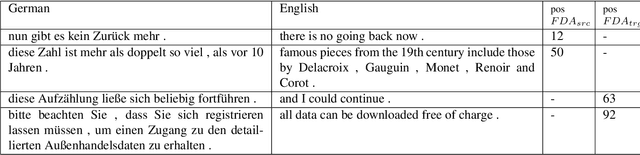
Data selection techniques applied to neural machine translation (NMT) aim to increase the performance of a model by retrieving a subset of sentences for use as training data. One of the possible data selection techniques are transductive learning methods, which select the data based on the test set, i.e. the document to be translated. A limitation of these methods to date is that using the source-side test set does not by itself guarantee that sentences are selected with correct translations, or translations that are suitable given the test-set domain. Some corpora, such as subtitle corpora, may contain parallel sentences with inaccurate translations caused by localization or length restrictions. In order to try to fix this problem, in this paper we propose to use an approximated target-side in addition to the source-side when selecting suitable sentence-pairs for training a model. This approximated target-side is built by pre-translating the source-side. In this work, we explore the performance of this general idea for one specific data selection approach called Feature Decay Algorithms (FDA). We train German-English NMT models on data selected by using the test set (source), the approximated target side, and a mixture of both. Our findings reveal that models built using a combination of outputs of FDA (using the test set and an approximated target side) perform better than those solely using the test set. We obtain a statistically significant improvement of more than 1.5 BLEU points over a model trained with all data, and more than 0.5 BLEU points over a strong FDA baseline that uses source-side information only.
Understanding Meanings in Multilingual Customer Feedback
Jun 05, 2018
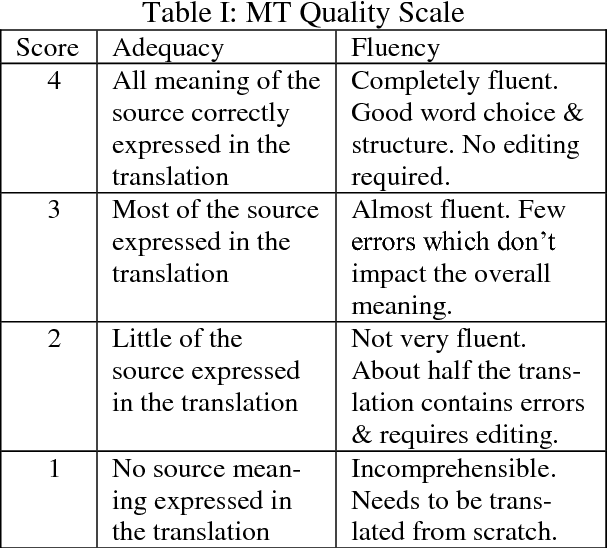
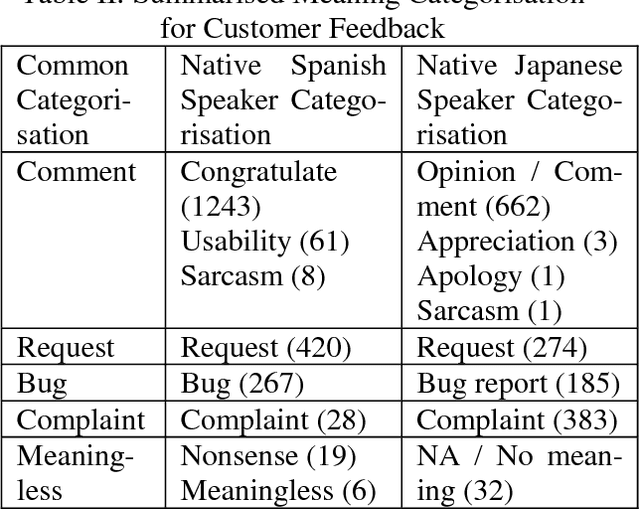
Understanding and being able to react to customer feedback is the most fundamental task in providing good customer service. However, there are two major obstacles for international companies to automatically detect the meaning of customer feedback in a global multilingual environment. Firstly, there is no widely acknowledged categorisation (classes) of meaning for customer feedback. Secondly, the applicability of one meaning categorisation, if it exists, to customer feedback in multiple languages is questionable. In this paper, we extracted representative real world samples of customer feedback from Microsoft Office customers in multiple languages, English, Spanish and Japanese,and concluded a five-class categorisation(comment, request, bug, complaint and meaningless) for meaning classification that could be used across languages in the realm of customer feedback analysis.
Investigating Backtranslation in Neural Machine Translation
Apr 17, 2018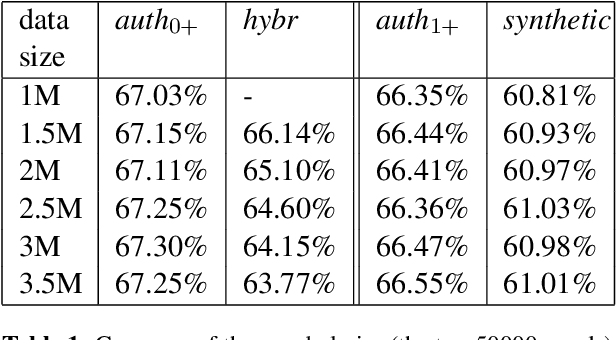
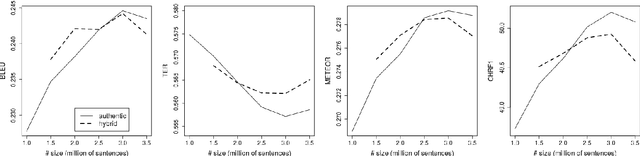
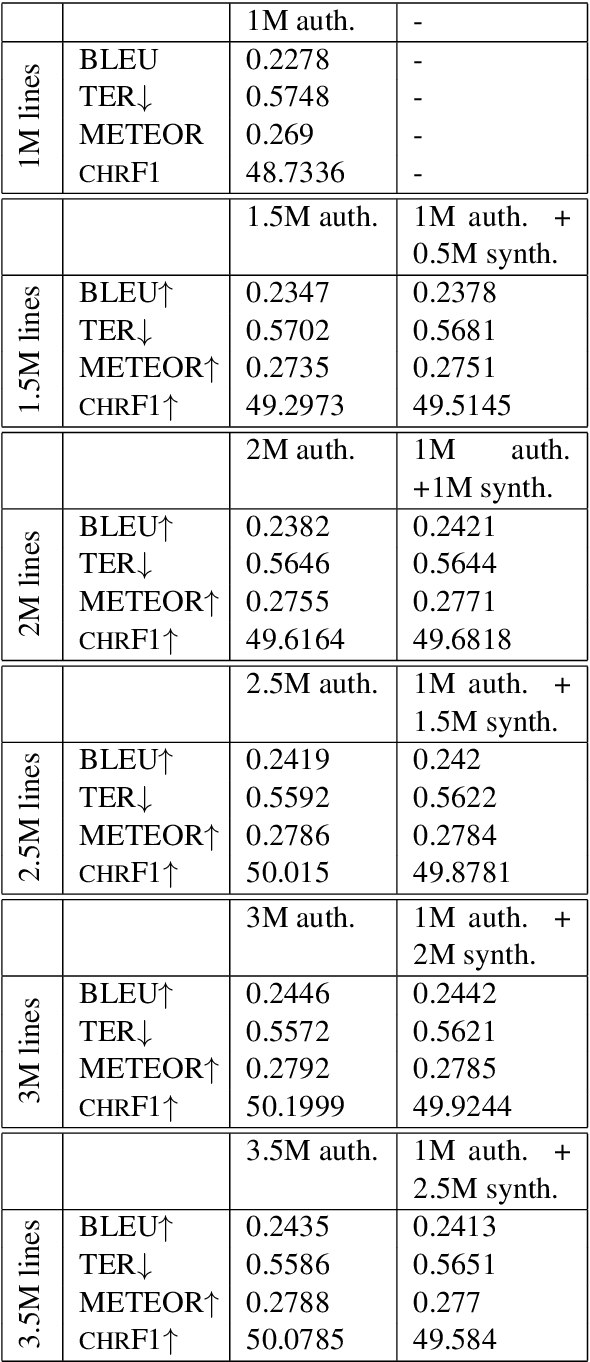
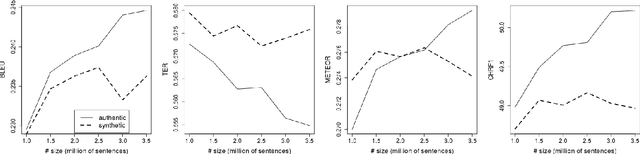
A prerequisite for training corpus-based machine translation (MT) systems -- either Statistical MT (SMT) or Neural MT (NMT) -- is the availability of high-quality parallel data. This is arguably more important today than ever before, as NMT has been shown in many studies to outperform SMT, but mostly when large parallel corpora are available; in cases where data is limited, SMT can still outperform NMT. Recently researchers have shown that back-translating monolingual data can be used to create synthetic parallel corpora, which in turn can be used in combination with authentic parallel data to train a high-quality NMT system. Given that large collections of new parallel text become available only quite rarely, backtranslation has become the norm when building state-of-the-art NMT systems, especially in resource-poor scenarios. However, we assert that there are many unknown factors regarding the actual effects of back-translated data on the translation capabilities of an NMT model. Accordingly, in this work we investigate how using back-translated data as a training corpus -- both as a separate standalone dataset as well as combined with human-generated parallel data -- affects the performance of an NMT model. We use incrementally larger amounts of back-translated data to train a range of NMT systems for German-to-English, and analyse the resulting translation performance.