 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Structured Benchmark for Text-Guided Anomaly Detection: When Language Stops Conditioning the Decision
Jun 01, 2026Industrial anomaly detection has historically been a unimodal task. Recent multimodal vision-language models have produced systems that admit textual input alongside the image and are presented as enabling text-guided zero- and few-shot inspection. Yet these methods are evaluated with protocols inherited from unimodal benchmarks that hold the textual condition constant and therefore cannot measure whether language conditions the decision; whether reported gains reflect text guidance or strong pretrained visual features remains open. We introduce Text-Guided Anomaly Detection (TGAD), a structured benchmark that progressively increases the functional role of language across three scenarios: a controlled prompt-sensitivity setting on MVTec AD; a component-tagged extension of MVTec AD that requires the model to restrict its assessment to an instructed part; and the new Assembled Panel Dataset (APD), a realistic industrial setting that requires both defect-type and component-location knowledge. We evaluate one representative model per paradigm: generative large vision-language, training-free discriminative, and embedding-adaptive discriminative. In all three, the textual interface conditions the decision only superficially: prompt content is absorbed unless the object noun is removed (the generative model's I-AUROC drops from 97.4 to 82.6); component-level instructions do not constrain the decision once defects outside the instructed part are admitted as normal (from 90.3 to 66.3); and when both combine on APD, image-level discrimination collapses below the MVTec level, in one case below chance (71.2, 50.5, 31.5). These results suggest that standard benchmarks overstate the text-guided capabilities of current multimodal anomaly detection systems, and that a protocol of this kind is a prerequisite for models that can be reliably controlled through language for industrial deployment.
Dense image registration and deformable surface reconstruction in presence of occlusions and minimal texture
Sep 25, 2015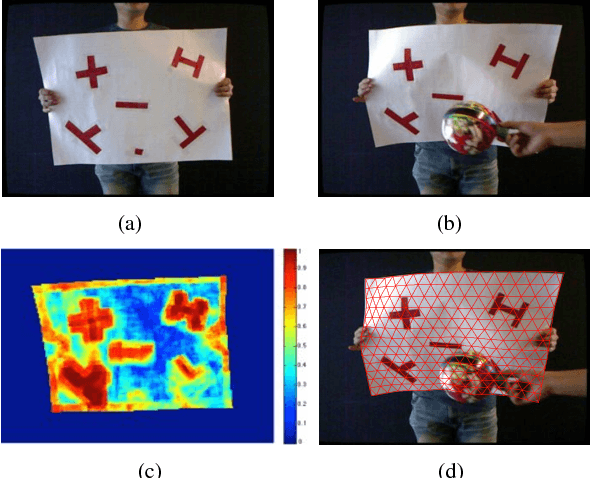
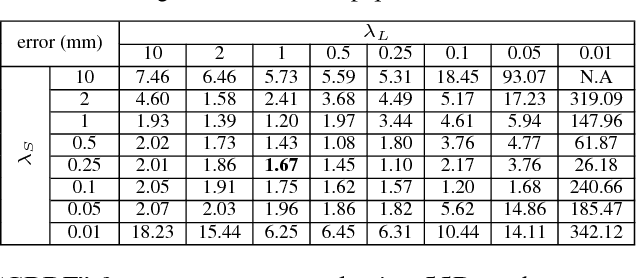
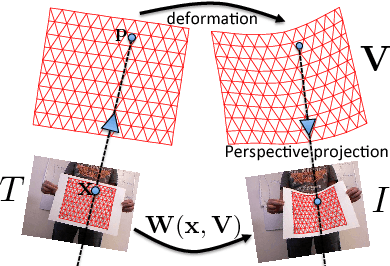
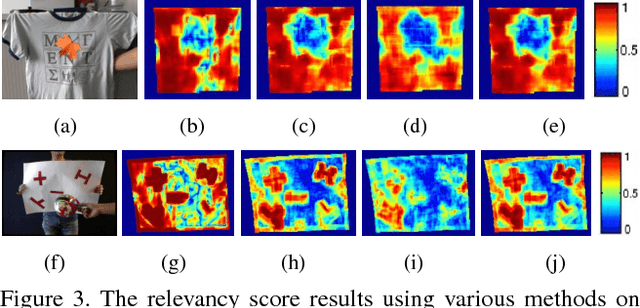
Deformable surface tracking from monocular images is well-known to be under-constrained. Occlusions often make the task even more challenging, and can result in failure if the surface is not sufficiently textured. In this work, we explicitly address the problem of 3D reconstruction of poorly textured, occluded surfaces, proposing a framework based on a template-matching approach that scales dense robust features by a relevancy score. Our approach is extensively compared to current methods employing both local feature matching and dense template alignment. We test on standard datasets as well as on a new dataset (that will be made publicly available) of a sparsely textured, occluded surface. Our framework achieves state-of-the-art results for both well and poorly textured, occluded surfaces.