 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDCTdiff: Intriguing Properties of Image Generative Modeling in the DCT Space
Dec 19, 2024This paper explores image modeling from the frequency space and introduces DCTdiff, an end-to-end diffusion generative paradigm that efficiently models images in the discrete cosine transform (DCT) space. We investigate the design space of DCTdiff and reveal the key design factors. Experiments on different frameworks (UViT, DiT), generation tasks, and various diffusion samplers demonstrate that DCTdiff outperforms pixel-based diffusion models regarding generative quality and training efficiency. Remarkably, DCTdiff can seamlessly scale up to high-resolution generation without using the latent diffusion paradigm. Finally, we illustrate several intriguing properties of DCT image modeling. For example, we provide a theoretical proof of why `image diffusion can be seen as spectral autoregression', bridging the gap between diffusion and autoregressive models. The effectiveness of DCTdiff and the introduced properties suggest a promising direction for image modeling in the frequency space. The code is at \url{https://github.com/forever208/DCTdiff}.
Representation Learning and Identity Adversarial Training for Facial Behavior Understanding
Jul 15, 2024



Facial Action Unit (AU) detection has gained significant research attention as AUs contain complex expression information. In this paper, we unpack two fundamental factors in AU detection: data and subject identity regularization, respectively. Motivated by recent advances in foundation models, we highlight the importance of data and collect a diverse dataset Face9M, comprising 9 million facial images, from multiple public resources. Pretraining a masked autoencoder on Face9M yields strong performance in AU detection and facial expression tasks. We then show that subject identity in AU datasets provides a shortcut learning for the model and leads to sub-optimal solutions to AU predictions. To tackle this generic issue of AU tasks, we propose Identity Adversarial Training (IAT) and demonstrate that a strong IAT regularization is necessary to learn identity-invariant features. Furthermore, we elucidate the design space of IAT and empirically show that IAT circumvents the identity shortcut learning and results in a better solution. Our proposed methods, Facial Masked Autoencoder (FMAE) and IAT, are simple, generic and effective. Remarkably, the proposed FMAE-IAT approach achieves new state-of-the-art F1 scores on BP4D (67.1\%), BP4D+ (66.8\%), and DISFA (70.1\%) databases, significantly outperforming previous work. We release the code and model at https://github.com/forever208/FMAE-IAT, the first open-sourced facial model pretrained on 9 million diverse images.
VideoMambaPro: A Leap Forward for Mamba in Video Understanding
Jun 27, 2024Video understanding requires the extraction of rich spatio-temporal representations, which transformer models achieve through self-attention. Unfortunately, self-attention poses a computational burden. In NLP, Mamba has surfaced as an efficient alternative for transformers. However, Mamba's successes do not trivially extend to computer vision tasks, including those in video analysis. In this paper, we theoretically analyze the differences between self-attention and Mamba. We identify two limitations in Mamba's token processing: historical decay and element contradiction. We propose VideoMambaPro (VMP) that solves the identified limitations by adding masked backward computation and elemental residual connections to a VideoMamba backbone. VideoMambaPro shows state-of-the-art video action recognition performance compared to transformer models, and surpasses VideoMamba by clear margins: 7.9% and 8.1% top-1 on Kinetics-400 and Something-Something V2, respectively. Our VideoMambaPro-M model achieves 91.9% top-1 on Kinetics-400, only 0.2% below InternVideo2-6B but with only 1.2% of its parameters. The combination of high performance and efficiency makes VideoMambaPro an interesting alternative for transformer models.
Enhancing Video Transformers for Action Understanding with VLM-aided Training
Mar 24, 2024



Owing to their ability to extract relevant spatio-temporal video embeddings, Vision Transformers (ViTs) are currently the best performing models in video action understanding. However, their generalization over domains or datasets is somewhat limited. In contrast, Visual Language Models (VLMs) have demonstrated exceptional generalization performance, but are currently unable to process videos. Consequently, they cannot extract spatio-temporal patterns that are crucial for action understanding. In this paper, we propose the Four-tiered Prompts (FTP) framework that takes advantage of the complementary strengths of ViTs and VLMs. We retain ViTs' strong spatio-temporal representation ability but improve the visual encodings to be more comprehensive and general by aligning them with VLM outputs. The FTP framework adds four feature processors that focus on specific aspects of human action in videos: action category, action components, action description, and context information. The VLMs are only employed during training, and inference incurs a minimal computation cost. Our approach consistently yields state-of-the-art performance. For instance, we achieve remarkable top-1 accuracy of 93.8% on Kinetics-400 and 83.4% on Something-Something V2, surpassing VideoMAEv2 by 2.8% and 2.6%, respectively.
TCNet: Continuous Sign Language Recognition from Trajectories and Correlated Regions
Mar 18, 2024



A key challenge in continuous sign language recognition (CSLR) is to efficiently capture long-range spatial interactions over time from the video input. To address this challenge, we propose TCNet, a hybrid network that effectively models spatio-temporal information from Trajectories and Correlated regions. TCNet's trajectory module transforms frames into aligned trajectories composed of continuous visual tokens. In addition, for a query token, self-attention is learned along the trajectory. As such, our network can also focus on fine-grained spatio-temporal patterns, such as finger movements, of a specific region in motion. TCNet's correlation module uses a novel dynamic attention mechanism that filters out irrelevant frame regions. Additionally, it assigns dynamic key-value tokens from correlated regions to each query. Both innovations significantly reduce the computation cost and memory. We perform experiments on four large-scale datasets: PHOENIX14, PHOENIX14-T, CSL, and CSL-Daily, respectively. Our results demonstrate that TCNet consistently achieves state-of-the-art performance. For example, we improve over the previous state-of-the-art by 1.5% and 1.0% word error rate on PHOENIX14 and PHOENIX14-T, respectively.
Elucidating the Exposure Bias in Diffusion Models
Sep 12, 2023Diffusion models have demonstrated impressive generative capabilities, but their 'exposure bias' problem, described as the input mismatch between training and sampling, lacks in-depth exploration. In this paper, we systematically investigate the exposure bias problem in diffusion models by first analytically modelling the sampling distribution, based on which we then attribute the prediction error at each sampling step as the root cause of the exposure bias issue. Furthermore, we discuss potential solutions to this issue and propose an intuitive metric for it. Along with the elucidation of exposure bias, we propose a simple, yet effective, training-free method called Epsilon Scaling to alleviate the exposure bias. We show that Epsilon Scaling explicitly moves the sampling trajectory closer to the vector field learned in the training phase by scaling down the network output (Epsilon), mitigating the input mismatch between training and sampling. Experiments on various diffusion frameworks (ADM, DDPM/DDIM, EDM, LDM), unconditional and conditional settings, and deterministic vs. stochastic sampling verify the effectiveness of our method. The code is available at https://github.com/forever208/ADM-ES; https://github.com/forever208/EDM-ES
A Survey on Computer Vision based Human Analysis in the COVID-19 Era
Nov 07, 2022



The emergence of COVID-19 has had a global and profound impact, not only on society as a whole, but also on the lives of individuals. Various prevention measures were introduced around the world to limit the transmission of the disease, including face masks, mandates for social distancing and regular disinfection in public spaces, and the use of screening applications. These developments also triggered the need for novel and improved computer vision techniques capable of (i) providing support to the prevention measures through an automated analysis of visual data, on the one hand, and (ii) facilitating normal operation of existing vision-based services, such as biometric authentication schemes, on the other. Especially important here, are computer vision techniques that focus on the analysis of people and faces in visual data and have been affected the most by the partial occlusions introduced by the mandates for facial masks. Such computer vision based human analysis techniques include face and face-mask detection approaches, face recognition techniques, crowd counting solutions, age and expression estimation procedures, models for detecting face-hand interactions and many others, and have seen considerable attention over recent years. The goal of this survey is to provide an introduction to the problems induced by COVID-19 into such research and to present a comprehensive review of the work done in the computer vision based human analysis field. Particular attention is paid to the impact of facial masks on the performance of various methods and recent solutions to mitigate this problem. Additionally, a detailed review of existing datasets useful for the development and evaluation of methods for COVID-19 related applications is also provided. Finally, to help advance the field further, a discussion on the main open challenges and future research direction is given.
Fully-attentive and interpretable: vision and video vision transformers for pain detection
Oct 27, 2022



Pain is a serious and costly issue globally, but to be treated, it must first be detected. Vision transformers are a top-performing architecture in computer vision, with little research on their use for pain detection. In this paper, we propose the first fully-attentive automated pain detection pipeline that achieves state-of-the-art performance on binary pain detection from facial expressions. The model is trained on the UNBC-McMaster dataset, after faces are 3D-registered and rotated to the canonical frontal view. In our experiments we identify important areas of the hyperparameter space and their interaction with vision and video vision transformers, obtaining 3 noteworthy models. We analyse the attention maps of one of our models, finding reasonable interpretations for its predictions. We also evaluate Mixup, an augmentation technique, and Sharpness-Aware Minimization, an optimizer, with no success. Our presented models, ViT-1 (F1 score 0.55 +- 0.15), ViViT-1 (F1 score 0.55 +- 0.13), and ViViT-2 (F1 score 0.49 +- 0.04), all outperform earlier works, showing the potential of vision transformers for pain detection. Code is available at https://github.com/IPDTFE/ViT-McMaster
Automatic Analysis of Human Body Representations in Western Art
Oct 17, 2022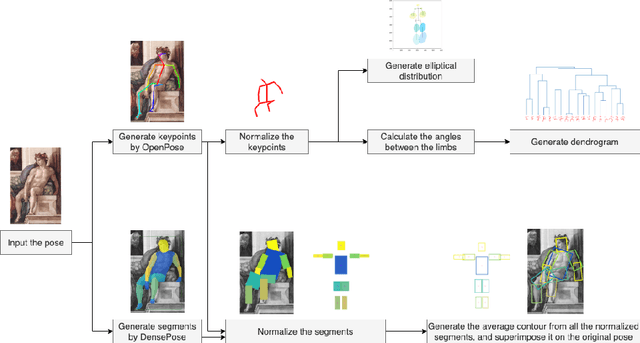
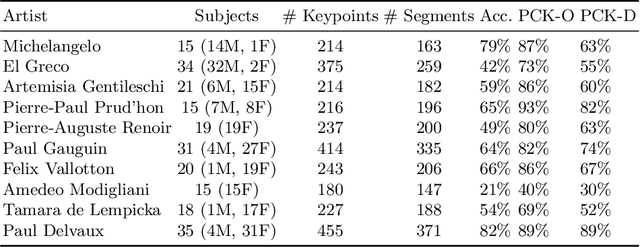


The way the human body is depicted in classical and modern paintings is relevant for art historical analyses. Each artist has certain themes and concerns, resulting in different poses being used more heavily than others. In this paper, we propose a computer vision pipeline to analyse human pose and representations in paintings, which can be used for specific artists or periods. Specifically, we combine two pose estimation approaches (OpenPose and DensePose, respectively) and introduce methods to deal with occlusion and perspective issues. For normalisation, we map the detected poses and contours to Leonardo da Vinci's Vitruvian Man, the classical depiction of body proportions. We propose a visualisation approach for illustrating the articulation of joints in a set of paintings. Combined with a hierarchical clustering of poses, our approach reveals common and uncommon poses used by artists. Our approach improves over purely skeleton based analyses of human body in paintings.
Video-based estimation of pain indicators in dogs
Sep 27, 2022
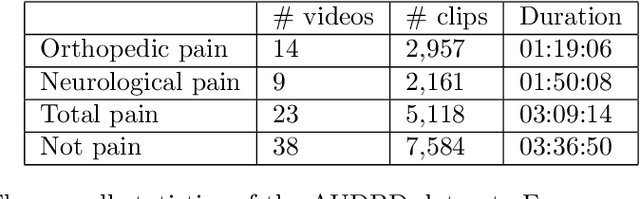
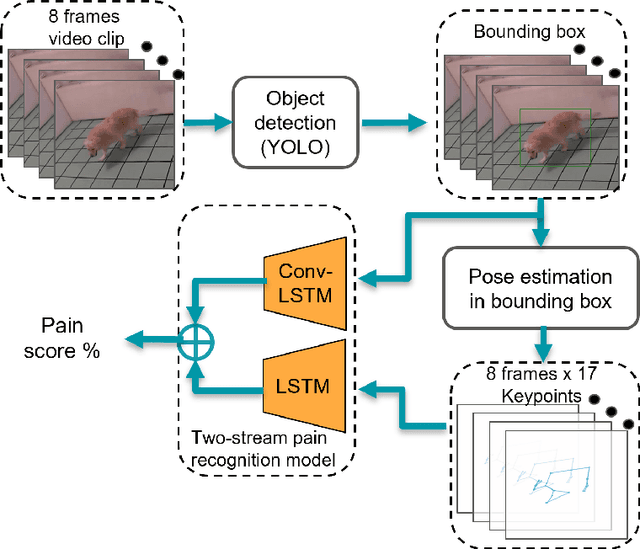
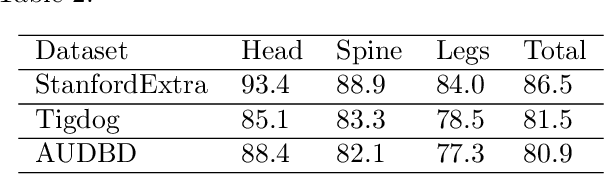
Dog owners are typically capable of recognizing behavioral cues that reveal subjective states of their dogs, such as pain. But automatic recognition of the pain state is very challenging. This paper proposes a novel video-based, two-stream deep neural network approach for this problem. We extract and preprocess body keypoints, and compute features from both keypoints and the RGB representation over the video. We propose an approach to deal with self-occlusions and missing keypoints. We also present a unique video-based dog behavior dataset, collected by veterinary professionals, and annotated for presence of pain, and report good classification results with the proposed approach. This study is one of the first works on machine learning based estimation of dog pain state.