 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStochastic Orthogonal Regularization for deep projective priors
May 19, 2025Many crucial tasks of image processing and computer vision are formulated as inverse problems. Thus, it is of great importance to design fast and robust algorithms to solve these problems. In this paper, we focus on generalized projected gradient descent (GPGD) algorithms where generalized projections are realized with learned neural networks and provide state-of-the-art results for imaging inverse problems. Indeed, neural networks allow for projections onto unknown low-dimensional sets that model complex data, such as images. We call these projections deep projective priors. In generic settings, when the orthogonal projection onto a lowdimensional model set is used, it has been shown, under a restricted isometry assumption, that the corresponding orthogonal PGD converges with a linear rate, yielding near-optimal convergence (within the class of GPGD methods) in the classical case of sparse recovery. However, for deep projective priors trained with classical mean squared error losses, there is little guarantee that the hypotheses for linear convergence are satisfied. In this paper, we propose a stochastic orthogonal regularization of the training loss for deep projective priors. This regularization is motivated by our theoretical results: a sufficiently good approximation of the orthogonal projection guarantees linear stable recovery with performance close to orthogonal PGD. We show experimentally, using two different deep projective priors (based on autoencoders and on denoising networks), that our stochastic orthogonal regularization yields projections that improve convergence speed and robustness of GPGD in challenging inverse problem settings, in accordance with our theoretical findings.
SINETRA: a Versatile Framework for Evaluating Single Neuron Tracking in Behaving Animals
Nov 14, 2024Accurately tracking neuronal activity in behaving animals presents significant challenges due to complex motions and background noise. The lack of annotated datasets limits the evaluation and improvement of such tracking algorithms. To address this, we developed SINETRA, a versatile simulator that generates synthetic tracking data for particles on a deformable background, closely mimicking live animal recordings. This simulator produces annotated 2D and 3D videos that reflect the intricate movements seen in behaving animals like Hydra Vulgaris. We evaluated four state-of-the-art tracking algorithms highlighting the current limitations of these methods in challenging scenarios and paving the way for improved cell tracking techniques in dynamic biological systems.
Restyling Unsupervised Concept Based Interpretable Networks with Generative Models
Jul 01, 2024



Developing inherently interpretable models for prediction has gained prominence in recent years. A subclass of these models, wherein the interpretable network relies on learning high-level concepts, are valued because of closeness of concept representations to human communication. However, the visualization and understanding of the learnt unsupervised dictionary of concepts encounters major limitations, specially for large-scale images. We propose here a novel method that relies on mapping the concept features to the latent space of a pretrained generative model. The use of a generative model enables high quality visualization, and naturally lays out an intuitive and interactive procedure for better interpretation of the learnt concepts. Furthermore, leveraging pretrained generative models has the additional advantage of making the training of the system more efficient. We quantitatively ascertain the efficacy of our method in terms of accuracy of the interpretable prediction network, fidelity of reconstruction, as well as faithfulness and consistency of learnt concepts. The experiments are conducted on multiple image recognition benchmarks for large-scale images. Project page available at https://jayneelparekh.github.io/VisCoIN_project_page/
A Concept-Based Explainability Framework for Large Multimodal Models
Jun 12, 2024Large multimodal models (LMMs) combine unimodal encoders and large language models (LLMs) to perform multimodal tasks. Despite recent advancements towards the interpretability of these models, understanding internal representations of LMMs remains largely a mystery. In this paper, we present a novel framework for the interpretation of LMMs. We propose a dictionary learning based approach, applied to the representation of tokens. The elements of the learned dictionary correspond to our proposed concepts. We show that these concepts are well semantically grounded in both vision and text. Thus we refer to these as "multi-modal concepts". We qualitatively and quantitatively evaluate the results of the learnt concepts. We show that the extracted multimodal concepts are useful to interpret representations of test samples. Finally, we evaluate the disentanglement between different concepts and the quality of grounding concepts visually and textually. We will publicly release our code.
Diffusion-based image inpainting with internal learning
Jun 06, 2024Diffusion models are now the undisputed state-of-the-art for image generation and image restoration. However, they require large amounts of computational power for training and inference. In this paper, we propose lightweight diffusion models for image inpainting that can be trained on a single image, or a few images. We show that our approach competes with large state-of-the-art models in specific cases. We also show that training a model on a single image is particularly relevant for image acquisition modality that differ from the RGB images of standard learning databases. We show results in three different contexts: texture images, line drawing images, and materials BRDF, for which we achieve state-of-the-art results in terms of realism, with a computational load that is greatly reduced compared to concurrent methods.
A Compact and Semantic Latent Space for Disentangled and Controllable Image Editing
Dec 13, 2023Recent advances in the field of generative models and in particular generative adversarial networks (GANs) have lead to substantial progress for controlled image editing, especially compared with the pre-deep learning era. Despite their powerful ability to apply realistic modifications to an image, these methods often lack properties like disentanglement (the capacity to edit attributes independently). In this paper, we propose an auto-encoder which re-organizes the latent space of StyleGAN, so that each attribute which we wish to edit corresponds to an axis of the new latent space, and furthermore that the latent axes are decorrelated, encouraging disentanglement. We work in a compressed version of the latent space, using Principal Component Analysis, meaning that the parameter complexity of our autoencoder is reduced, leading to short training times ($\sim$ 45 mins). Qualitative and quantitative results demonstrate the editing capabilities of our approach, with greater disentanglement than competing methods, while maintaining fidelity to the original image with respect to identity. Our autoencoder architecture simple and straightforward, facilitating implementation.
Infusion: Internal Diffusion for Video Inpainting
Nov 02, 2023Video inpainting is the task of filling a desired region in a video in a visually convincing manner. It is a very challenging task due to the high dimensionality of the signal and the temporal consistency required for obtaining convincing results. Recently, diffusion models have shown impressive results in modeling complex data distributions, including images and videos. Diffusion models remain nonetheless very expensive to train and perform inference with, which strongly restrict their application to video. We show that in the case of video inpainting, thanks to the highly auto-similar nature of videos, the training of a diffusion model can be restricted to the video to inpaint and still produce very satisfying results. This leads us to adopt an internal learning approch, which also allows for a greatly reduced network size. We call our approach "Infusion": an internal learning algorithm for video inpainting through diffusion. Due to our frugal network, we are able to propose the first video inpainting approach based purely on diffusion. Other methods require supporting elements such as optical flow estimation, which limits their performance in the case of dynamic textures for example. We introduce a new method for efficient training and inference of diffusion models in the context of internal learning. We split the diffusion process into different learning intervals which greatly simplifies the learning steps. We show qualititative and quantitative results, demonstrating that our method reaches state-of-the-art performance, in particular in the case of dynamic backgrounds and textures.
Patch-Based Stochastic Attention for Image Editing
Feb 07, 2022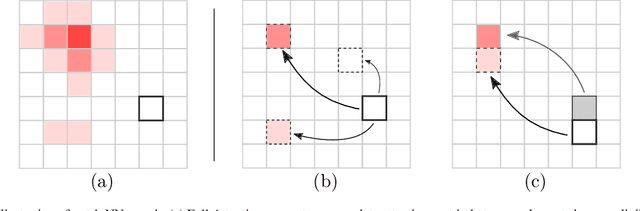



Attention mechanisms have become of crucial importance in deep learning in recent years. These non-local operations, which are similar to traditional patch-based methods in image processing, complement local convolutions. However, computing the full attention matrix is an expensive step with a heavy memory and computational load. These limitations curb network architectures and performances, in particular for the case of high resolution images. We propose an efficient attention layer based on the stochastic algorithm PatchMatch, which is used for determining approximate nearest neighbors. We refer to our proposed layer as a "Patch-based Stochastic Attention Layer" (PSAL). Furthermore, we propose different approaches, based on patch aggregation, to ensure the differentiability of PSAL, thus allowing end-to-end training of any network containing our layer. PSAL has a small memory footprint and can therefore scale to high resolution images. It maintains this footprint without sacrificing spatial precision and globality of the nearest neighbours, which means that it can be easily inserted in any level of a deep architecture, even in shallower levels. We demonstrate the usefulness of PSAL on several image editing tasks, such as image inpainting and image colorization.
Feature-Style Encoder for Style-Based GAN Inversion
Feb 04, 2022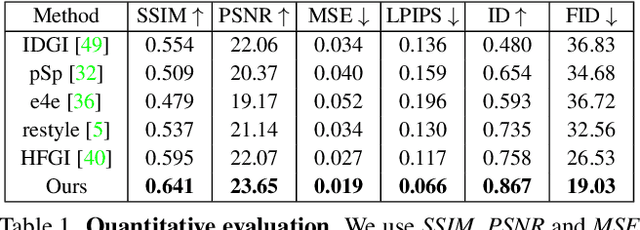
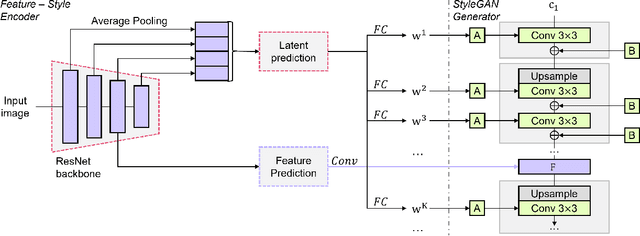
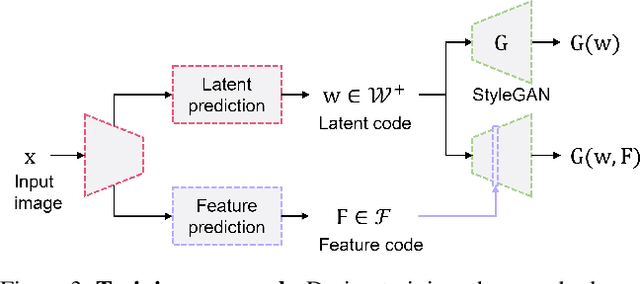
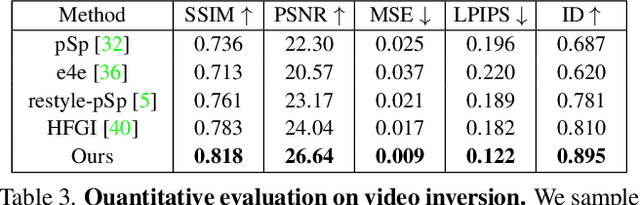
We propose a novel architecture for GAN inversion, which we call Feature-Style encoder. The style encoder is key for the manipulation of the obtained latent codes, while the feature encoder is crucial for optimal image reconstruction. Our model achieves accurate inversion of real images from the latent space of a pre-trained style-based GAN model, obtaining better perceptual quality and lower reconstruction error than existing methods. Thanks to its encoder structure, the model allows fast and accurate image editing. Additionally, we demonstrate that the proposed encoder is especially well-suited for inversion and editing on videos. We conduct extensive experiments for several style-based generators pre-trained on different data domains. Our proposed method yields state-of-the-art results for style-based GAN inversion, significantly outperforming competing approaches. Source codes are available at https://github.com/InterDigitalInc/FeatureStyleEncoder .
A Latent Transformer for Disentangled and Identity-Preserving Face Editing
Jun 22, 2021
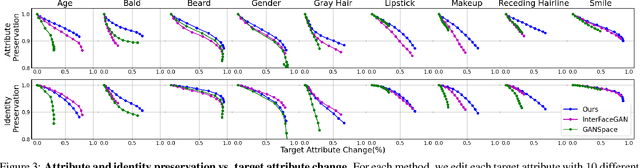


High quality facial image editing is a challenging problem in the movie post-production industry, requiring a high degree of control and identity preservation. Previous works that attempt to tackle this problem may suffer from the entanglement of facial attributes and the loss of the person's identity. Furthermore, many algorithms are limited to a certain task. To tackle these limitations, we propose to edit facial attributes via the latent space of a StyleGAN generator, by training a dedicated latent transformation network and incorporating explicit disentanglement and identity preservation terms in the loss function. We further introduce a pipeline to generalize our face editing to videos. Our model achieves a disentangled, controllable, and identity-preserving facial attribute editing, even in the challenging case of real (i.e., non-synthetic) images and videos. We conduct extensive experiments on image and video datasets and show that our model outperforms other state-of-the-art methods in visual quality and quantitative evaluation.