 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLong-Context Aware Upcycling: A New Frontier for Hybrid LLM Scaling
Apr 27, 2026Hybrid sequence models that combine efficient Transformer components with linear sequence modeling blocks are a promising alternative to pure Transformers, but most are still pretrained from scratch and therefore fail to reuse existing Transformer checkpoints. We study upcycling as a practical path to convert pretrained Transformer LLMs into hybrid architectures while preserving short-context quality and improving long-context capability. We call our solution \emph{HyLo} (HYbrid LOng-context): a long-context upcycling recipe that combines architectural adaptation with efficient Transformer blocks, Multi-Head Latent Attention (MLA), and linear blocks (Mamba2 or Gated DeltaNet), together with staged long-context training and teacher-guided distillation for stable optimization. HyLo extends usable context length by up to $32\times$ through efficient post-training and reduces KV-cache memory by more than $90\%$, enabling up to 2M-token prefill and decoding in our \texttt{vLLM} inference stack, while comparable Llama baselines run out of memory beyond 64K context. Across 1B- and 3B-scale settings (Llama- and Qwen-based variants), HyLo delivers consistently strong short- and long-context performance and significantly outperforms state-of-the-art upcycled hybrid baselines on long-context evaluations such as RULER. Notably, at similar scale, HyLo-Qwen-1.7B trained on only 10B tokens significantly outperforms JetNemotron (trained on 400B tokens) on GSM8K, Lm-Harness common sense reasoning and RULER-64K.
DADAgger: Disagreement-Augmented Dataset Aggregation
Jan 03, 2023



DAgger is an imitation algorithm that aggregates its original datasets by querying the expert on all samples encountered during training. In order to reduce the number of samples queried, we propose a modification to DAgger, known as DADAgger, which only queries the expert for state-action pairs that are out of distribution (OOD). OOD states are identified by measuring the variance of the action predictions of an ensemble of models on each state, which we simulate using dropout. Testing on the Car Racing and Half Cheetah environments achieves comparable performance to DAgger but with reduced expert queries, and better performance than a random sampling baseline. We also show that our algorithm may be used to build efficient, well-balanced training datasets by running with no initial data and only querying the expert to resolve uncertainty.
Deep Neural Networks to Correct Sub-Precision Errors in CFD
Feb 09, 2022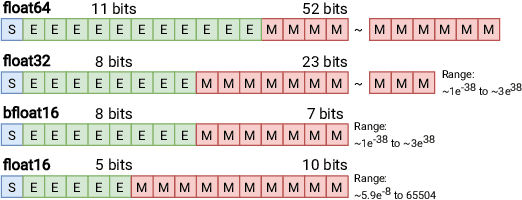

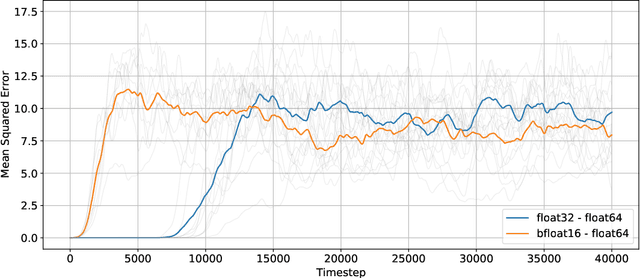

Loss of information in numerical simulations can arise from various sources while solving discretized partial differential equations. In particular, precision-related errors can accumulate in the quantities of interest when the simulations are performed using low-precision 16-bit floating-point arithmetic compared to an equivalent 64-bit simulation. Here, low-precision computation requires much lower resources than high-precision computation. Several machine learning (ML) techniques proposed recently have been successful in correcting the errors arising from spatial discretization. In this work, we extend these techniques to improve Computational Fluid Dynamics (CFD) simulations performed using low numerical precision. We first quantify the precision related errors accumulated in a Kolmogorov forced turbulence test case. Subsequently, we employ a Convolutional Neural Network together with a fully differentiable numerical solver performing 16-bit arithmetic to learn a tightly-coupled ML-CFD hybrid solver. Compared to the 16-bit solver, we demonstrate the efficacy of the ML-CFD hybrid solver towards reducing the error accumulation in the velocity field and improving the kinetic energy spectrum at higher frequencies.