 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVIViT: Variable-Input Vision Transformer Framework for 3D MR Image Segmentation
May 13, 2025Self-supervised pretrain techniques have been widely used to improve the downstream tasks' performance. However, real-world magnetic resonance (MR) studies usually consist of different sets of contrasts due to different acquisition protocols, which poses challenges for the current deep learning methods on large-scale pretrain and different downstream tasks with different input requirements, since these methods typically require a fixed set of input modalities or, contrasts. To address this challenge, we propose variable-input ViT (VIViT), a transformer-based framework designed for self-supervised pretraining and segmentation finetuning for variable contrasts in each study. With this ability, our approach can maximize the data availability in pretrain, and can transfer the learned knowledge from pretrain to downstream tasks despite variations in input requirements. We validate our method on brain infarct and brain tumor segmentation, where our method outperforms current CNN and ViT-based models with a mean Dice score of 0.624 and 0.883 respectively. These results highlight the efficacy of our design for better adaptability and performance on tasks with real-world heterogeneous MR data.
SegResMamba: An Efficient Architecture for 3D Medical Image Segmentation
Mar 10, 2025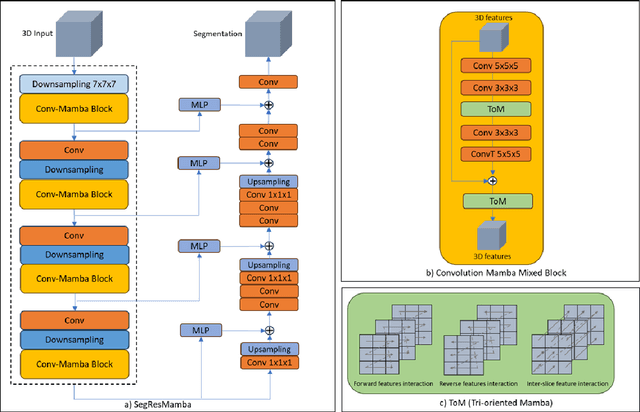



The Transformer architecture has opened a new paradigm in the domain of deep learning with its ability to model long-range dependencies and capture global context and has outpaced the traditional Convolution Neural Networks (CNNs) in many aspects. However, applying Transformer models to 3D medical image datasets presents significant challenges due to their high training time, and memory requirements, which not only hinder scalability but also contribute to elevated CO$_2$ footprint. This has led to an exploration of alternative models that can maintain or even improve performance while being more efficient and environmentally sustainable. Recent advancements in Structured State Space Models (SSMs) effectively address some of the inherent limitations of Transformers, particularly their high memory and computational demands. Inspired by these advancements, we propose an efficient 3D segmentation model for medical imaging called SegResMamba, designed to reduce computation complexity, memory usage, training time, and environmental impact while maintaining high performance. Our model uses less than half the memory during training compared to other state-of-the-art (SOTA) architectures, achieving comparable performance with significantly reduced resource demands.