 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExpertGen: Scalable Sim-to-Real Expert Policy Learning from Imperfect Behavior Priors
Mar 16, 2026Learning generalizable and robust behavior cloning policies requires large volumes of high-quality robotics data. While human demonstrations (e.g., through teleoperation) serve as the standard source for expert behaviors, acquiring such data at scale in the real world is prohibitively expensive. This paper introduces ExpertGen, a framework that automates expert policy learning in simulation to enable scalable sim-to-real transfer. ExpertGen first initializes a behavior prior using a diffusion policy trained on imperfect demonstrations, which may be synthesized by large language models or provided by humans. Reinforcement learning is then used to steer this prior toward high task success by optimizing the diffusion model's initial noise while keep original policy frozen. By keeping the pretrained diffusion policy frozen, ExpertGen regularizes exploration to remain within safe, human-like behavior manifolds, while also enabling effective learning with only sparse rewards. Empirical evaluations on challenging manipulation benchmarks demonstrate that ExpertGen reliably produces high-quality expert policies with no reward engineering. On industrial assembly tasks, ExpertGen achieves a 90.5% overall success rate, while on long-horizon manipulation tasks it attains 85% overall success, outperforming all baseline methods. The resulting policies exhibit dexterous control and remain robust across diverse initial configurations and failure states. To validate sim-to-real transfer, the learned state-based expert policies are further distilled into visuomotor policies via DAgger and successfully deployed on real robotic hardware.
Recognizing Film Entities in Podcasts
Sep 24, 2018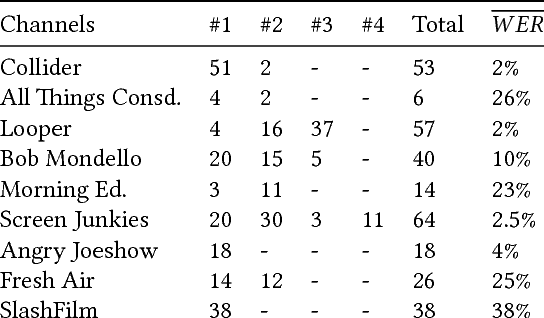
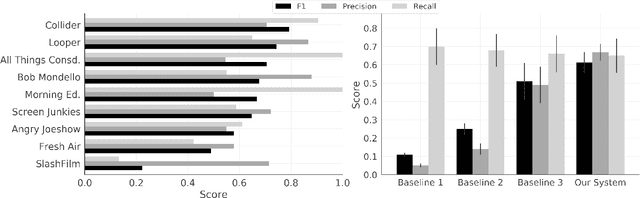

In this paper, we propose a Named Entity Recognition (NER) system to identify film titles in podcast audio. Taking inspiration from NER systems for noisy text in social media, we implement a two-stage approach that is robust to computer transcription errors and does not require significant computational expense to accommodate new film titles/releases. Evaluating on a diverse set of podcasts, we demonstrate more than a 20% increase in F1 score across three baseline approaches when combining fuzzy-matching with a linear model aware of film-specific metadata.