 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGold Standard Online Debates Summaries and First Experiments Towards Automatic Summarization of Online Debate Data
Aug 15, 2017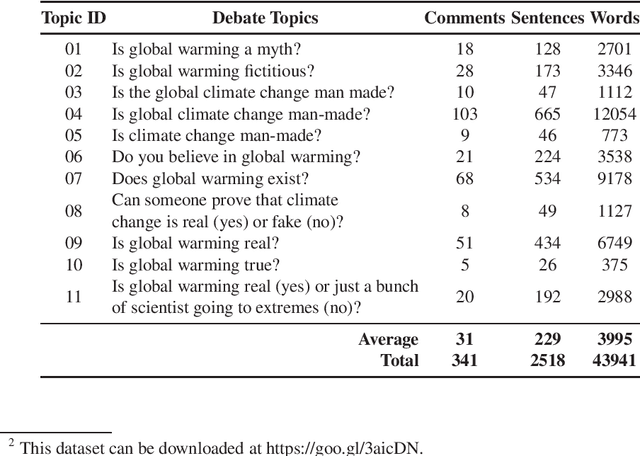
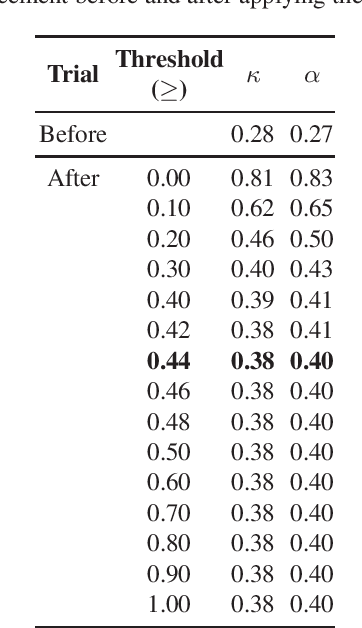

Usage of online textual media is steadily increasing. Daily, more and more news stories, blog posts and scientific articles are added to the online volumes. These are all freely accessible and have been employed extensively in multiple research areas, e.g. automatic text summarization, information retrieval, information extraction, etc. Meanwhile, online debate forums have recently become popular, but have remained largely unexplored. For this reason, there are no sufficient resources of annotated debate data available for conducting research in this genre. In this paper, we collected and annotated debate data for an automatic summarization task. Similar to extractive gold standard summary generation our data contains sentences worthy to include into a summary. Five human annotators performed this task. Inter-annotator agreement, based on semantic similarity, is 36% for Cohen's kappa and 48% for Krippendorff's alpha. Moreover, we also implement an extractive summarization system for online debates and discuss prominent features for the task of summarizing online debate data automatically.
Automatic Summarization of Online Debates
Aug 15, 2017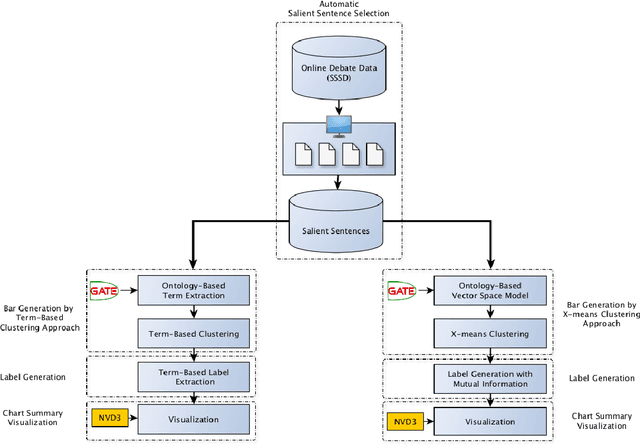

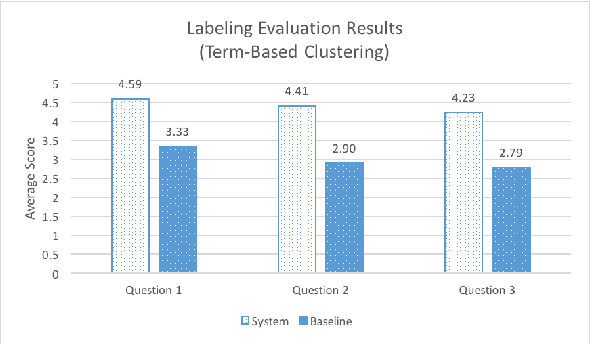

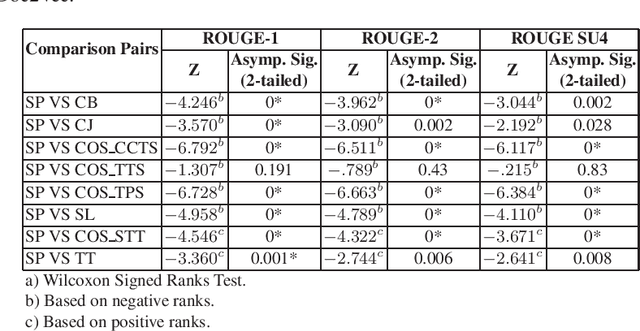
Debate summarization is one of the novel and challenging research areas in automatic text summarization which has been largely unexplored. In this paper, we develop a debate summarization pipeline to summarize key topics which are discussed or argued in the two opposing sides of online debates. We view that the generation of debate summaries can be achieved by clustering, cluster labeling, and visualization. In our work, we investigate two different clustering approaches for the generation of the summaries. In the first approach, we generate the summaries by applying purely term-based clustering and cluster labeling. The second approach makes use of X-means for clustering and Mutual Information for labeling the clusters. Both approaches are driven by ontologies. We visualize the results using bar charts. We think that our results are a smooth entry for users aiming to receive the first impression about what is discussed within a debate topic containing waste number of argumentations.