 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSkill-Aligned Annotation for Reliable Evaluation in Text-to-Image Generation
May 13, 2026Text-to-image (T2I) generation has advanced rapidly, making reliable evaluation critical as performance differences between models narrow. Existing evaluation practices typically apply uniform annotation mechanisms, such as Likert-scale or binary question answering (BQA), across heterogeneous evaluation skills, despite fundamental differences in their nature. In this work, we revisit T2I evaluation through the lens of skill-aligned annotation, where annotation strategies reflect the underlying characteristics of each evaluation skill. We systematically compare skill-aligned annotation against uniform baselines and show that it produces more consistent evaluation signals, with higher inter-annotator agreement and improved stability across models. Finally, we present an automated pipeline that instantiates the proposed evaluation protocol, enabling scalable and fine-grained evaluation with spatially grounded feedback. Our work highlights that improving the foundations of image evaluation can increase reliability and efficiency without simply scaling annotation effort. We hope this motivates further research on refining evaluation protocols as a central component of reliable model assessment.
Hunayn: Elevating Translation Beyond the Literal
Oct 25, 2023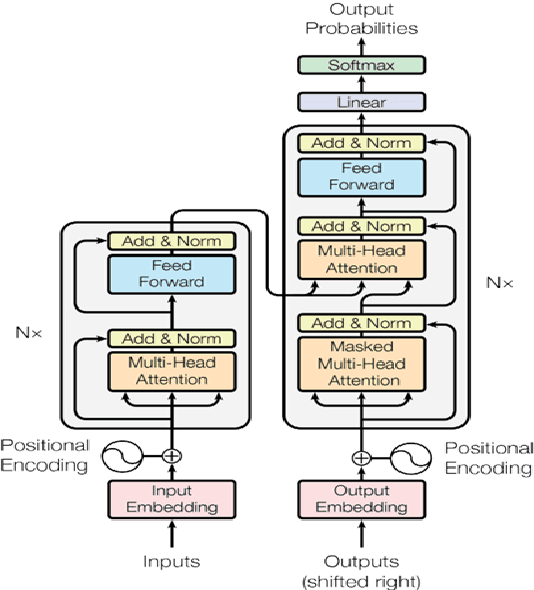
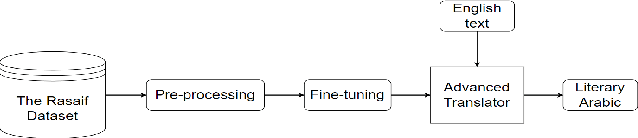

This project introduces an advanced English-to-Arabic translator surpassing conventional tools. Leveraging the Helsinki transformer (MarianMT), our approach involves fine-tuning on a self-scraped, purely literary Arabic dataset. Evaluations against Google Translate show consistent outperformance in qualitative assessments. Notably, it excels in cultural sensitivity and context accuracy. This research underscores the Helsinki transformer's superiority for English-to-Arabic translation using a Fusha dataset.