 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInvariant-Stratified Propagation for Expressive Graph Neural Networks
Mar 02, 2026Graph Neural Networks (GNNs) face fundamental limitations in expressivity and capturing structural heterogeneity. Standard message-passing architectures are constrained by the 1-dimensional Weisfeiler-Leman (1-WL) test, unable to distinguish graphs beyond degree sequences, and aggregate information uniformly from neighbors, failing to capture how nodes occupy different structural positions within higher-order patterns. While methods exist to achieve higher expressivity, they incur prohibitive computational costs and lack unified frameworks for flexibly encoding diverse structural properties. To address these limitations, we introduce Invariant-Stratified Propagation (ISP), a framework comprising both a novel WL variant (ISP-WL) and its efficient neural network implementation (ISPGNN). ISP stratifies nodes according to graph invariants, processing them in hierarchical strata that reveal structural distinctions invisible to 1-WL. Through hierarchical structural heterogeneity encoding, ISP quantifies differences in nodes' structural positions within higher-order patterns, distinguishing interactions where participants occupy different roles from those with uniform participation. We provide formal theoretical analysis establishing enhanced expressivity beyond 1-WL, convergence guarantees, and inherent resistance to oversmoothing. Extensive experiments across graph classification, node classification, and influence estimation demonstrate consistent improvements over standard architectures and state-of-the-art expressive baselines.
Efficient Edge Rewiring Strategies for Enhancing PageRank Fairness
Jan 23, 2026We study the notion of unfairness in social networks, where a group such as females in a male-dominated industry are disadvantaged in access to important information, e.g. job posts, due to their less favorable positions in the network. We investigate a well-established network-based formulation of fairness called PageRank fairness, which refers to a fair allocation of the PageRank weights among distinct groups. Our goal is to enhance the PageRank fairness by modifying the underlying network structure. More precisely, we study the problem of maximizing PageRank fairness with respect to a disadvantaged group, when we are permitted to rewire a fixed number of edges in the network. Building on a greedy approach, we leverage techniques from fast sampling of rooted spanning forests to devise an effective linear-time algorithm for this problem. To evaluate the accuracy and performance of our proposed algorithm, we conduct a large set of experiments on various real-world network data. Our experiments demonstrate that the proposed algorithm significantly outperforms the existing ones. Our algorithm is capable of generating accurate solutions for networks of million nodes in just a few minutes.
Promoting Fairness in Information Access within Social Networks
Dec 08, 2025



The advent of online social networks has facilitated fast and wide spread of information. However, some users, especially members of minority groups, may be less likely to receive information spreading on the network, due to their disadvantaged network position. We study the optimization problem of adding new connections to a network to enhance fairness in information access among different demographic groups. We provide a concrete formulation of this problem where information access is measured in terms of resistance distance, {offering a new perspective that emphasizes global network structure and multi-path connectivity.} The problem is shown to be NP-hard. We propose a simple greedy algorithm which turns out to output accurate solutions, but its run time is cubic, which makes it undesirable for large networks. As our main technical contribution, we reduce its time complexity to linear, leveraging several novel approximation techniques. In addition to our theoretical findings, we also conduct an extensive set of experiments using both real-world and synthetic datasets. We demonstrate that our linear-time algorithm can produce accurate solutions for networks with millions of nodes.
Adaptive Initial Residual Connections for GNNs with Theoretical Guarantees
Nov 10, 2025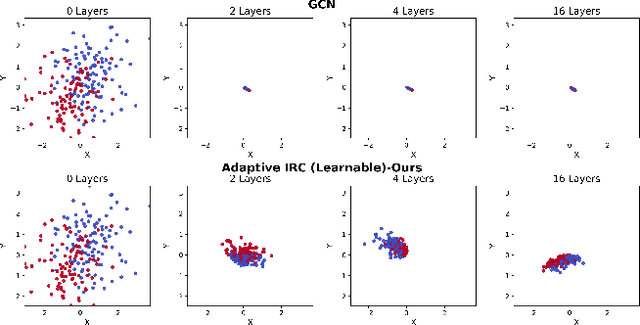
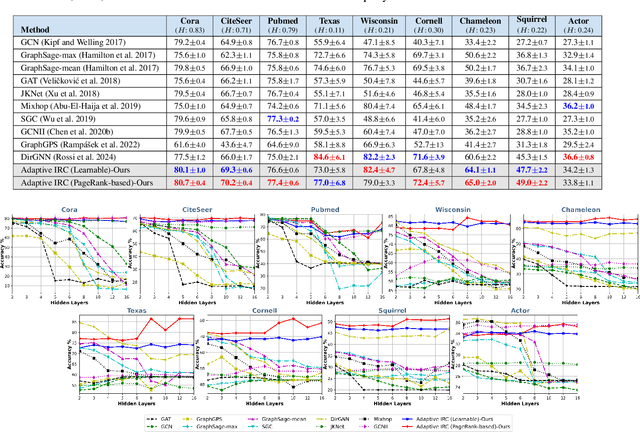


Message passing is the core operation in graph neural networks, where each node updates its embeddings by aggregating information from its neighbors. However, in deep architectures, this process often leads to diminished expressiveness. A popular solution is to use residual connections, where the input from the current (or initial) layer is added to aggregated neighbor information to preserve embeddings across layers. Following a recent line of research, we investigate an adaptive residual scheme in which different nodes have varying residual strengths. We prove that this approach prevents oversmoothing; particularly, we show that the Dirichlet energy of the embeddings remains bounded away from zero. This is the first theoretical guarantee not only for the adaptive setting, but also for static residual connections (where residual strengths are shared across nodes) with activation functions. Furthermore, extensive experiments show that this adaptive approach outperforms standard and state-of-the-art message passing mechanisms, especially on heterophilic graphs. To improve the time complexity of our approach, we introduce a variant in which residual strengths are not learned but instead set heuristically, a choice that performs as well as the learnable version.
Beyond Fixed Depth: Adaptive Graph Neural Networks for Node Classification Under Varying Homophily
Nov 10, 2025Graph Neural Networks (GNNs) have achieved significant success in addressing node classification tasks. However, the effectiveness of traditional GNNs degrades on heterophilic graphs, where connected nodes often belong to different labels or properties. While recent work has introduced mechanisms to improve GNN performance under heterophily, certain key limitations still exist. Most existing models apply a fixed aggregation depth across all nodes, overlooking the fact that nodes may require different propagation depths based on their local homophily levels and neighborhood structures. Moreover, many methods are tailored to either homophilic or heterophilic settings, lacking the flexibility to generalize across both regimes. To address these challenges, we develop a theoretical framework that links local structural and label characteristics to information propagation dynamics at the node level. Our analysis shows that optimal aggregation depth varies across nodes and is critical for preserving class-discriminative information. Guided by this insight, we propose a novel adaptive-depth GNN architecture that dynamically selects node-specific aggregation depths using theoretically grounded metrics. Our method seamlessly adapts to both homophilic and heterophilic patterns within a unified model. Extensive experiments demonstrate that our approach consistently enhances the performance of standard GNN backbones across diverse benchmarks.
Efficient Algorithms for Computing Random Walk Centrality
Oct 23, 2025Random walk centrality is a fundamental metric in graph mining for quantifying node importance and influence, defined as the weighted average of hitting times to a node from all other nodes. Despite its ability to capture rich graph structural information and its wide range of applications, computing this measure for large networks remains impractical due to the computational demands of existing methods. In this paper, we present a novel formulation of random walk centrality, underpinning two scalable algorithms: one leveraging approximate Cholesky factorization and sparse inverse estimation, while the other sampling rooted spanning trees. Both algorithms operate in near-linear time and provide strong approximation guarantees. Extensive experiments on large real-world networks, including one with over 10 million nodes, demonstrate the efficiency and approximation quality of the proposed algorithms.
Graph-based Fake Account Detection: A Survey
Jul 09, 2025In recent years, there has been a growing effort to develop effective and efficient algorithms for fake account detection in online social networks. This survey comprehensively reviews existing methods, with a focus on graph-based techniques that utilise topological features of social graphs (in addition to account information, such as their shared contents and profile data) to distinguish between fake and real accounts. We provide several categorisations of these methods (for example, based on techniques used, input data, and detection time), discuss their strengths and limitations, and explain how these methods connect in the broader context. We also investigate the available datasets, including both real-world data and synthesised models. We conclude the paper by proposing several potential avenues for future research.
Depth-Adaptive Graph Neural Networks via Learnable Bakry-'Emery Curvature
Mar 03, 2025Graph Neural Networks (GNNs) have demonstrated strong representation learning capabilities for graph-based tasks. Recent advances on GNNs leverage geometric properties, such as curvature, to enhance its representation capabilities by modeling complex connectivity patterns and information flow within graphs. However, most existing approaches focus solely on discrete graph topology, overlooking diffusion dynamics and task-specific dependencies essential for effective learning. To address this, we propose integrating Bakry-\'Emery curvature, which captures both structural and task-driven aspects of information propagation. We develop an efficient, learnable approximation strategy, making curvature computation scalable for large graphs. Furthermore, we introduce an adaptive depth mechanism that dynamically adjusts message-passing layers per vertex based on its curvature, ensuring efficient propagation. Our theoretical analysis establishes a link between curvature and feature distinctiveness, showing that high-curvature vertices require fewer layers, while low-curvature ones benefit from deeper propagation. Extensive experiments on benchmark datasets validate the effectiveness of our approach, showing consistent performance improvements across diverse graph learning tasks.
DeepSN: A Sheaf Neural Framework for Influence Maximization
Dec 16, 2024Influence maximization is key topic in data mining, with broad applications in social network analysis and viral marketing. In recent years, researchers have increasingly turned to machine learning techniques to address this problem. They have developed methods to learn the underlying diffusion processes in a data-driven manner, which enhances the generalizability of the solution, and have designed optimization objectives to identify the optimal seed set. Nonetheless, two fundamental gaps remain unsolved: (1) Graph Neural Networks (GNNs) are increasingly used to learn diffusion models, but in their traditional form, they often fail to capture the complex dynamics of influence diffusion, (2) Designing optimization objectives is challenging due to combinatorial explosion when solving this problem. To address these challenges, we propose a novel framework, DeepSN. Our framework employs sheaf neural diffusion to learn diverse influence patterns in a data-driven, end-to-end manner, providing enhanced separability in capturing diffusion characteristics. We also propose an optimization technique that accounts for overlapping influence between vertices, which helps to reduce the search space and identify the optimal seed set effectively and efficiently. Finally, we conduct extensive experiments on both synthetic and real-world datasets to demonstrate the effectiveness of our framework.
A Generalisation of Voter Model: Influential Nodes and Convergence Properties
Nov 07, 2024



Consider an undirected graph G, representing a social network, where each node is blue or red, corresponding to positive or negative opinion on a topic. In the voter model, in discrete time rounds, each node picks a neighbour uniformly at random and adopts its colour. Despite its significant popularity, this model does not capture some fundamental real-world characteristics such as the difference in the strengths of individuals connections, individuals with neutral opinion on a topic, and individuals who are reluctant to update their opinion. To address these issues, we introduce and study a generalisation of the voter model. Motivating by campaigning strategies, we study the problem of selecting a set of seeds blue nodes to maximise the expected number of blue nodes after some rounds. We prove that the problem is NP- hard and provide a polynomial time approximation algorithm with the best possible approximation guarantee. Our experiments on real-world and synthetic graph data demonstrate that the proposed algorithm outperforms other algorithms. We also investigate the convergence properties of the model. We prove that the process could take an exponential number of rounds to converge. However, if we limit ourselves to strongly connected graphs, the convergence time is polynomial and the period (the number of states in convergence) divides the length of all cycles in the graph.