 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFoundations of Coupled Nonlinear Dimensionality Reduction
Nov 25, 2015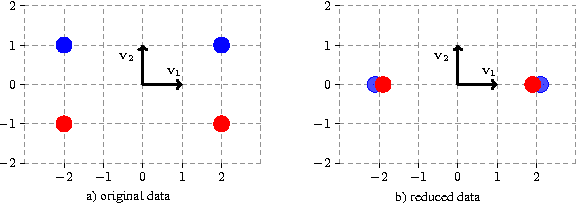
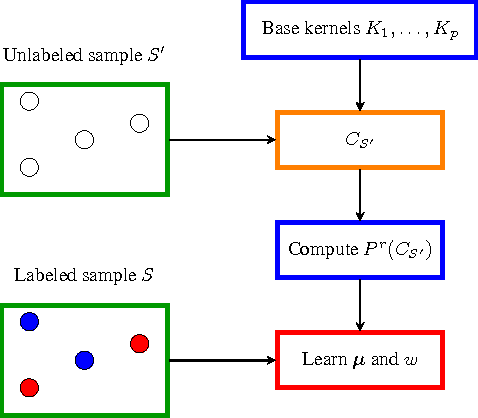
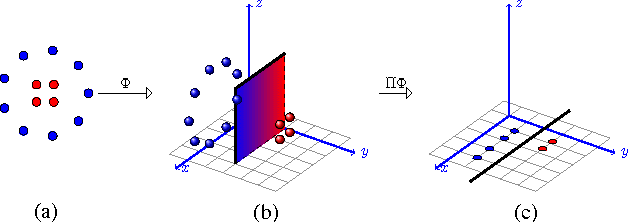
In this paper we introduce and analyze the learning scenario of \emph{coupled nonlinear dimensionality reduction}, which combines two major steps of machine learning pipeline: projection onto a manifold and subsequent supervised learning. First, we present new generalization bounds for this scenario and, second, we introduce an algorithm that follows from these bounds. The generalization error bound is based on a careful analysis of the empirical Rademacher complexity of the relevant hypothesis set. In particular, we show an upper bound on the Rademacher complexity that is in $\widetilde O(\sqrt{\Lambda_{(r)}/m})$, where $m$ is the sample size and $\Lambda_{(r)}$ the upper bound on the Ky-Fan $r$-norm of the associated kernel matrix. We give both upper and lower bound guarantees in terms of that Ky-Fan $r$-norm, which strongly justifies the definition of our hypothesis set. To the best of our knowledge, these are the first learning guarantees for the problem of coupled dimensionality reduction. Our analysis and learning guarantees further apply to several special cases, such as that of using a fixed kernel with supervised dimensionality reduction or that of unsupervised learning of a kernel for dimensionality reduction followed by a supervised learning algorithm. Based on theoretical analysis, we suggest a structural risk minimization algorithm consisting of the coupled fitting of a low dimensional manifold and a separation function on that manifold.
Matrix Coherence and the Nystrom Method
Aug 09, 2014
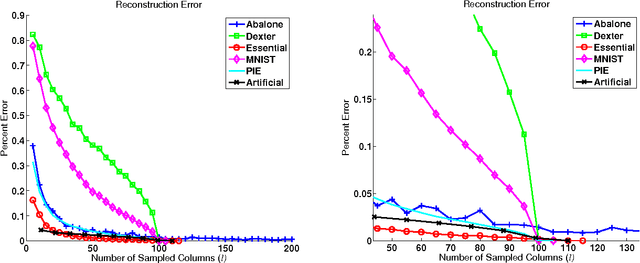
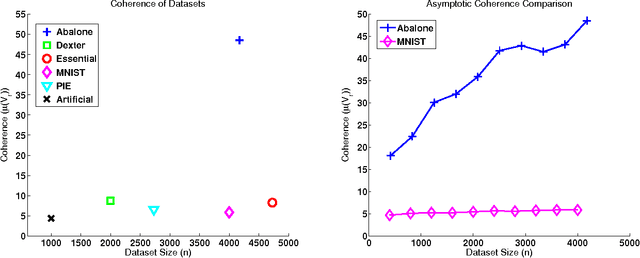
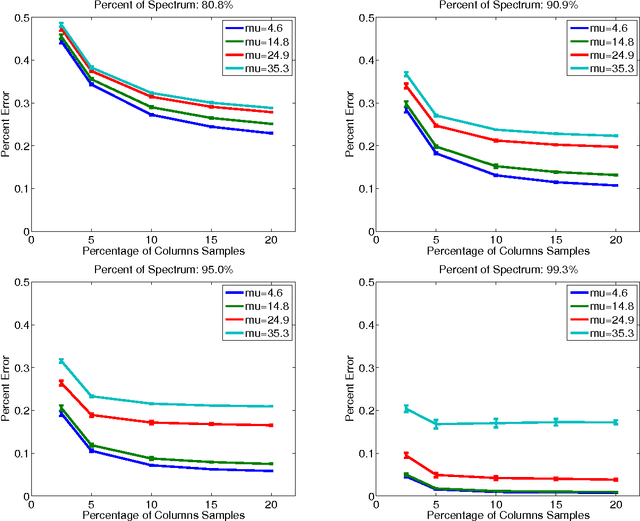
The Nystrom method is an efficient technique used to speed up large-scale learning applications by generating low-rank approximations. Crucial to the performance of this technique is the assumption that a matrix can be well approximated by working exclusively with a subset of its columns. In this work we relate this assumption to the concept of matrix coherence, connecting coherence to the performance of the Nystrom method. Making use of related work in the compressed sensing and the matrix completion literature, we derive novel coherence-based bounds for the Nystrom method in the low-rank setting. We then present empirical results that corroborate these theoretical bounds. Finally, we present more general empirical results for the full-rank setting that convincingly demonstrate the ability of matrix coherence to measure the degree to which information can be extracted from a subset of columns.
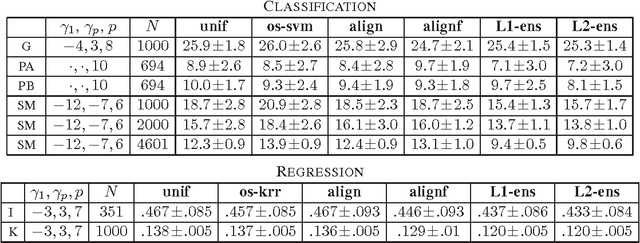
Algorithms for Learning Kernels Based on Centered Alignment
Apr 08, 2014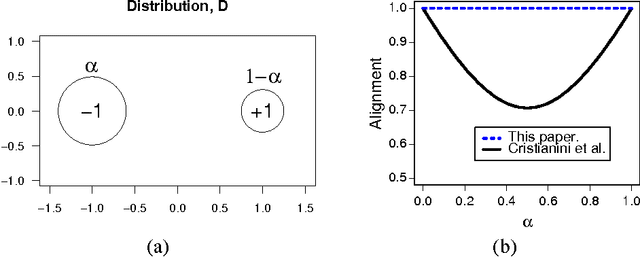

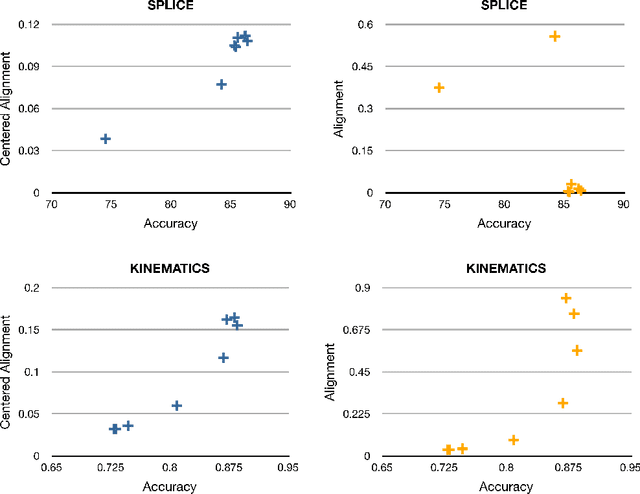
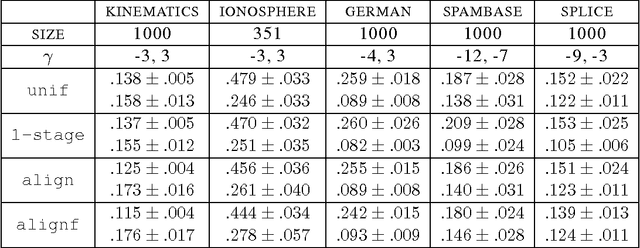
This paper presents new and effective algorithms for learning kernels. In particular, as shown by our empirical results, these algorithms consistently outperform the so-called uniform combination solution that has proven to be difficult to improve upon in the past, as well as other algorithms for learning kernels based on convex combinations of base kernels in both classification and regression. Our algorithms are based on the notion of centered alignment which is used as a similarity measure between kernels or kernel matrices. We present a number of novel algorithmic, theoretical, and empirical results for learning kernels based on our notion of centered alignment. In particular, we describe efficient algorithms for learning a maximum alignment kernel by showing that the problem can be reduced to a simple QP and discuss a one-stage algorithm for learning both a kernel and a hypothesis based on that kernel using an alignment-based regularization. Our theoretical results include a novel concentration bound for centered alignment between kernel matrices, the proof of the existence of effective predictors for kernels with high alignment, both for classification and for regression, and the proof of stability-based generalization bounds for a broad family of algorithms for learning kernels based on centered alignment. We also report the results of experiments with our centered alignment-based algorithms in both classification and regression.
Learning Prices for Repeated Auctions with Strategic Buyers
Nov 26, 2013Inspired by real-time ad exchanges for online display advertising, we consider the problem of inferring a buyer's value distribution for a good when the buyer is repeatedly interacting with a seller through a posted-price mechanism. We model the buyer as a strategic agent, whose goal is to maximize her long-term surplus, and we are interested in mechanisms that maximize the seller's long-term revenue. We define the natural notion of strategic regret --- the lost revenue as measured against a truthful (non-strategic) buyer. We present seller algorithms that are no-(strategic)-regret when the buyer discounts her future surplus --- i.e. the buyer prefers showing advertisements to users sooner rather than later. We also give a lower bound on strategic regret that increases as the buyer's discounting weakens and shows, in particular, that any seller algorithm will suffer linear strategic regret if there is no discounting.
Perceptron Mistake Bounds
Jul 23, 2013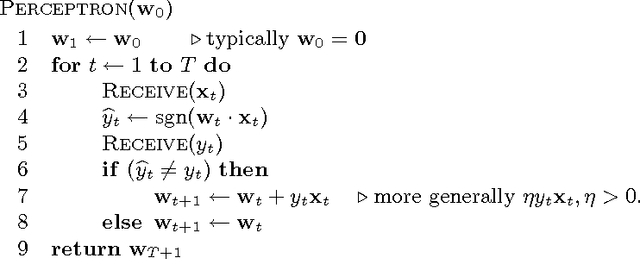
We present a brief survey of existing mistake bounds and introduce novel bounds for the Perceptron or the kernel Perceptron algorithm. Our novel bounds generalize beyond standard margin-loss type bounds, allow for any convex and Lipschitz loss function, and admit a very simple proof.
Multiple Source Adaptation and the Renyi Divergence
May 09, 2012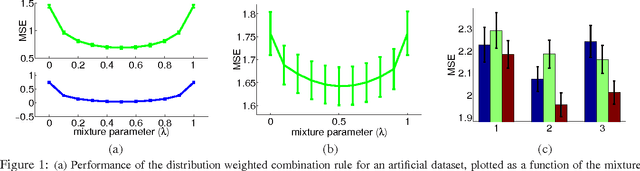
This paper presents a novel theoretical study of the general problem of multiple source adaptation using the notion of Renyi divergence. Our results build on our previous work [12], but significantly broaden the scope of that work in several directions. We extend previous multiple source loss guarantees based on distribution weighted combinations to arbitrary target distributions P, not necessarily mixtures of the source distributions, analyze both known and unknown target distribution cases, and prove a lower bound. We further extend our bounds to deal with the case where the learner receives an approximate distribution for each source instead of the exact one, and show that similar loss guarantees can be achieved depending on the divergence between the approximate and true distributions. We also analyze the case where the labeling functions of the source domains are somewhat different. Finally, we report the results of experiments with both an artificial data set and a sentiment analysis task, showing the performance benefits of the distribution weighted combinations and the quality of our bounds based on the Renyi divergence.
L2 Regularization for Learning Kernels
May 09, 2012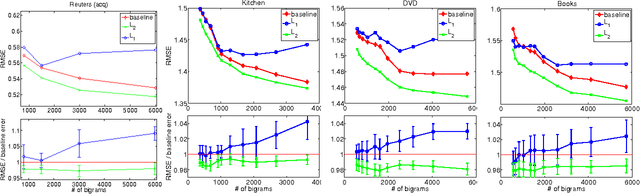
The choice of the kernel is critical to the success of many learning algorithms but it is typically left to the user. Instead, the training data can be used to learn the kernel by selecting it out of a given family, such as that of non-negative linear combinations of p base kernels, constrained by a trace or L1 regularization. This paper studies the problem of learning kernels with the same family of kernels but with an L2 regularization instead, and for regression problems. We analyze the problem of learning kernels with ridge regression. We derive the form of the solution of the optimization problem and give an efficient iterative algorithm for computing that solution. We present a novel theoretical analysis of the problem based on stability and give learning bounds for orthogonal kernels that contain only an additive term O(pp/m) when compared to the standard kernel ridge regression stability bound. We also report the results of experiments indicating that L1 regularization can lead to modest improvements for a small number of kernels, but to performance degradations in larger-scale cases. In contrast, L2 regularization never degrades performance and in fact achieves significant improvements with a large number of kernels.
Ensembles of Kernel Predictors
Feb 14, 2012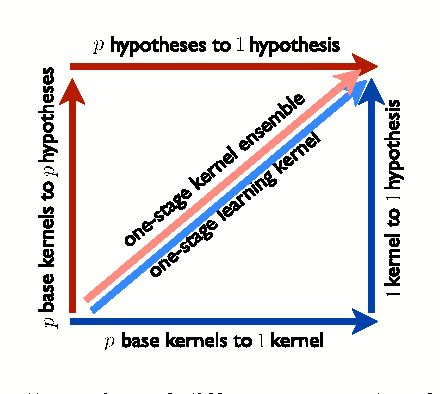
This paper examines the problem of learning with a finite and possibly large set of p base kernels. It presents a theoretical and empirical analysis of an approach addressing this problem based on ensembles of kernel predictors. This includes novel theoretical guarantees based on the Rademacher complexity of the corresponding hypothesis sets, the introduction and analysis of a learning algorithm based on these hypothesis sets, and a series of experiments using ensembles of kernel predictors with several data sets. Both convex combinations of kernel-based hypotheses and more general Lq-regularized nonnegative combinations are analyzed. These theoretical, algorithmic, and empirical results are compared with those achieved by using learning kernel techniques, which can be viewed as another approach for solving the same problem.
Online and Batch Learning Algorithms for Data with Missing Features
Jun 16, 2011



We introduce new online and batch algorithms that are robust to data with missing features, a situation that arises in many practical applications. In the online setup, we allow for the comparison hypothesis to change as a function of the subset of features that is observed on any given round, extending the standard setting where the comparison hypothesis is fixed throughout. In the batch setup, we present a convex relation of a non-convex problem to jointly estimate an imputation function, used to fill in the values of missing features, along with the classification hypothesis. We prove regret bounds in the online setting and Rademacher complexity bounds for the batch i.i.d. setting. The algorithms are tested on several UCI datasets, showing superior performance over baselines.
New Generalization Bounds for Learning Kernels
Dec 17, 2009This paper presents several novel generalization bounds for the problem of learning kernels based on the analysis of the Rademacher complexity of the corresponding hypothesis sets. Our bound for learning kernels with a convex combination of p base kernels has only a log(p) dependency on the number of kernels, p, which is considerably more favorable than the previous best bound given for the same problem. We also give a novel bound for learning with a linear combination of p base kernels with an L_2 regularization whose dependency on p is only in p^{1/4}.