 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeContrastive View Design Strategies to Enhance Robustness to Domain Shifts in Downstream Object Detection
Dec 09, 2022Contrastive learning has emerged as a competitive pretraining method for object detection. Despite this progress, there has been minimal investigation into the robustness of contrastively pretrained detectors when faced with domain shifts. To address this gap, we conduct an empirical study of contrastive learning and out-of-domain object detection, studying how contrastive view design affects robustness. In particular, we perform a case study of the detection-focused pretext task Instance Localization (InsLoc) and propose strategies to augment views and enhance robustness in appearance-shifted and context-shifted scenarios. Amongst these strategies, we propose changes to cropping such as altering the percentage used, adding IoU constraints, and integrating saliency based object priors. We also explore the addition of shortcut-reducing augmentations such as Poisson blending, texture flattening, and elastic deformation. We benchmark these strategies on abstract, weather, and context domain shifts and illustrate robust ways to combine them, in both pretraining on single-object and multi-object image datasets. Overall, our results and insights show how to ensure robustness through the choice of views in contrastive learning.
Comparison of Lexical Alignment with a Teachable Robot in Human-Robot and Human-Human-Robot Interactions
Sep 23, 2022
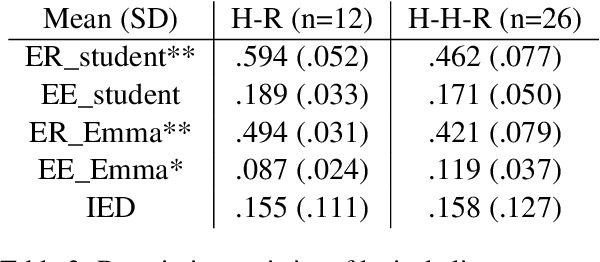

Speakers build rapport in the process of aligning conversational behaviors with each other. Rapport engendered with a teachable agent while instructing domain material has been shown to promote learning. Past work on lexical alignment in the field of education suffers from limitations in both the measures used to quantify alignment and the types of interactions in which alignment with agents has been studied. In this paper, we apply alignment measures based on a data-driven notion of shared expressions (possibly composed of multiple words) and compare alignment in one-on-one human-robot (H-R) interactions with the H-R portions of collaborative human-human-robot (H-H-R) interactions. We find that students in the H-R setting align with a teachable robot more than in the H-H-R setting and that the relationship between lexical alignment and rapport is more complex than what is predicted by previous theoretical and empirical work.
Symbolic image detection using scene and knowledge graphs
Jun 10, 2022
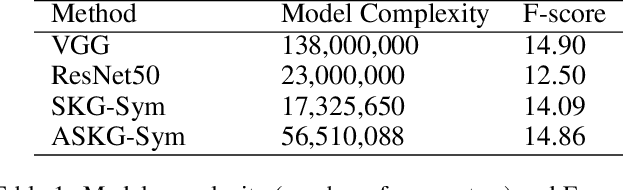
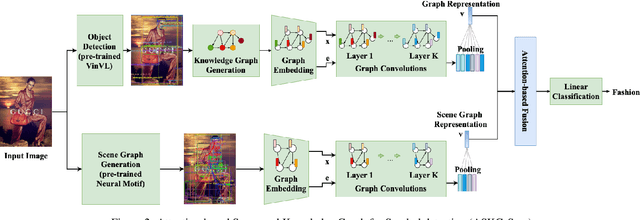

Sometimes the meaning conveyed by images goes beyond the list of objects they contain; instead, images may express a powerful message to affect the viewers' minds. Inferring this message requires reasoning about the relationships between the objects, and general common-sense knowledge about the components. In this paper, we use a scene graph, a graph representation of an image, to capture visual components. In addition, we generate a knowledge graph using facts extracted from ConceptNet to reason about objects and attributes. To detect the symbols, we propose a neural network framework named SKG-Sym. The framework first generates the representations of the scene graph of the image and its knowledge graph using Graph Convolution Network. The framework then fuses the representations and uses an MLP to classify them. We extend the network further to use an attention mechanism which learn the importance of the graph representations. We evaluate our methods on a dataset of advertisements, and compare it with baseline symbolism classification methods (ResNet and VGG). Results show that our methods outperform ResNet in terms of F-score and the attention-based mechanism is competitive with VGG while it has much lower model complexity.
Weakly-Supervised Action Detection Guided by Audio Narration
May 12, 2022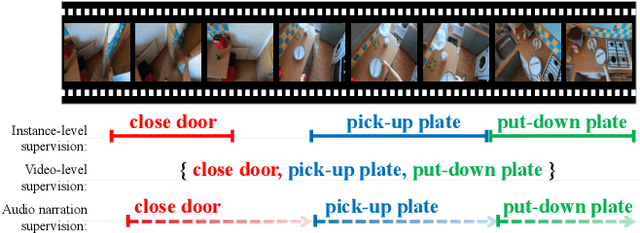
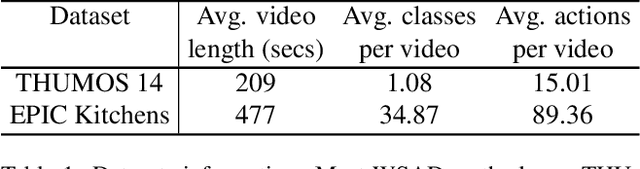
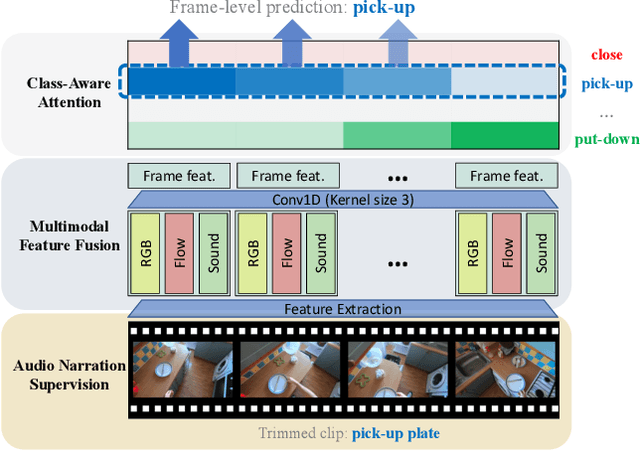

Videos are more well-organized curated data sources for visual concept learning than images. Unlike the 2-dimensional images which only involve the spatial information, the additional temporal dimension bridges and synchronizes multiple modalities. However, in most video detection benchmarks, these additional modalities are not fully utilized. For example, EPIC Kitchens is the largest dataset in first-person (egocentric) vision, yet it still relies on crowdsourced information to refine the action boundaries to provide instance-level action annotations. We explored how to eliminate the expensive annotations in video detection data which provide refined boundaries. We propose a model to learn from the narration supervision and utilize multimodal features, including RGB, motion flow, and ambient sound. Our model learns to attend to the frames related to the narration label while suppressing the irrelevant frames from being used. Our experiments show that noisy audio narration suffices to learn a good action detection model, thus reducing annotation expenses.
Visual Persuasion in COVID-19 Social Media Content: A Multi-Modal Characterization
Dec 05, 2021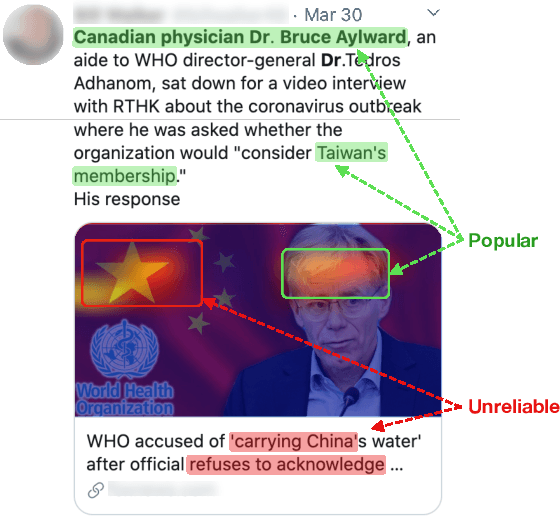
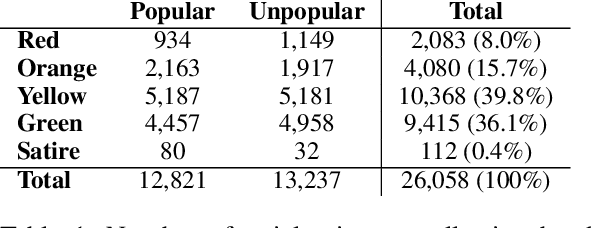

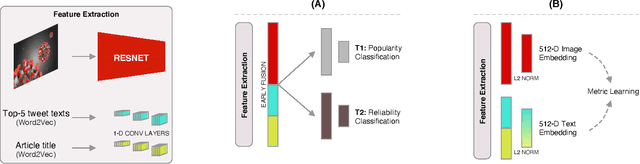
Social media content routinely incorporates multi-modal design to covey information and shape meanings, and sway interpretations toward desirable implications, but the choices and outcomes of using both texts and visual images have not been sufficiently studied. This work proposes a computational approach to analyze the outcome of persuasive information in multi-modal content, focusing on two aspects, popularity and reliability, in COVID-19-related news articles shared on Twitter. The two aspects are intertwined in the spread of misinformation: for example, an unreliable article that aims to misinform has to attain some popularity. This work has several contributions. First, we propose a multi-modal (image and text) approach to effectively identify popularity and reliability of information sources simultaneously. Second, we identify textual and visual elements that are predictive to information popularity and reliability. Third, by modeling cross-modal relations and similarity, we are able to uncover how unreliable articles construct multi-modal meaning in a distorted, biased fashion. Our work demonstrates how to use multi-modal analysis for understanding influential content and has implications to social media literacy and engagement.
Exploring Corruption Robustness: Inductive Biases in Vision Transformers and MLP-Mixers
Jul 03, 2021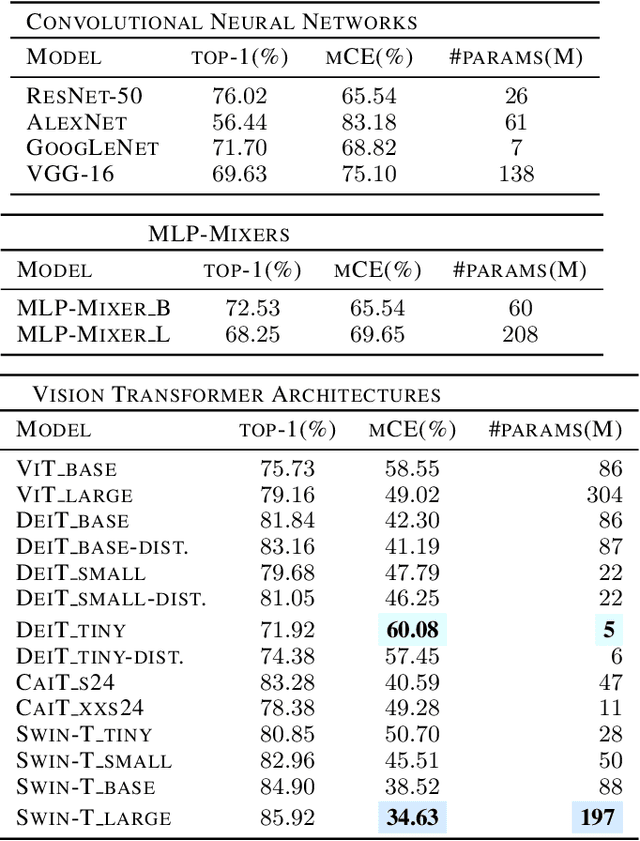
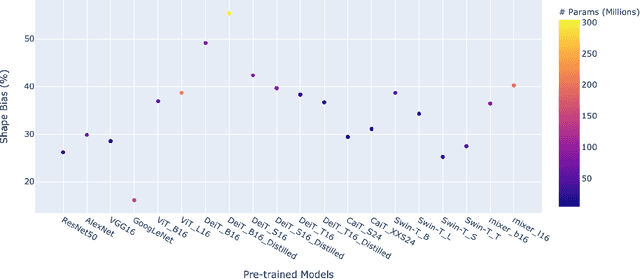
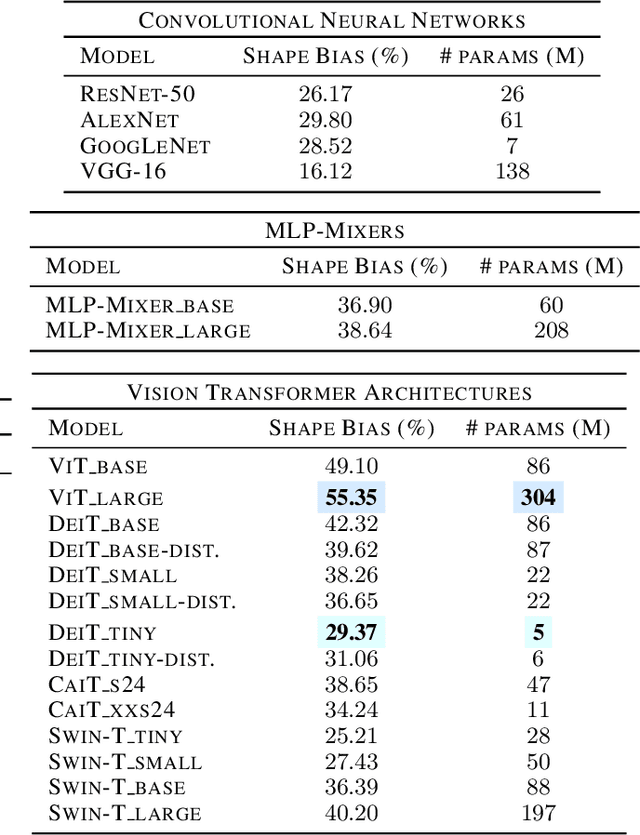
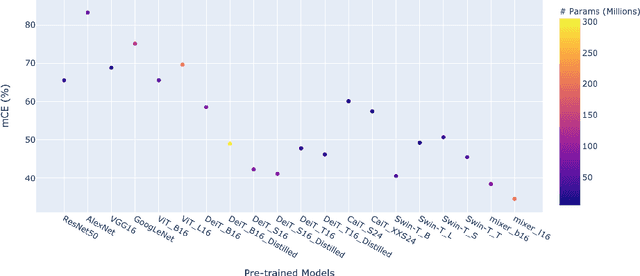
Recently, vision transformers and MLP-based models have been developed in order to address some of the prevalent weaknesses in convolutional neural networks. Due to the novelty of transformers being used in this domain along with the self-attention mechanism, it remains unclear to what degree these architectures are robust to corruptions. Despite some works proposing that data augmentation remains essential for a model to be robust against corruptions, we propose to explore the impact that the architecture has on corruption robustness. We find that vision transformer architectures are inherently more robust to corruptions than the ResNet-50 and MLP-Mixers. We also find that vision transformers with 5 times fewer parameters than a ResNet-50 have more shape bias. Our code is available to reproduce.
Linguistic Structures as Weak Supervision for Visual Scene Graph Generation
May 28, 2021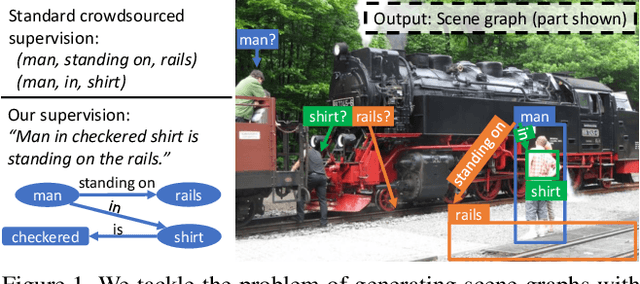

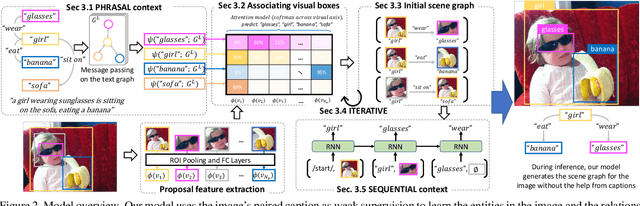
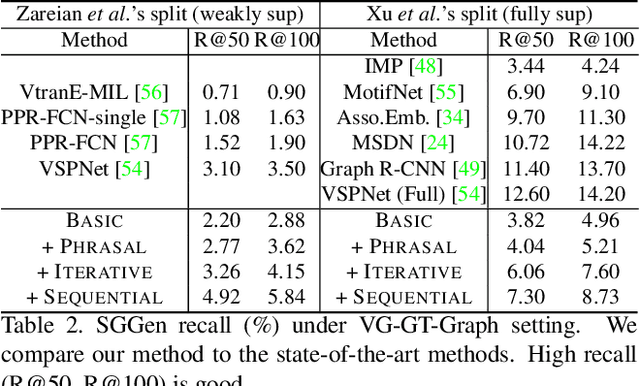
Prior work in scene graph generation requires categorical supervision at the level of triplets - subjects and objects, and predicates that relate them, either with or without bounding box information. However, scene graph generation is a holistic task: thus holistic, contextual supervision should intuitively improve performance. In this work, we explore how linguistic structures in captions can benefit scene graph generation. Our method captures the information provided in captions about relations between individual triplets, and context for subjects and objects (e.g. visual properties are mentioned). Captions are a weaker type of supervision than triplets since the alignment between the exhaustive list of human-annotated subjects and objects in triplets, and the nouns in captions, is weak. However, given the large and diverse sources of multimodal data on the web (e.g. blog posts with images and captions), linguistic supervision is more scalable than crowdsourced triplets. We show extensive experimental comparisons against prior methods which leverage instance- and image-level supervision, and ablate our method to show the impact of leveraging phrasal and sequential context, and techniques to improve localization of subjects and objects.
BasisNet: Two-stage Model Synthesis for Efficient Inference
May 07, 2021
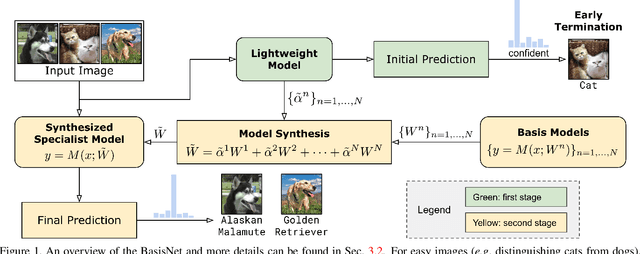

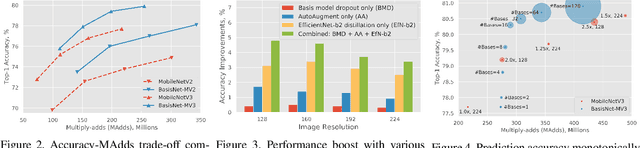
In this work, we present BasisNet which combines recent advancements in efficient neural network architectures, conditional computation, and early termination in a simple new form. Our approach incorporates a lightweight model to preview the input and generate input-dependent combination coefficients, which later controls the synthesis of a more accurate specialist model to make final prediction. The two-stage model synthesis strategy can be applied to any network architectures and both stages are jointly trained. We also show that proper training recipes are critical for increasing generalizability for such high capacity neural networks. On ImageNet classification benchmark, our BasisNet with MobileNets as backbone demonstrated clear advantage on accuracy-efficiency trade-off over several strong baselines. Specifically, BasisNet-MobileNetV3 obtained 80.3% top-1 accuracy with only 290M Multiply-Add operations, halving the computational cost of previous state-of-the-art without sacrificing accuracy. With early termination, the average cost can be further reduced to 198M MAdds while maintaining accuracy of 80.0% on ImageNet.
Domain-robust VQA with diverse datasets and methods but no target labels
Mar 29, 2021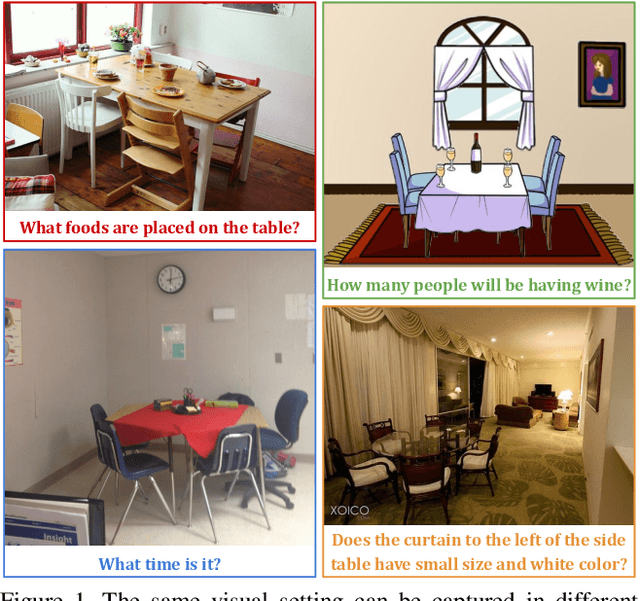

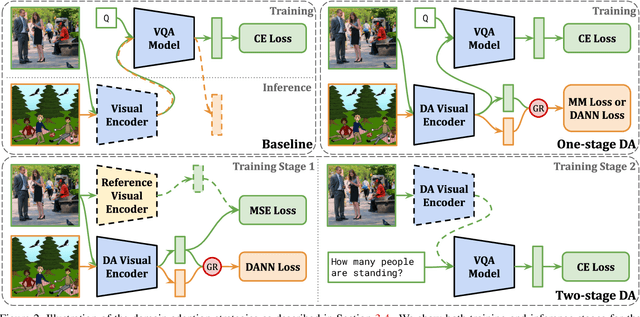
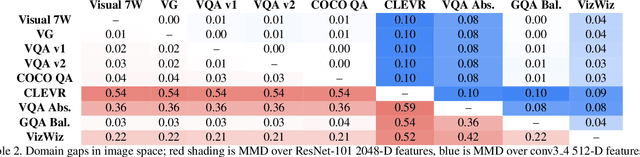
The observation that computer vision methods overfit to dataset specifics has inspired diverse attempts to make object recognition models robust to domain shifts. However, similar work on domain-robust visual question answering methods is very limited. Domain adaptation for VQA differs from adaptation for object recognition due to additional complexity: VQA models handle multimodal inputs, methods contain multiple steps with diverse modules resulting in complex optimization, and answer spaces in different datasets are vastly different. To tackle these challenges, we first quantify domain shifts between popular VQA datasets, in both visual and textual space. To disentangle shifts between datasets arising from different modalities, we also construct synthetic shifts in the image and question domains separately. Second, we test the robustness of different families of VQA methods (classic two-stream, transformer, and neuro-symbolic methods) to these shifts. Third, we test the applicability of existing domain adaptation methods and devise a new one to bridge VQA domain gaps, adjusted to specific VQA models. To emulate the setting of real-world generalization, we focus on unsupervised domain adaptation and the open-ended classification task formulation.
SpotPatch: Parameter-Efficient Transfer Learning for Mobile Object Detection
Jan 04, 2021
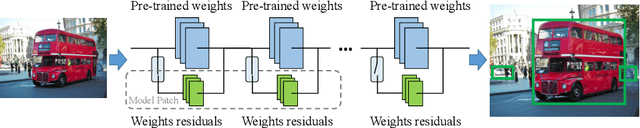
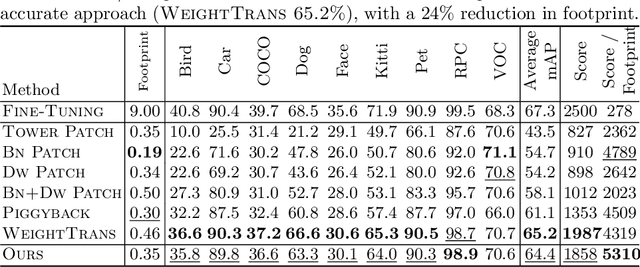
Deep learning based object detectors are commonly deployed on mobile devices to solve a variety of tasks. For maximum accuracy, each detector is usually trained to solve one single specific task, and comes with a completely independent set of parameters. While this guarantees high performance, it is also highly inefficient, as each model has to be separately downloaded and stored. In this paper we address the question: can task-specific detectors be trained and represented as a shared set of weights, plus a very small set of additional weights for each task? The main contributions of this paper are the following: 1) we perform the first systematic study of parameter-efficient transfer learning techniques for object detection problems; 2) we propose a technique to learn a model patch with a size that is dependent on the difficulty of the task to be learned, and validate our approach on 10 different object detection tasks. Our approach achieves similar accuracy as previously proposed approaches, while being significantly more compact.