 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVariational Quanvolutional Neural Networks with enhanced image encoding
Jun 23, 2021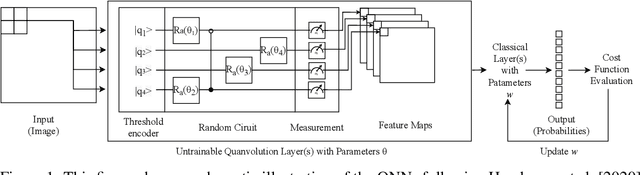

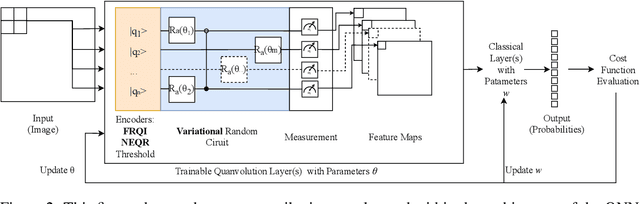
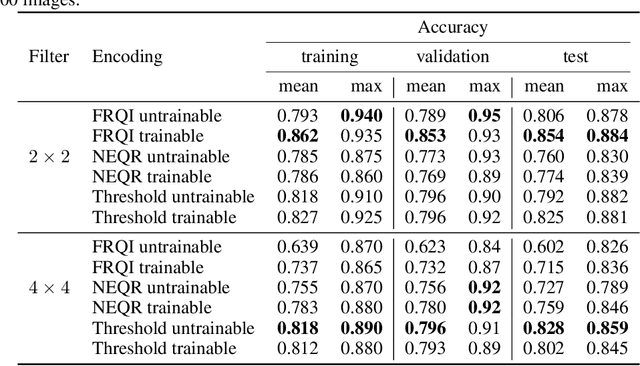
Image classification is an important task in various machine learning applications. In recent years, a number of classification methods based on quantum machine learning and different quantum image encoding techniques have been proposed. In this paper, we study the effect of three different quantum image encoding approaches on the performance of a convolution-inspired hybrid quantum-classical image classification algorithm called quanvolutional neural network (QNN). We furthermore examine the effect of variational - i.e. trainable - quantum circuits on the classification results. Our experiments indicate that some image encodings are better suited for variational circuits. However, our experiments show as well that there is not one best image encoding, but that the choice of the encoding depends on the specific constraints of the application.
TopicsRanksDC: Distance-based Topic Ranking applied on Two-Class Data
May 17, 2021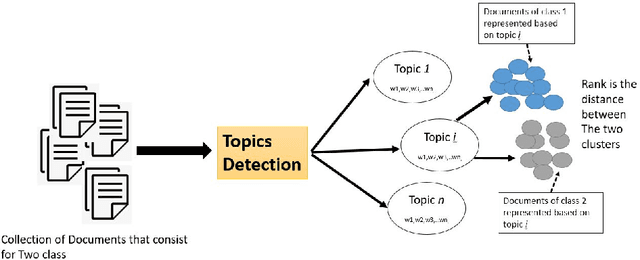
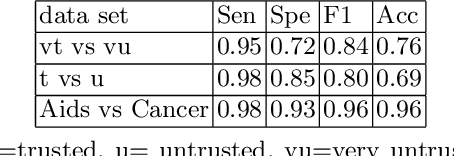
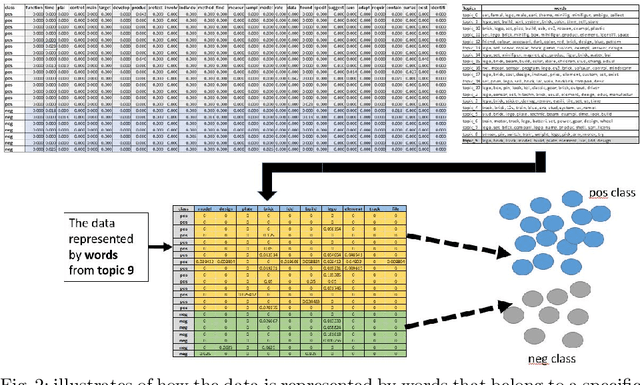
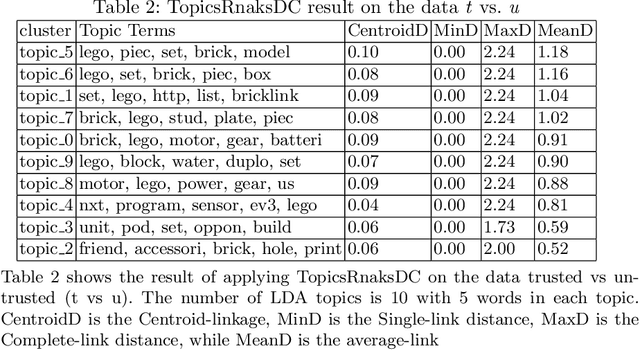
In this paper, we introduce a novel approach named TopicsRanksDC for topics ranking based on the distance between two clusters that are generated by each topic. We assume that our data consists of text documents that are associated with two-classes. Our approach ranks each topic contained in these text documents by its significance for separating the two-classes. Firstly, the algorithm detects topics using Latent Dirichlet Allocation (LDA). The words defining each topic are represented as two clusters, where each one is associated with one of the classes. We compute four distance metrics, Single Linkage, Complete Linkage, Average Linkage and distance between the centroid. We compare the results of LDA topics and random topics. The results show that the rank for LDA topics is much higher than random topics. The results of TopicsRanksDC tool are promising for future work to enable search engines to suggest related topics.
* 10 pages, 5 figures
AI supported Topic Modeling using KNIME-Workflows
Apr 15, 2021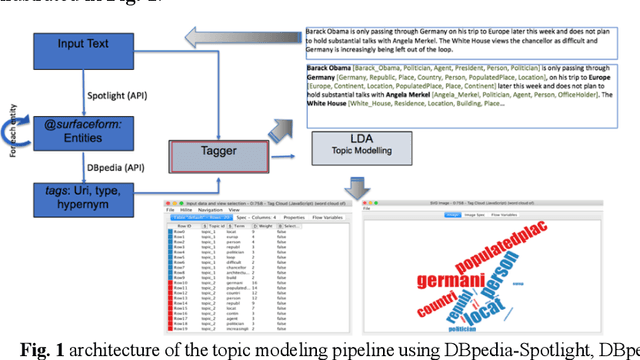
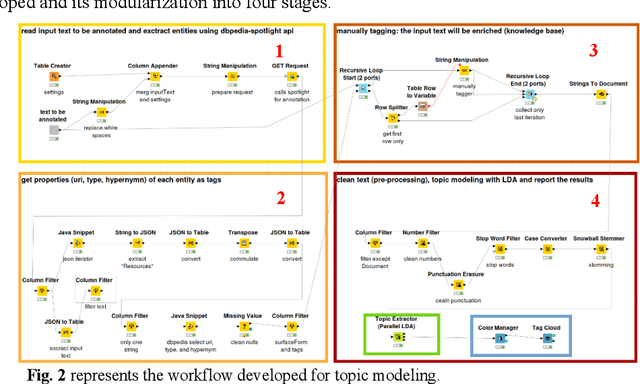

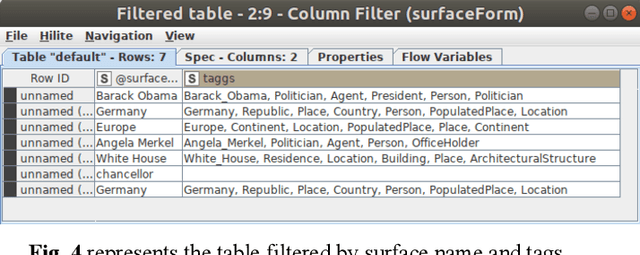
Topic modeling algorithms traditionally model topics as list of weighted terms. These topic models can be used effectively to classify texts or to support text mining tasks such as text summarization or fact extraction. The general procedure relies on statistical analysis of term frequencies. The focus of this work is on the implementation of the knowledge-based topic modelling services in a KNIME workflow. A brief description and evaluation of the DBPedia-based enrichment approach and the comparative evaluation of enriched topic models will be outlined based on our previous work. DBpedia-Spotlight is used to identify entities in the input text and information from DBpedia is used to extend these entities. We provide a workflow developed in KNIME implementing this approach and perform a result comparison of topic modeling supported by knowledge base information to traditional LDA. This topic modeling approach allows semantic interpretation both by algorithms and by humans.
ROC: An Ontology for Country Responses towards COVID-19
Apr 15, 2021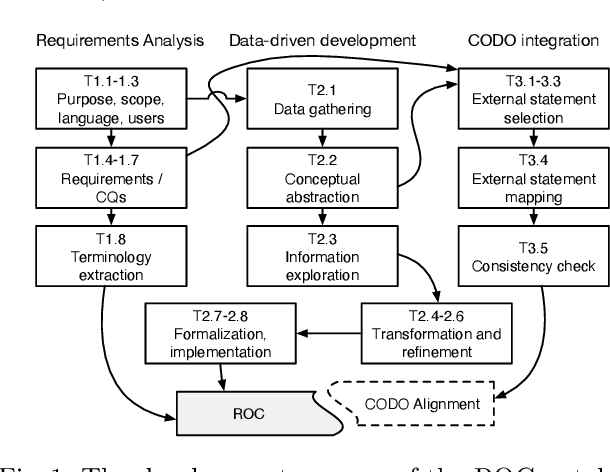
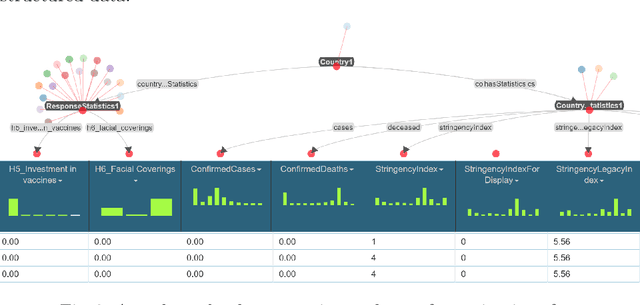

The ROC ontology for country responses to COVID-19 provides a model for collecting, linking and sharing data on the COVID-19 pandemic. It follows semantic standardization (W3C standards RDF, OWL, SPARQL) for the representation of concepts and creation of vocabularies. ROC focuses on country measures and enables the integration of data from heterogeneous data sources. The proposed ontology is intended to facilitate statistical analysis to study and evaluate the effectiveness and side effects of government responses to COVID-19 in different countries. The ontology contains data collected by OxCGRT from publicly available information. This data has been compiled from information provided by ECDC for most countries, as well as from various repositories used to collect data on COVID-19.
* 10 pages, 3 figures
QURATOR: Innovative Technologies for Content and Data Curation
Apr 25, 2020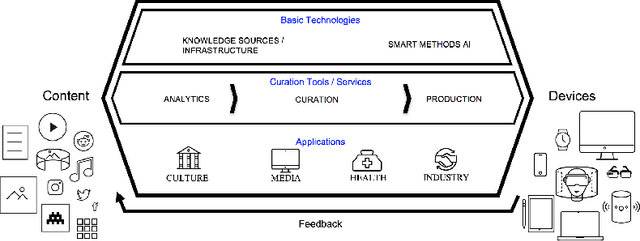
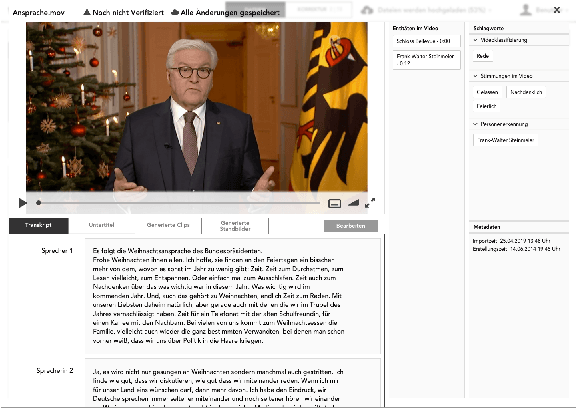
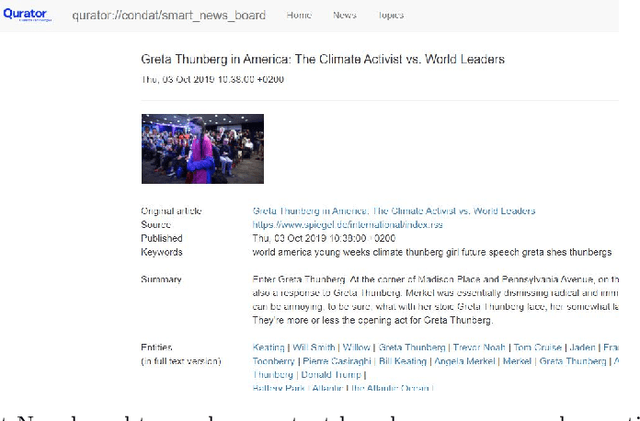
In all domains and sectors, the demand for intelligent systems to support the processing and generation of digital content is rapidly increasing. The availability of vast amounts of content and the pressure to publish new content quickly and in rapid succession requires faster, more efficient and smarter processing and generation methods. With a consortium of ten partners from research and industry and a broad range of expertise in AI, Machine Learning and Language Technologies, the QURATOR project, funded by the German Federal Ministry of Education and Research, develops a sustainable and innovative technology platform that provides services to support knowledge workers in various industries to address the challenges they face when curating digital content. The project's vision and ambition is to establish an ecosystem for content curation technologies that significantly pushes the current state of the art and transforms its region, the metropolitan area Berlin-Brandenburg, into a global centre of excellence for curation technologies.
The Role of Pragmatics in Legal Norm Representation
Jul 08, 2015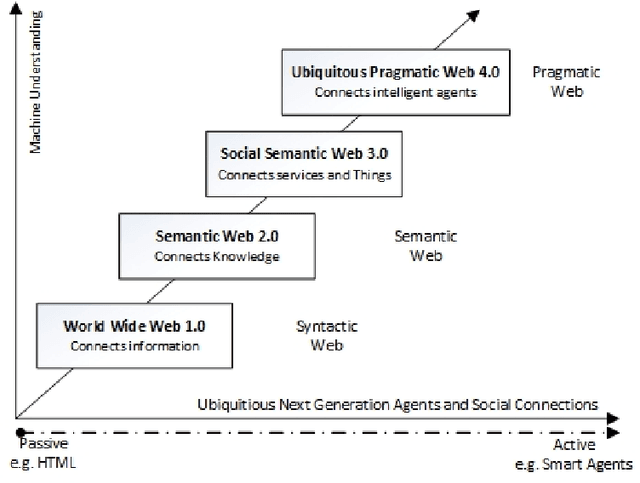
Despite the 'apparent clarity' of a given legal provision, its application may result in an outcome that does not exactly conform to the semantic level of a statute. The vagueness within a legal text is induced intentionally to accommodate all possible scenarios under which such norms should be applied, thus making the role of pragmatics an important aspect also in the representation of a legal norm and reasoning on top of it. The notion of pragmatics considered in this paper does not focus on the aspects associated with judicial decision making. The paper aims to shed light on the aspects of pragmatics in legal linguistics, mainly focusing on the domain of patent law, only from a knowledge representation perspective. The philosophical discussions presented in this paper are grounded based on the legal theories from Grice and Marmor.
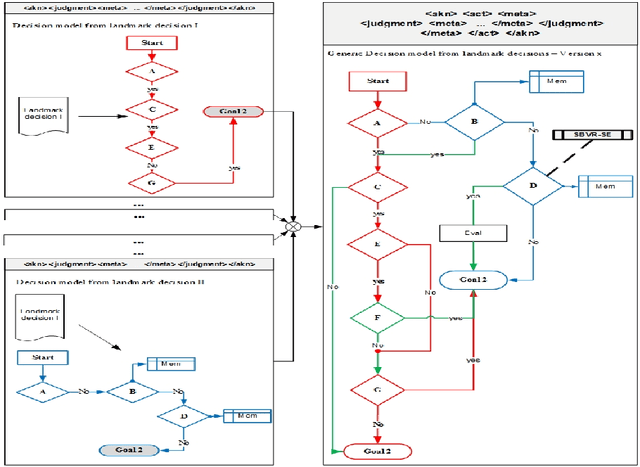
Rule reasoning for legal norm validation of FSTP facts
Dec 05, 2014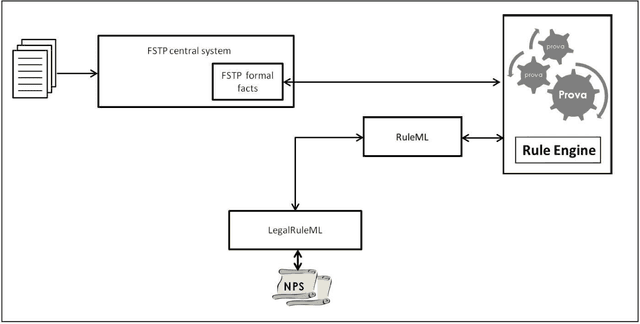
Non-obviousness or inventive step is a general requirement for patentability in most patent law systems. An invention should be at an adequate distance beyond its prior art in order to be patented. This short paper provides an overview on a methodology proposed for legal norm validation of FSTP facts using rule reasoning approach.
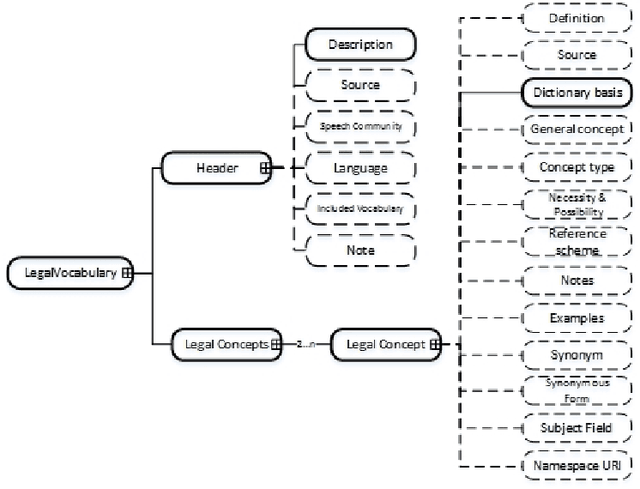
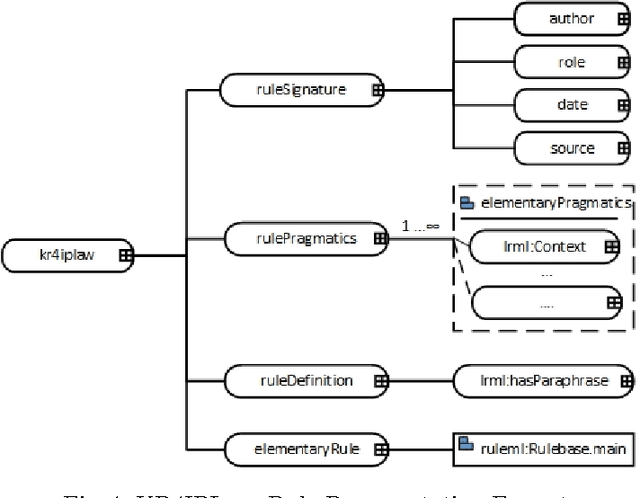
Bridging the gap between Legal Practitioners and Knowledge Engineers using semi-formal KR
May 31, 2014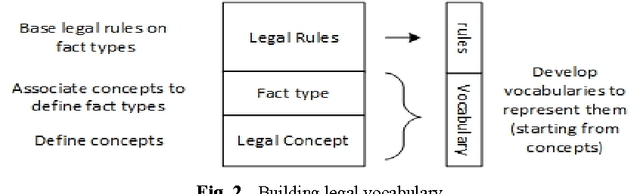
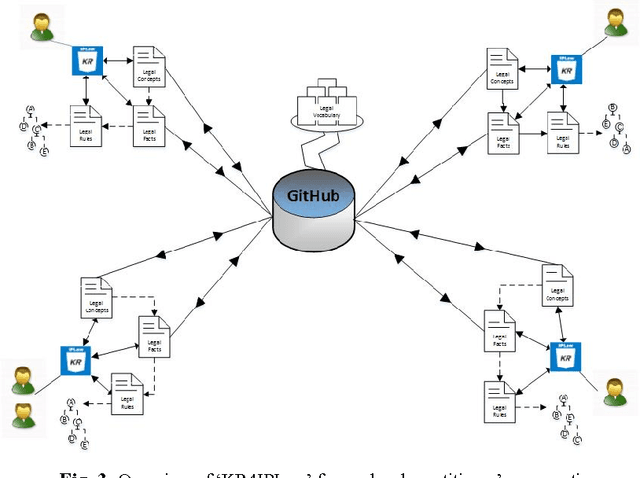
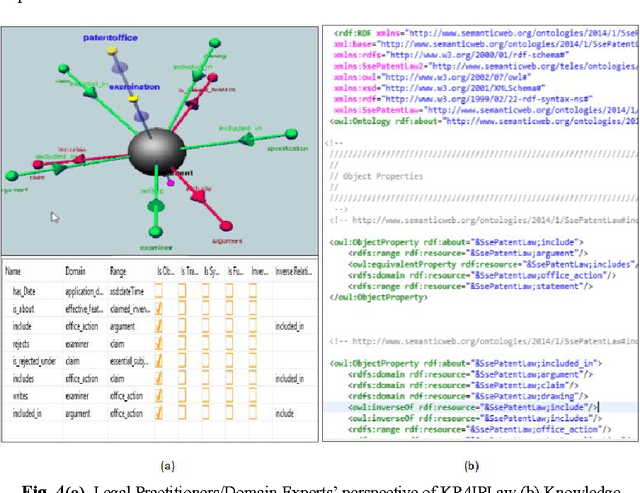
The use of Structured English as a computation independent knowledge representation format for non-technical users in business rules representation has been proposed in OMGs Semantics and Business Vocabulary Representation (SBVR). In the legal domain we face a similar problem. Formal representation languages, such as OASIS LegalRuleML and legal ontologies (LKIF, legal OWL2 ontologies etc.) support the technical knowledge engineer and the automated reasoning. But, they can be hardly used directly by the legal domain experts who do not have a computer science background. In this paper we adapt the SBVR Structured English approach for the legal domain and implement a proof-of-concept, called KR4IPLaw, which enables legal domain experts to represent their knowledge in Structured English in a computational independent and hence, for them, more usable way. The benefit of this approach is that the underlying pre-defined semantics of the Structured English approach makes transformations into formal languages such as OASIS LegalRuleML and OWL2 ontologies possible. We exemplify our approach in the domain of patent law.
An Inter-lingual Reference Approach For Multi-Lingual Ontology Matching
Sep 25, 2013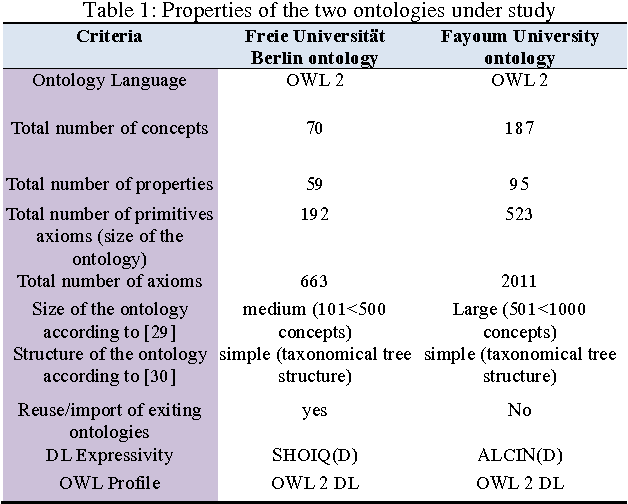

Ontologies are considered as the backbone of the Semantic Web. With the rising success of the Semantic Web, the number of participating communities from different countries is constantly increasing. The growing number of ontologies available in different natural languages leads to an interoperability problem. In this paper, we discuss several approaches for ontology matching; examine similarities and differences, identify weaknesses, and compare the existing automated approaches with the manual approaches for integrating multilingual ontologies. In addition to that, we propose a new architecture for a multilingual ontology matching service. As a case study we used an example of two multilingual enterprise ontologies - the university ontology of Freie Universitaet Berlin and the ontology for Fayoum University in Egypt.
* http://www.ijcsi.org/papers/IJCSI-10-2-1-497-503.pdf
Use of semantic technologies for the development of a dynamic trajectories generator in a Semantic Chemistry eLearning platform
Dec 07, 2010


ChemgaPedia is a multimedia, webbased eLearning service platform that currently contains about 18.000 pages organized in 1.700 chapters covering the complete bachelor studies in chemistry and related topics of chemistry, pharmacy, and life sciences. The eLearning encyclopedia contains some 25.000 media objects and the eLearning platform provides services such as virtual and remote labs for experiments. With up to 350.000 users per month the platform is the most frequently used scientific educational service in the German spoken Internet. In this demo we show the benefit of mapping the static eLearning contents of ChemgaPedia to a Linked Data representation for Semantic Chemistry which allows for generating dynamic eLearning paths tailored to the semantic profiles of the users.