 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAlign-SLM: Textless Spoken Language Models with Reinforcement Learning from AI Feedback
Nov 04, 2024



While textless Spoken Language Models (SLMs) have shown potential in end-to-end speech-to-speech modeling, they still lag behind text-based Large Language Models (LLMs) in terms of semantic coherence and relevance. This work introduces the Align-SLM framework, which leverages preference optimization inspired by Reinforcement Learning with AI Feedback (RLAIF) to enhance the semantic understanding of SLMs. Our approach generates multiple speech continuations from a given prompt and uses semantic metrics to create preference data for Direct Preference Optimization (DPO). We evaluate the framework using ZeroSpeech 2021 benchmarks for lexical and syntactic modeling, the spoken version of the StoryCloze dataset for semantic coherence, and other speech generation metrics, including the GPT4-o score and human evaluation. Experimental results show that our method achieves state-of-the-art performance for SLMs on most benchmarks, highlighting the importance of preference optimization to improve the semantics of SLMs.
Speech Recognition Rescoring with Large Speech-Text Foundation Models
Sep 25, 2024Large language models (LLM) have demonstrated the ability to understand human language by leveraging large amount of text data. Automatic speech recognition (ASR) systems are often limited by available transcribed speech data and benefit from a second pass rescoring using LLM. Recently multi-modal large language models, particularly speech and text foundational models have demonstrated strong spoken language understanding. Speech-Text foundational models leverage large amounts of unlabelled and labelled data both in speech and text modalities to model human language. In this work, we propose novel techniques to use multi-modal LLM for ASR rescoring. We also explore discriminative training to further improve the foundational model rescoring performance. We demonstrate cross-modal knowledge transfer in speech-text LLM can benefit rescoring. Our experiments demonstrate up-to 20% relative improvements over Whisper large ASR and up-to 15% relative improvements over text-only LLM.
Multi-Modal Retrieval For Large Language Model Based Speech Recognition
Jun 13, 2024



Retrieval is a widely adopted approach for improving language models leveraging external information. As the field moves towards multi-modal large language models, it is important to extend the pure text based methods to incorporate other modalities in retrieval as well for applications across the wide spectrum of machine learning tasks and data types. In this work, we propose multi-modal retrieval with two approaches: kNN-LM and cross-attention techniques. We demonstrate the effectiveness of our retrieval approaches empirically by applying them to automatic speech recognition tasks with access to external information. Under this setting, we show that speech-based multi-modal retrieval outperforms text based retrieval, and yields up to 50 % improvement in word error rate over the multi-modal language model baseline. Furthermore, we achieve state-of-the-art recognition results on the Spoken-Squad question answering dataset.
Low-rank Adaptation of Large Language Model Rescoring for Parameter-Efficient Speech Recognition
Sep 26, 2023



We propose a neural language modeling system based on low-rank adaptation (LoRA) for speech recognition output rescoring. Although pretrained language models (LMs) like BERT have shown superior performance in second-pass rescoring, the high computational cost of scaling up the pretraining stage and adapting the pretrained models to specific domains limit their practical use in rescoring. Here we present a method based on low-rank decomposition to train a rescoring BERT model and adapt it to new domains using only a fraction (0.08%) of the pretrained parameters. These inserted matrices are optimized through a discriminative training objective along with a correlation-based regularization loss. The proposed low-rank adaptation Rescore-BERT (LoRB) architecture is evaluated on LibriSpeech and internal datasets with decreased training times by factors between 5.4 and 3.6.
Personalization for BERT-based Discriminative Speech Recognition Rescoring
Jul 13, 2023



Recognition of personalized content remains a challenge in end-to-end speech recognition. We explore three novel approaches that use personalized content in a neural rescoring step to improve recognition: gazetteers, prompting, and a cross-attention based encoder-decoder model. We use internal de-identified en-US data from interactions with a virtual voice assistant supplemented with personalized named entities to compare these approaches. On a test set with personalized named entities, we show that each of these approaches improves word error rate by over 10%, against a neural rescoring baseline. We also show that on this test set, natural language prompts can improve word error rate by 7% without any training and with a marginal loss in generalization. Overall, gazetteers were found to perform the best with a 10% improvement in word error rate (WER), while also improving WER on a general test set by 1%.
On-the-fly Text Retrieval for End-to-End ASR Adaptation
Mar 20, 2023



End-to-end speech recognition models are improved by incorporating external text sources, typically by fusion with an external language model. Such language models have to be retrained whenever the corpus of interest changes. Furthermore, since they store the entire corpus in their parameters, rare words can be challenging to recall. In this work, we propose augmenting a transducer-based ASR model with a retrieval language model, which directly retrieves from an external text corpus plausible completions for a partial ASR hypothesis. These completions are then integrated into subsequent predictions by an adapter, which is trained once, so that the corpus of interest can be switched without incurring the computational overhead of retraining. Our experiments show that the proposed model significantly improves the performance of a transducer baseline on a pair of question-answering datasets. Further, it outperforms shallow fusion on recognition of named entities by about 7 relative; when the two are combined, the relative improvement increases to 13%.
Personalization Strategies for End-to-End Speech Recognition Systems
Feb 15, 2021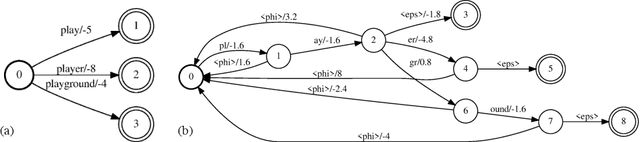
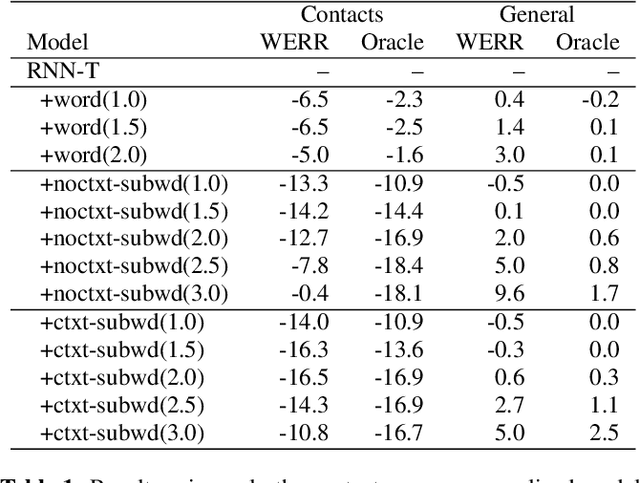
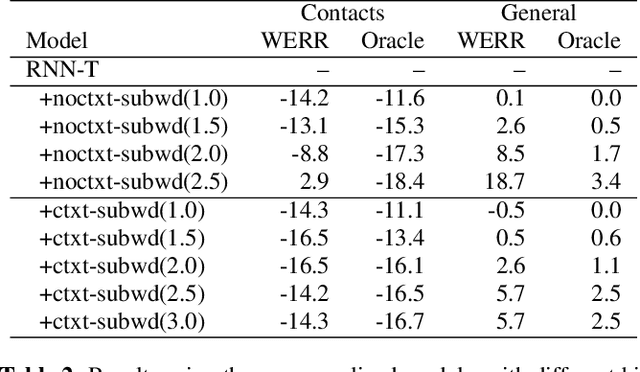
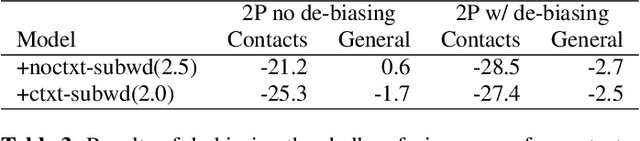
The recognition of personalized content, such as contact names, remains a challenging problem for end-to-end speech recognition systems. In this work, we demonstrate how first and second-pass rescoring strategies can be leveraged together to improve the recognition of such words. Following previous work, we use a shallow fusion approach to bias towards recognition of personalized content in the first-pass decoding. We show that such an approach can improve personalized content recognition by up to 16% with minimum degradation on the general use case. We describe a fast and scalable algorithm that enables our biasing models to remain at the word-level, while applying the biasing at the subword level. This has the advantage of not requiring the biasing models to be dependent on any subword symbol table. We also describe a novel second-pass de-biasing approach: used in conjunction with a first-pass shallow fusion that optimizes on oracle WER, we can achieve an additional 14% improvement on personalized content recognition, and even improve accuracy for the general use case by up to 2.5%.
Domain-aware Neural Language Models for Speech Recognition
Jan 05, 2021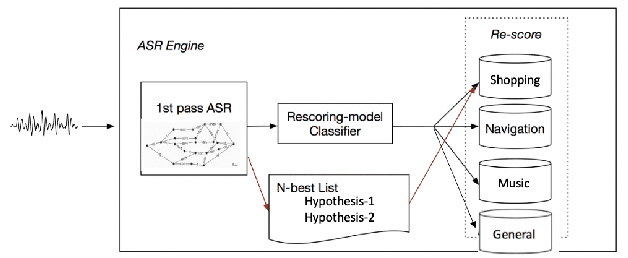
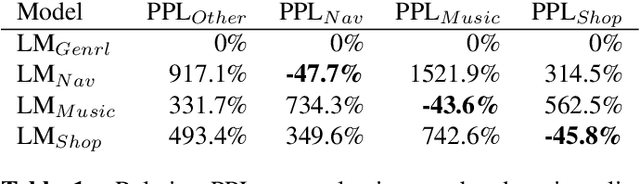

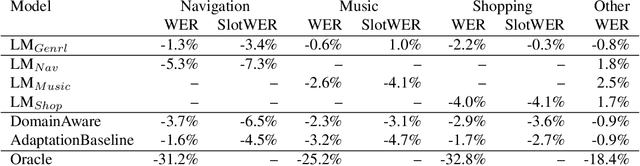
As voice assistants become more ubiquitous, they are increasingly expected to support and perform well on a wide variety of use-cases across different domains. We present a domain-aware rescoring framework suitable for achieving domain-adaptation during second-pass rescoring in production settings. In our framework, we fine-tune a domain-general neural language model on several domains, and use an LSTM-based domain classification model to select the appropriate domain-adapted model to use for second-pass rescoring. This domain-aware rescoring improves the word error rate by up to 2.4% and slot word error rate by up to 4.1% on three individual domains -- shopping, navigation, and music -- compared to domain general rescoring. These improvements are obtained while maintaining accuracy for the general use case.