 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Algorithms for Active Learning
Jul 31, 2017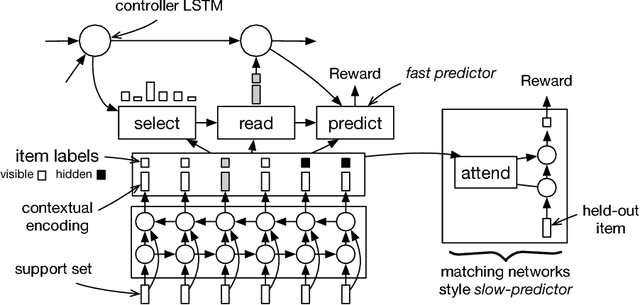
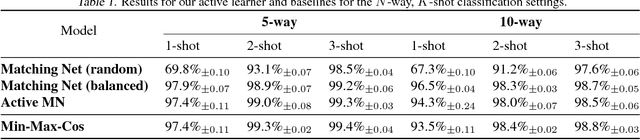
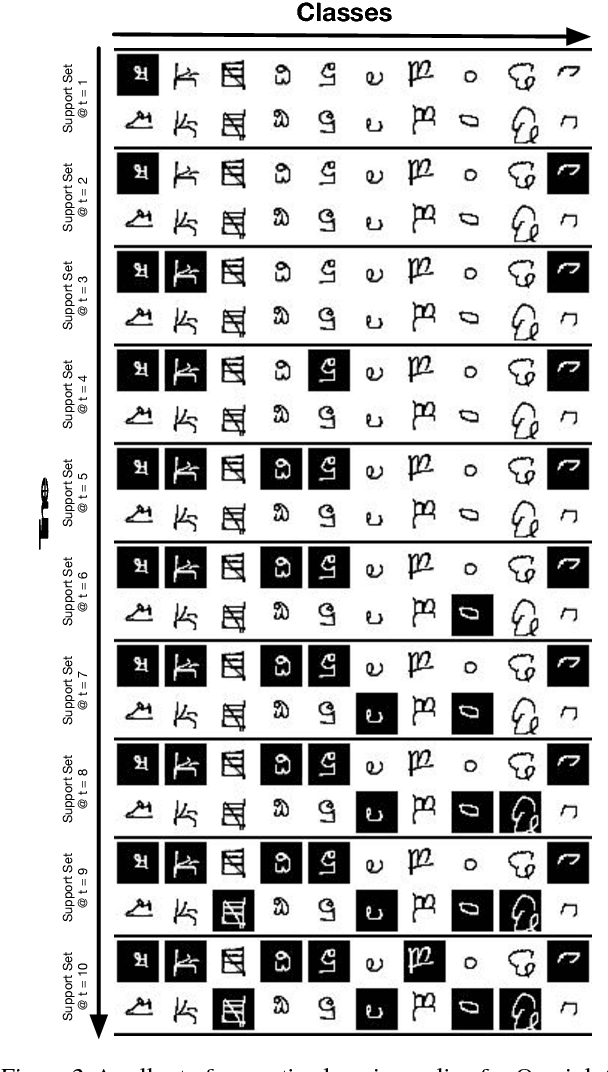
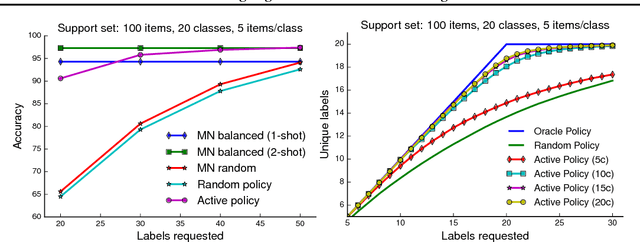
We introduce a model that learns active learning algorithms via metalearning. For a distribution of related tasks, our model jointly learns: a data representation, an item selection heuristic, and a method for constructing prediction functions from labeled training sets. Our model uses the item selection heuristic to gather labeled training sets from which to construct prediction functions. Using the Omniglot and MovieLens datasets, we test our model in synthetic and practical settings.
Plan, Attend, Generate: Character-level Neural Machine Translation with Planning in the Decoder
Jun 23, 2017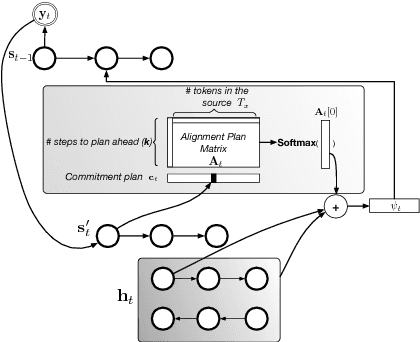
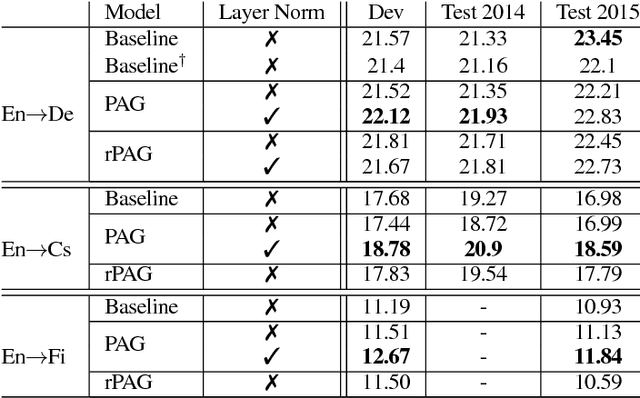
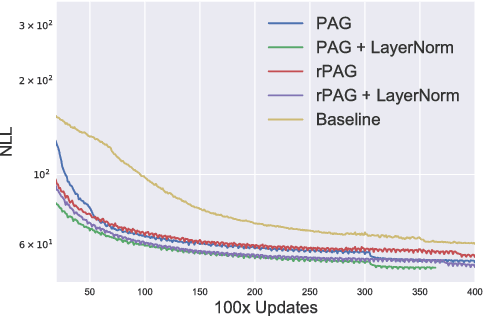

We investigate the integration of a planning mechanism into an encoder-decoder architecture with an explicit alignment for character-level machine translation. We develop a model that plans ahead when it computes alignments between the source and target sequences, constructing a matrix of proposed future alignments and a commitment vector that governs whether to follow or recompute the plan. This mechanism is inspired by the strategic attentive reader and writer (STRAW) model. Our proposed model is end-to-end trainable with fully differentiable operations. We show that it outperforms a strong baseline on three character-level decoder neural machine translation on WMT'15 corpus. Our analysis demonstrates that our model can compute qualitatively intuitive alignments and achieves superior performance with fewer parameters.
A Joint Model for Question Answering and Question Generation
Jun 05, 2017
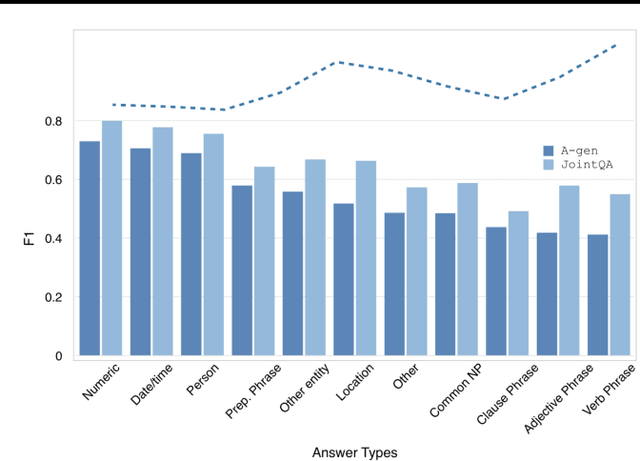

We propose a generative machine comprehension model that learns jointly to ask and answer questions based on documents. The proposed model uses a sequence-to-sequence framework that encodes the document and generates a question (answer) given an answer (question). Significant improvement in model performance is observed empirically on the SQuAD corpus, confirming our hypothesis that the model benefits from jointly learning to perform both tasks. We believe the joint model's novelty offers a new perspective on machine comprehension beyond architectural engineering, and serves as a first step towards autonomous information seeking.
Machine Comprehension by Text-to-Text Neural Question Generation
May 15, 2017
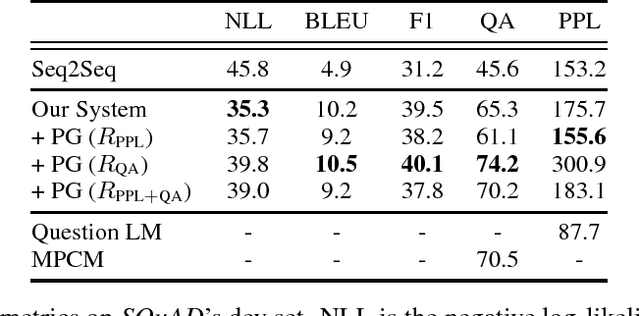


We propose a recurrent neural model that generates natural-language questions from documents, conditioned on answers. We show how to train the model using a combination of supervised and reinforcement learning. After teacher forcing for standard maximum likelihood training, we fine-tune the model using policy gradient techniques to maximize several rewards that measure question quality. Most notably, one of these rewards is the performance of a question-answering system. We motivate question generation as a means to improve the performance of question answering systems. Our model is trained and evaluated on the recent question-answering dataset SQuAD.
NewsQA: A Machine Comprehension Dataset
Feb 07, 2017

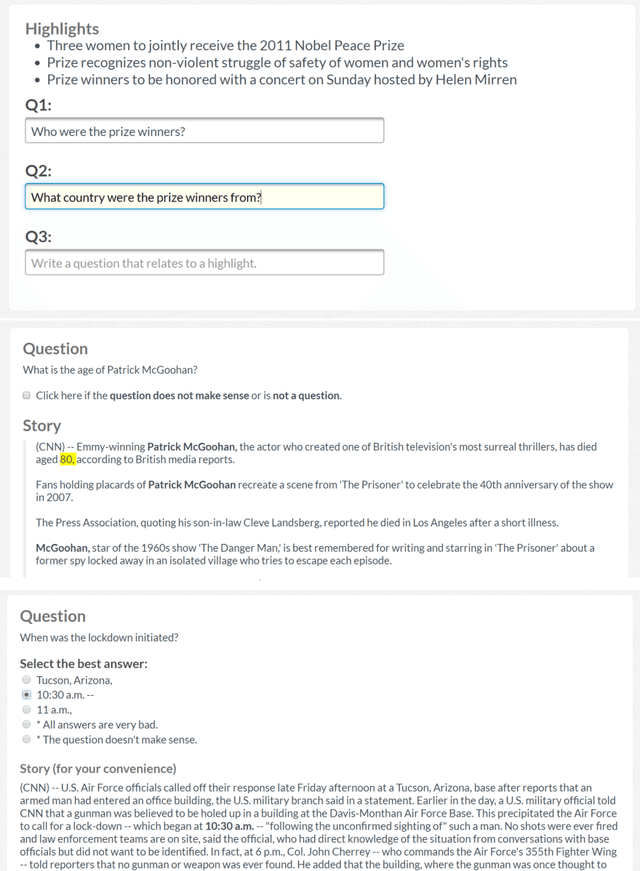
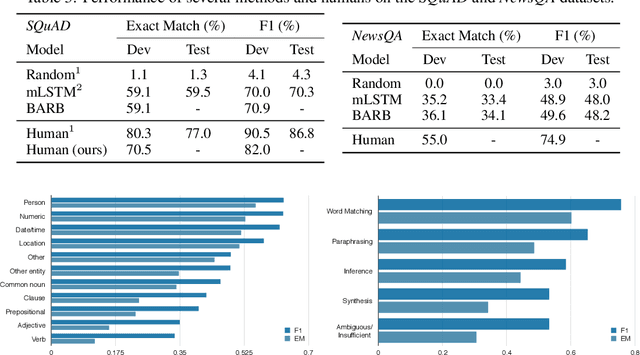
We present NewsQA, a challenging machine comprehension dataset of over 100,000 human-generated question-answer pairs. Crowdworkers supply questions and answers based on a set of over 10,000 news articles from CNN, with answers consisting of spans of text from the corresponding articles. We collect this dataset through a four-stage process designed to solicit exploratory questions that require reasoning. A thorough analysis confirms that NewsQA demands abilities beyond simple word matching and recognizing textual entailment. We measure human performance on the dataset and compare it to several strong neural models. The performance gap between humans and machines (0.198 in F1) indicates that significant progress can be made on NewsQA through future research. The dataset is freely available at https://datasets.maluuba.com/NewsQA.
Towards Information-Seeking Agents
Dec 08, 2016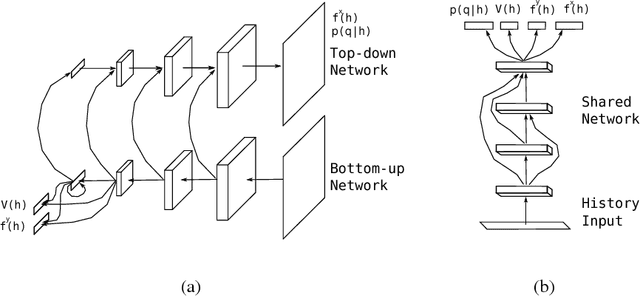



We develop a general problem setting for training and testing the ability of agents to gather information efficiently. Specifically, we present a collection of tasks in which success requires searching through a partially-observed environment, for fragments of information which can be pieced together to accomplish various goals. We combine deep architectures with techniques from reinforcement learning to develop agents that solve our tasks. We shape the behavior of these agents by combining extrinsic and intrinsic rewards. We empirically demonstrate that these agents learn to search actively and intelligently for new information to reduce their uncertainty, and to exploit information they have already acquired.
Iterative Alternating Neural Attention for Machine Reading
Nov 09, 2016



We propose a novel neural attention architecture to tackle machine comprehension tasks, such as answering Cloze-style queries with respect to a document. Unlike previous models, we do not collapse the query into a single vector, instead we deploy an iterative alternating attention mechanism that allows a fine-grained exploration of both the query and the document. Our model outperforms state-of-the-art baselines in standard machine comprehension benchmarks such as CNN news articles and the Children's Book Test (CBT) dataset.
Natural Language Comprehension with the EpiReader
Jun 10, 2016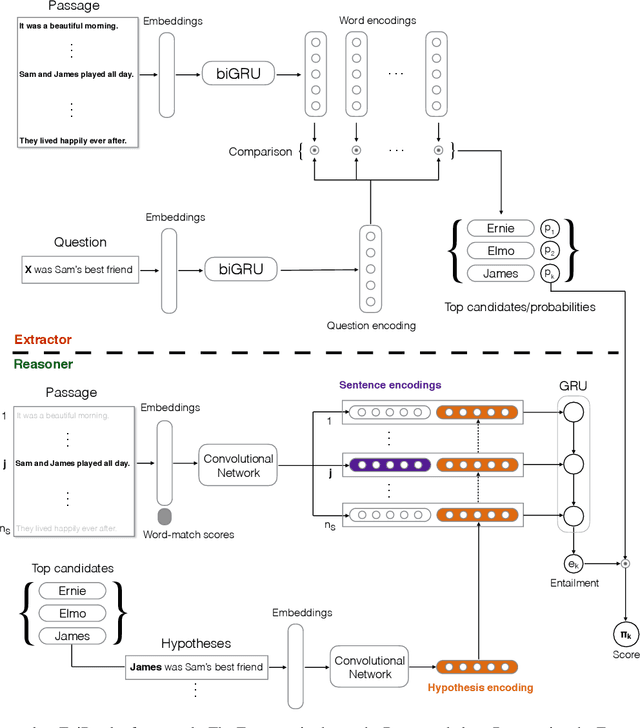

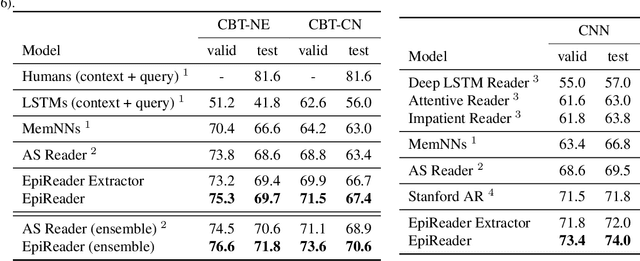

We present the EpiReader, a novel model for machine comprehension of text. Machine comprehension of unstructured, real-world text is a major research goal for natural language processing. Current tests of machine comprehension pose questions whose answers can be inferred from some supporting text, and evaluate a model's response to the questions. The EpiReader is an end-to-end neural model comprising two components: the first component proposes a small set of candidate answers after comparing a question to its supporting text, and the second component formulates hypotheses using the proposed candidates and the question, then reranks the hypotheses based on their estimated concordance with the supporting text. We present experiments demonstrating that the EpiReader sets a new state-of-the-art on the CNN and Children's Book Test machine comprehension benchmarks, outperforming previous neural models by a significant margin.
Synthesis of recurrent neural networks for dynamical system simulation
Jun 07, 2016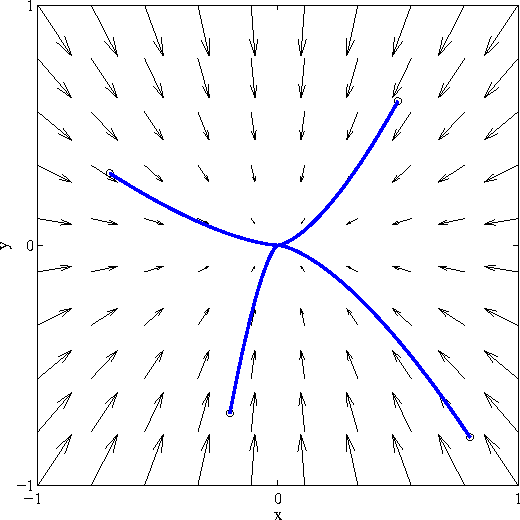


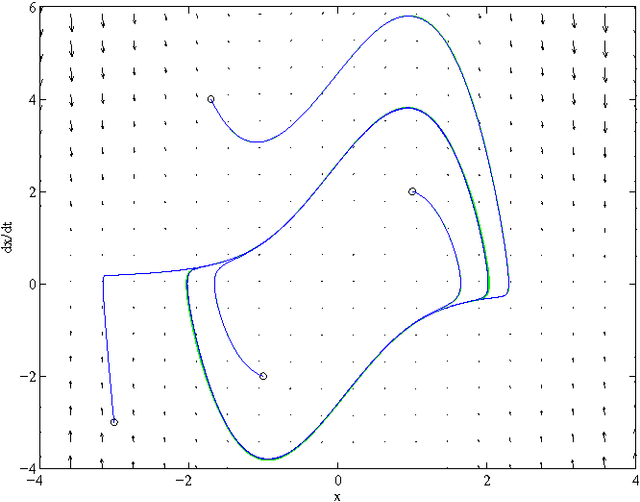
We review several of the most widely used techniques for training recurrent neural networks to approximate dynamical systems, then describe a novel algorithm for this task. The algorithm is based on an earlier theoretical result that guarantees the quality of the network approximation. We show that a feedforward neural network can be trained on the vector field representation of a given dynamical system using backpropagation, then recast, using matrix manipulations, as a recurrent network that replicates the original system's dynamics. After detailing this algorithm and its relation to earlier approaches, we present numerical examples that demonstrate its capabilities. One of the distinguishing features of our approach is that both the original dynamical systems and the recurrent networks that simulate them operate in continuous time.
A Parallel-Hierarchical Model for Machine Comprehension on Sparse Data
Mar 29, 2016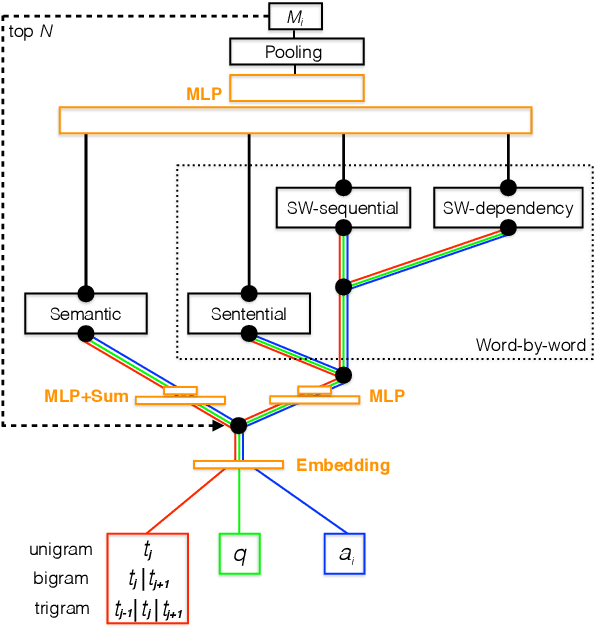
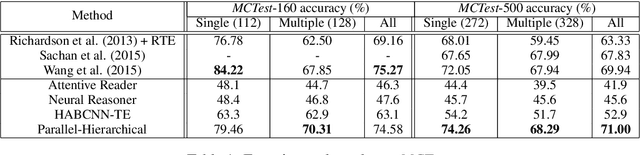
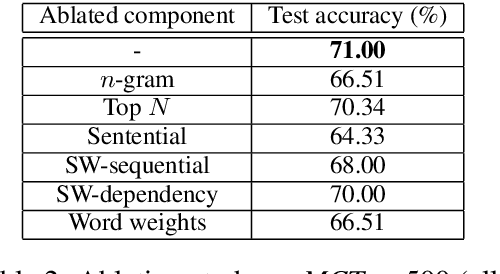
Understanding unstructured text is a major goal within natural language processing. Comprehension tests pose questions based on short text passages to evaluate such understanding. In this work, we investigate machine comprehension on the challenging {\it MCTest} benchmark. Partly because of its limited size, prior work on {\it MCTest} has focused mainly on engineering better features. We tackle the dataset with a neural approach, harnessing simple neural networks arranged in a parallel hierarchy. The parallel hierarchy enables our model to compare the passage, question, and answer from a variety of trainable perspectives, as opposed to using a manually designed, rigid feature set. Perspectives range from the word level to sentence fragments to sequences of sentences; the networks operate only on word-embedding representations of text. When trained with a methodology designed to help cope with limited training data, our Parallel-Hierarchical model sets a new state of the art for {\it MCTest}, outperforming previous feature-engineered approaches slightly and previous neural approaches by a significant margin (over 15\% absolute).