 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Resource-Efficient Compound AI Systems
Jan 29, 2025Compound AI Systems, integrating multiple interacting components like models, retrievers, and external tools, have emerged as essential for addressing complex AI tasks. However, current implementations suffer from inefficient resource utilization due to tight coupling between application logic and execution details, a disconnect between orchestration and resource management layers, and the perceived exclusiveness between efficiency and quality. We propose a vision for resource-efficient Compound AI Systems through a declarative workflow programming model and an adaptive runtime system for dynamic scheduling and resource-aware decision-making. Decoupling application logic from low-level details exposes levers for the runtime to flexibly configure the execution environment and resources, without compromising on quality. Enabling collaboration between the workflow orchestration and cluster manager enables higher efficiency through better scheduling and resource management. We are building a prototype system, called Murakkab, to realize this vision. Our preliminary evaluation demonstrates speedups up to $\sim 3.4\times$ in workflow completion times while delivering $\sim 4.5\times$ higher energy efficiency, showing promise in optimizing resources and advancing AI system design.
Treehouse: A Case For Carbon-Aware Datacenter Software
Jan 06, 2022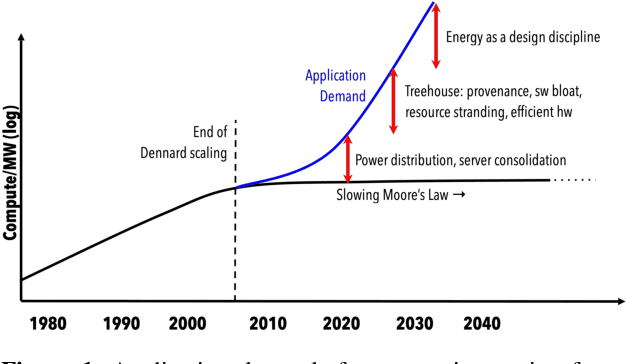
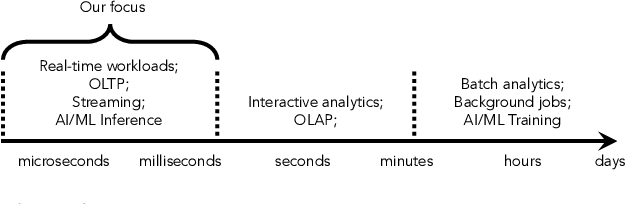
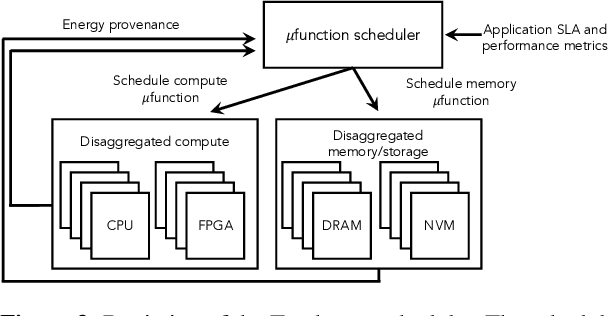
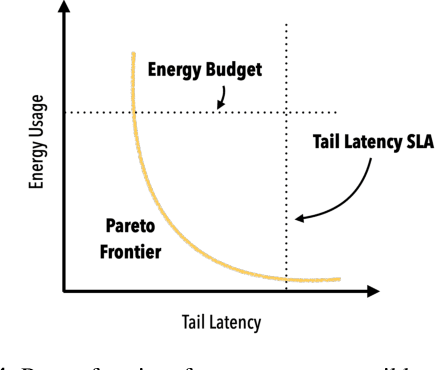
The end of Dennard scaling and the slowing of Moore's Law has put the energy use of datacenters on an unsustainable path. Datacenters are already a significant fraction of worldwide electricity use, with application demand scaling at a rapid rate. We argue that substantial reductions in the carbon intensity of datacenter computing are possible with a software-centric approach: by making energy and carbon visible to application developers on a fine-grained basis, by modifying system APIs to make it possible to make informed trade offs between performance and carbon emissions, and by raising the level of application programming to allow for flexible use of more energy efficient means of compute and storage. We also lay out a research agenda for systems software to reduce the carbon footprint of datacenter computing.
Efficient Strong Scaling Through Burst Parallel Training
Dec 19, 2021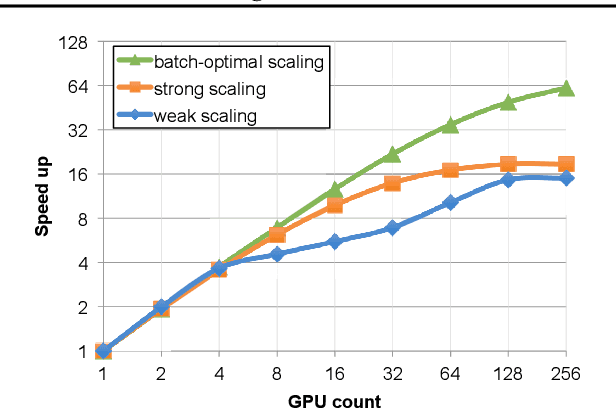
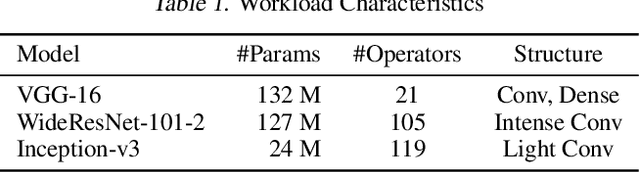
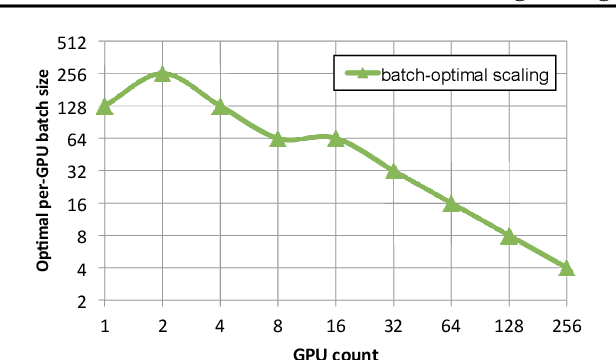

As emerging deep neural network (DNN) models continue to grow in size, using large GPU clusters to train DNNs is becoming an essential requirement to achieving acceptable training times. In this paper, we consider the case where future increases in cluster size will cause the global batch size that can be used to train models to reach a fundamental limit: beyond a certain point, larger global batch sizes cause sample efficiency to degrade, increasing overall time to accuracy. As a result, to achieve further improvements in training performance, we must instead consider "strong scaling" strategies that hold the global batch size constant and allocate smaller batches to each GPU. Unfortunately, this makes it significantly more difficult to use cluster resources efficiently. We present DeepPool, a system that addresses this efficiency challenge through two key ideas. First, burst parallelism allocates large numbers of GPUs to foreground jobs in bursts to exploit the unevenness in parallelism across layers. Second, GPU multiplexing prioritizes throughput for foreground training jobs, while packing in background training jobs to reclaim underutilized GPU resources, thereby improving cluster-wide utilization. Together, these two ideas enable DeepPool to deliver a 2.2 - 2.4x improvement in total cluster throughput over standard data parallelism with a single task when the cluster scale is large.