 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNegative Data Augmentation
Feb 09, 2021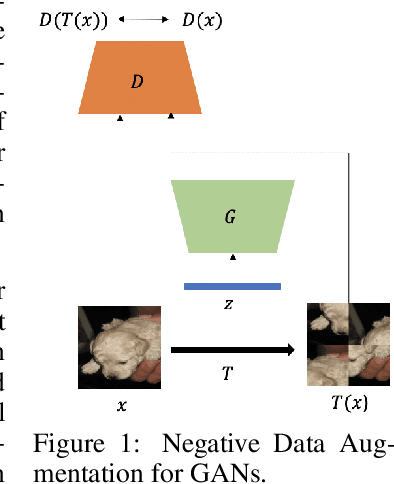



Data augmentation is often used to enlarge datasets with synthetic samples generated in accordance with the underlying data distribution. To enable a wider range of augmentations, we explore negative data augmentation strategies (NDA)that intentionally create out-of-distribution samples. We show that such negative out-of-distribution samples provide information on the support of the data distribution, and can be leveraged for generative modeling and representation learning. We introduce a new GAN training objective where we use NDA as an additional source of synthetic data for the discriminator. We prove that under suitable conditions, optimizing the resulting objective still recovers the true data distribution but can directly bias the generator towards avoiding samples that lack the desired structure. Empirically, models trained with our method achieve improved conditional/unconditional image generation along with improved anomaly detection capabilities. Further, we incorporate the same negative data augmentation strategy in a contrastive learning framework for self-supervised representation learning on images and videos, achieving improved performance on downstream image classification, object detection, and action recognition tasks. These results suggest that prior knowledge on what does not constitute valid data is an effective form of weak supervision across a range of unsupervised learning tasks.
Online Caching with Optimal Switching Regret
Jan 18, 2021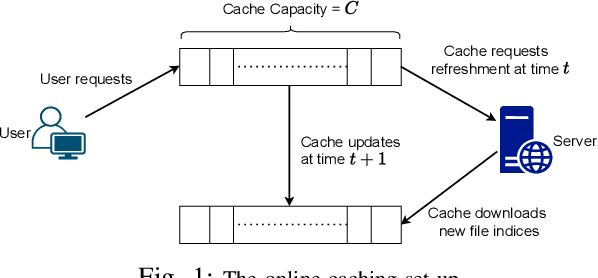
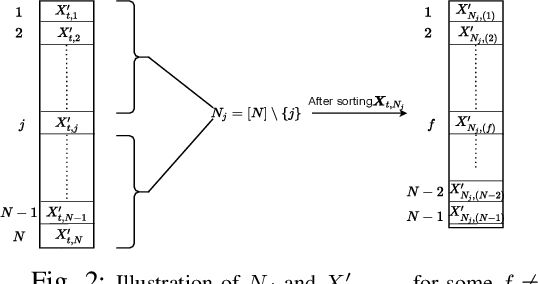
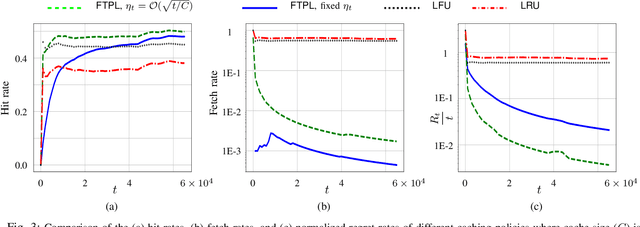
We consider the classical uncoded caching problem from an online learning point-of-view. A cache of limited storage capacity can hold $C$ files at a time from a large catalog. A user requests an arbitrary file from the catalog at each time slot. Before the file request from the user arrives, a caching policy populates the cache with any $C$ files of its choice. In the case of a cache-hit, the policy receives a unit reward and zero rewards otherwise. In addition to that, there is a cost associated with fetching files to the cache, which we refer to as the switching cost. The objective is to design a caching policy that incurs minimal regret while considering both the rewards due to cache-hits and the switching cost due to the file fetches. The main contribution of this paper is the switching regret analysis of a Follow the Perturbed Leader-based anytime caching policy, which is shown to have an order optimal switching regret. In this pursuit, we improve the best-known switching regret bound for this problem by a factor of $\Theta(\sqrt{C}).$ We conclude the paper by comparing the performance of different popular caching policies using a publicly available trace from a commercial CDN server.
Caching in Networks without Regret
Sep 17, 2020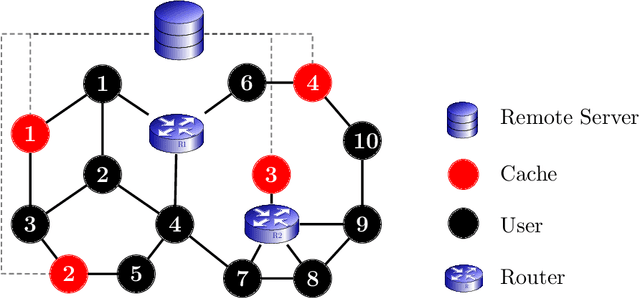
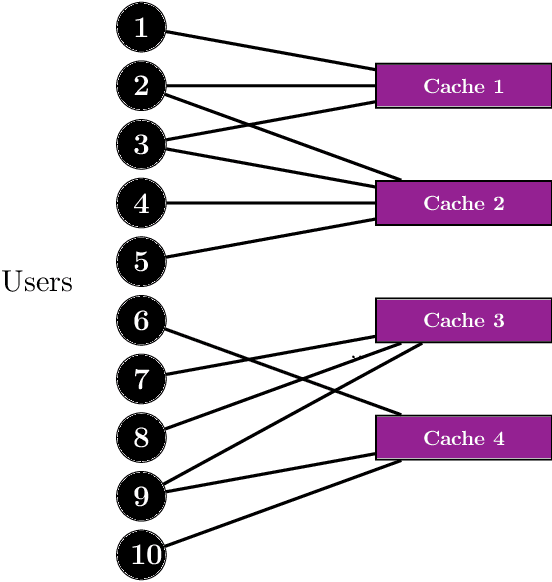
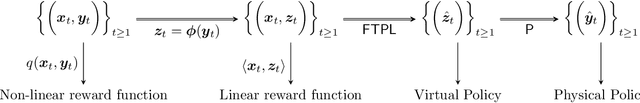
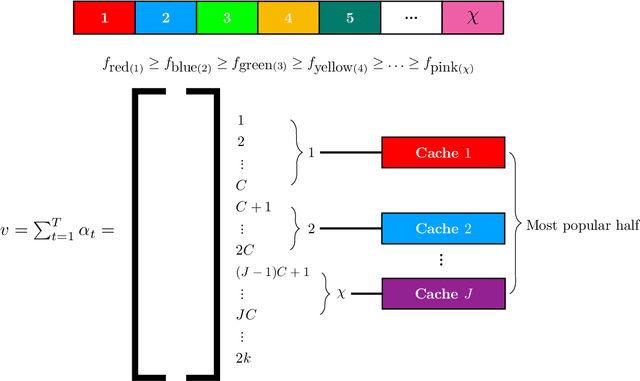
We consider the online $\textsf{Bipartite Caching}$ problem where $n$ users are connected to $m$ caches in the form of a bipartite network. Each of the $m$ caches has a file storage capacity of $C$. There is a library consisting of $N >C$ distinct files. Each user can request any one of the files from the library at each time slot. We allow the file request sequences to be chosen in an adversarial fashion. A user's request at a time slot is satisfied if the requested file is already hosted on at least one of the caches connected to the user at that time slot. Our objective is to design an efficient online caching policy with minimal regret. In this paper, we propose $\textsf{LeadCache,}$ an online caching policy based on the $\textsf{Follow the Perturbed Leader}$ (FTPL) paradigm. We show that $\textsf{LeadCache}$ is regret optimal up to a multiplicative factor of $\tilde{O}(n^{0.375}).$ As a byproduct of our analysis, we design a new linear-time deterministic Pipage rounding procedure for the LP relaxation of a well-known NP-hard combinatorial optimization problem in this area. Our new rounding algorithm substantially improves upon the currently best-known complexity for this problem. Moreover, we show the surprising result that under mild Strong-Law-type assumptions on the file request sequence, the rate of file fetches to the caches approaches to zero under the $\textsf{LeadCache}$ policy. Finally, we derive a tight universal regret lower bound for the $\textsf{Bipartite Caching}$ problem, which critically makes use of results from graph coloring theory and certifies the announced approximation ratio.
On the Benefits of Models with Perceptually-Aligned Gradients
May 04, 2020



Adversarial robust models have been shown to learn more robust and interpretable features than standard trained models. As shown in [\cite{tsipras2018robustness}], such robust models inherit useful interpretable properties where the gradient aligns perceptually well with images, and adding a large targeted adversarial perturbation leads to an image resembling the target class. We perform experiments to show that interpretable and perceptually aligned gradients are present even in models that do not show high robustness to adversarial attacks. Specifically, we perform adversarial training with attack for different max-perturbation bound. Adversarial training with low max-perturbation bound results in models that have interpretable features with only slight drop in performance over clean samples. In this paper, we leverage models with interpretable perceptually-aligned features and show that adversarial training with low max-perturbation bound can improve the performance of models for zero-shot and weakly supervised localization tasks.
Inducing Cooperative behaviour in Sequential-Social dilemmas through Multi-Agent Reinforcement Learning using Status-Quo Loss
Feb 13, 2020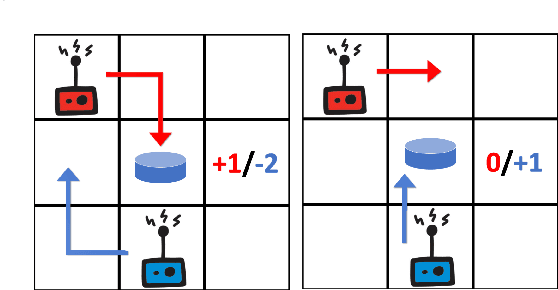

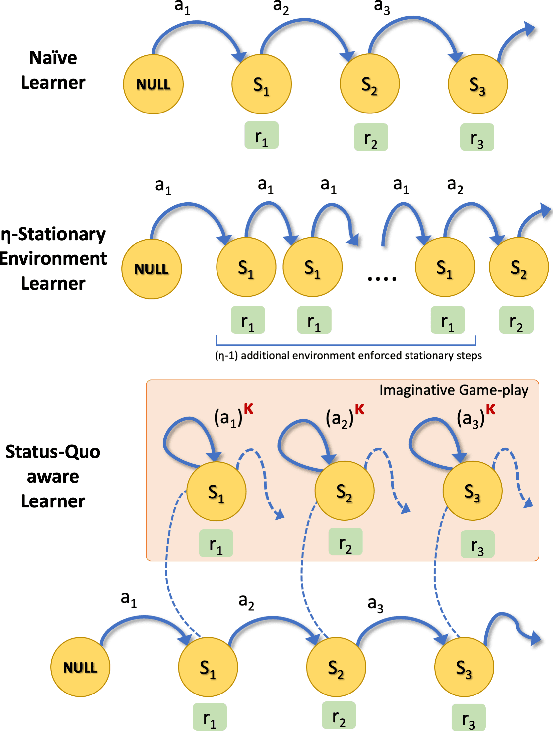
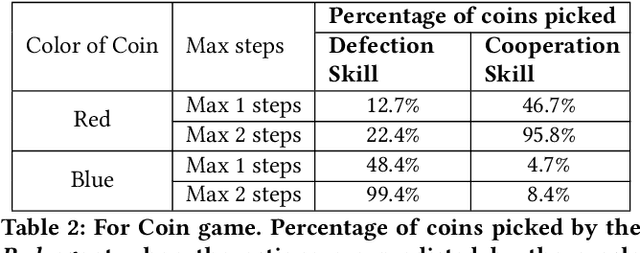
In social dilemma situations, individual rationality leads to sub-optimal group outcomes. Several human engagements can be modeled as a sequential (multi-step) social dilemmas. However, in contrast to humans, Deep Reinforcement Learning agents trained to optimize individual rewards in sequential social dilemmas converge to selfish, mutually harmful behavior. We introduce a status-quo loss (SQLoss) that encourages an agent to stick to the status quo, rather than repeatedly changing its policy. We show how agents trained with SQLoss evolve cooperative behavior in several social dilemma matrix games. To work with social dilemma games that have visual input, we propose GameDistill. GameDistill uses self-supervision and clustering to automatically extract cooperative and selfish policies from a social dilemma game. We combine GameDistill and SQLoss to show how agents evolve socially desirable cooperative behavior in the Coin Game.
On the Benefits of Attributional Robustness
Dec 10, 2019
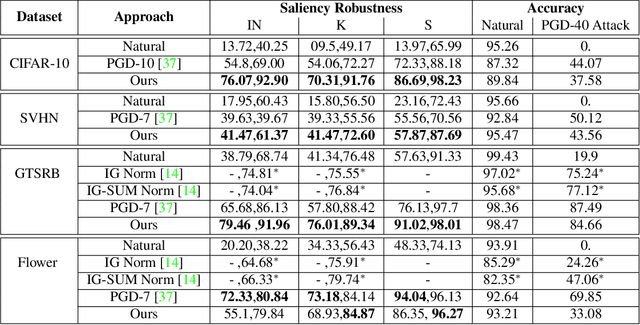
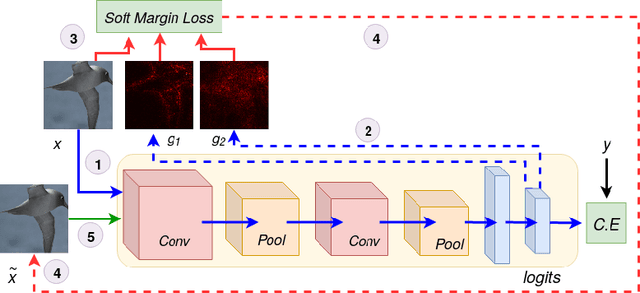
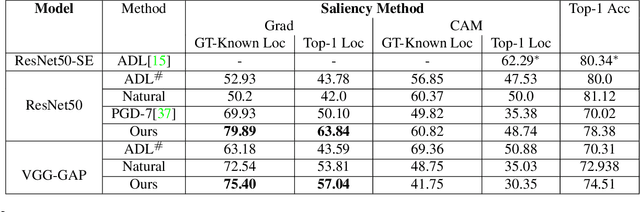
Interpretability is an emerging area of research in trustworthy machine learning. Safe deployment of machine learning system mandates that the prediction and its explanation be reliable and robust. Recently, it was shown that one could craft perturbations that produce perceptually indistinguishable inputs having the same prediction, yet very different interpretations. We tackle the problem of attributional robustness (i.e. models having robust explanations) by maximizing the alignment between the input image and its saliency map using soft-margin triplet loss. We propose a robust attribution training methodology that beats the state-of-the-art attributional robustness measure by a margin of approximately 6-18% on several standard datasets, ie. SVHN, CIFAR-10 and GTSRB. We further show the utility of the proposed robust model in the domain of weakly supervised object localization and segmentation. Our proposed robust model also achieves a new state-of-the-art object localization accuracy on the CUB-200 dataset.
cFineGAN: Unsupervised multi-conditional fine-grained image generation
Dec 06, 2019
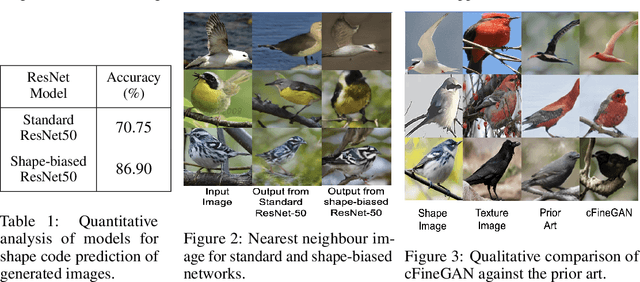


We propose an unsupervised multi-conditional image generation pipeline: cFineGAN, that can generate an image conditioned on two input images such that the generated image preserves the texture of one and the shape of the other input. To achieve this goal, we extend upon the recently proposed work of FineGAN \citep{singh2018finegan} and make use of standard as well as shape-biased pre-trained ImageNet models. We demonstrate both qualitatively as well as quantitatively the benefit of using the shape-biased network. We present our image generation result across three benchmark datasets- CUB-200-2011, Stanford Dogs and UT Zappos50k.
A Method for Computing Class-wise Universal Adversarial Perturbations
Dec 01, 2019
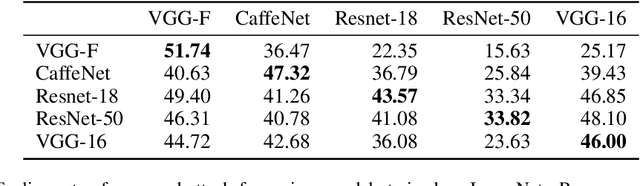
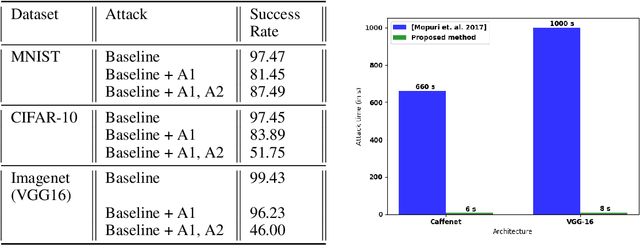
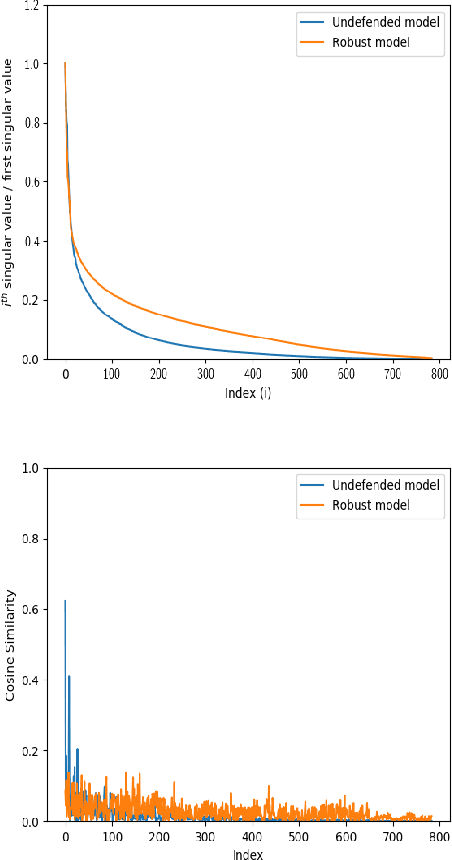
We present an algorithm for computing class-specific universal adversarial perturbations for deep neural networks. Such perturbations can induce misclassification in a large fraction of images of a specific class. Unlike previous methods that use iterative optimization for computing a universal perturbation, the proposed method employs a perturbation that is a linear function of weights of the neural network and hence can be computed much faster. The method does not require any training data and has no hyper-parameters. The attack obtains 34% to 51% fooling rate on state-of-the-art deep neural networks on ImageNet and transfers across models. We also study the characteristics of the decision boundaries learned by standard and adversarially trained models to understand the universal adversarial perturbations.
Intrusion Detection using Sequential Hybrid Model
Oct 29, 2019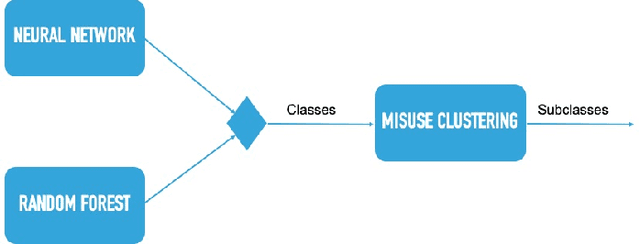
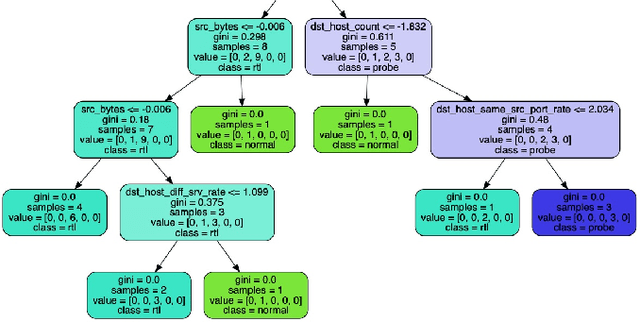
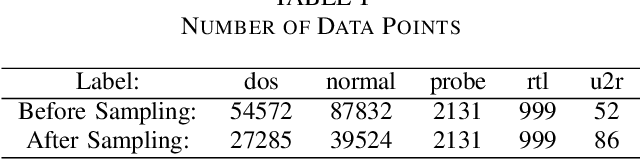
A large amount of work has been done on the KDD 99 dataset, most of which includes the use of a hybrid anomaly and misuse detection model done in parallel with each other. In order to further classify the intrusions, our approach to network intrusion detection includes use of two different anomaly detection models followed by misuse detection applied on the combined output obtained from the previous step. The end goal of this is to verify the anomalies detected by the anomaly detection algorithm and clarify whether they are actually intrusions or random outliers from the trained normal (and thus to try and reduce the number of false positives). We aim to detect a pattern in this novel intrusion technique itself, and not the handling of such intrusions. The intrusions were detected to a very high degree of accuracy.
Charting the Right Manifold: Manifold Mixup for Few-shot Learning
Aug 07, 2019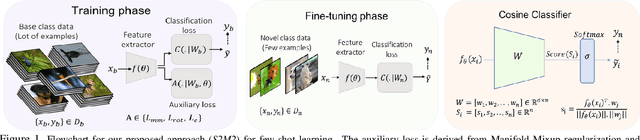
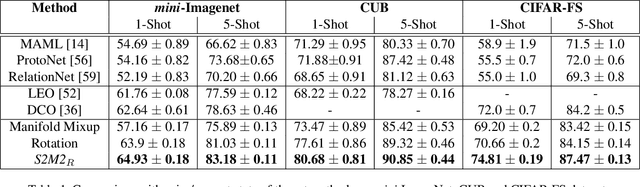
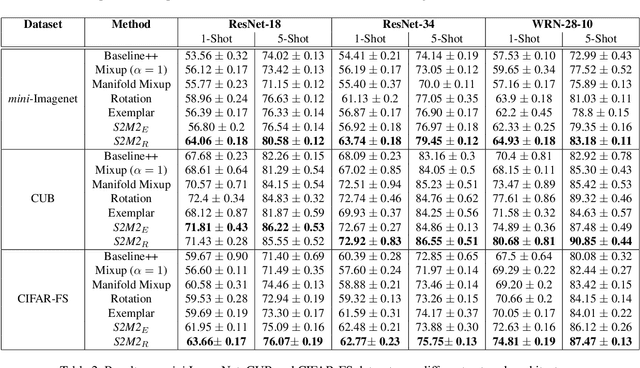
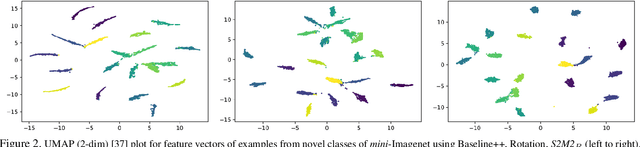
Few-shot learning algorithms aim to learn model parameters capable of adapting to unseen classes with the help of only a few labeled examples. A recent regularization technique - Manifold Mixup focuses on learning a general-purpose representation, robust to small changes in the data distribution. Since the goal of few-shot learning is closely linked to robust representation learning, we study Manifold Mixup in this problem setting. Self-supervised learning is another technique that learns semantically meaningful features, using only the inherent structure of the data. This work investigates the role of learning relevant feature manifold for few-shot tasks using self-supervision and regularization techniques. We observe that regularizing the feature manifold, enriched via self-supervised techniques, with Manifold Mixup significantly improves few-shot learning performance. We show that our proposed method S2M2 beats the current state-of-the-art accuracy on standard few-shot learning datasets like CIFAR-FS, CUB and mini-ImageNet by 3-8%. Through extensive experimentation, we show that the features learned using our approach generalize to complex few-shot evaluation tasks, cross-domain scenarios and are robust against slight changes to data distribution.