 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGrad-CAM: Why did you say that?
Jan 25, 2017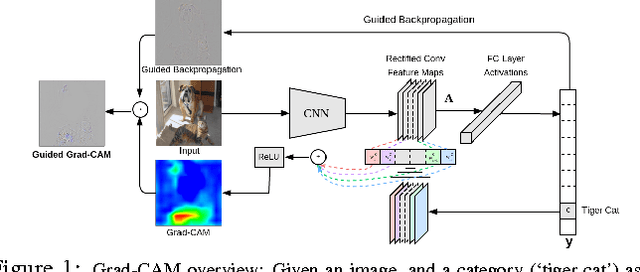
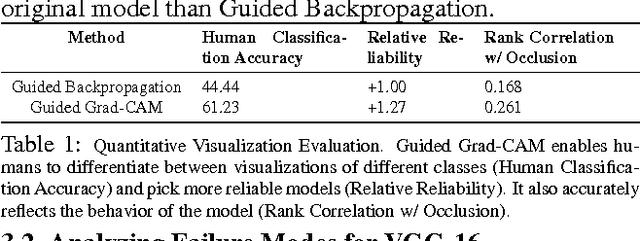
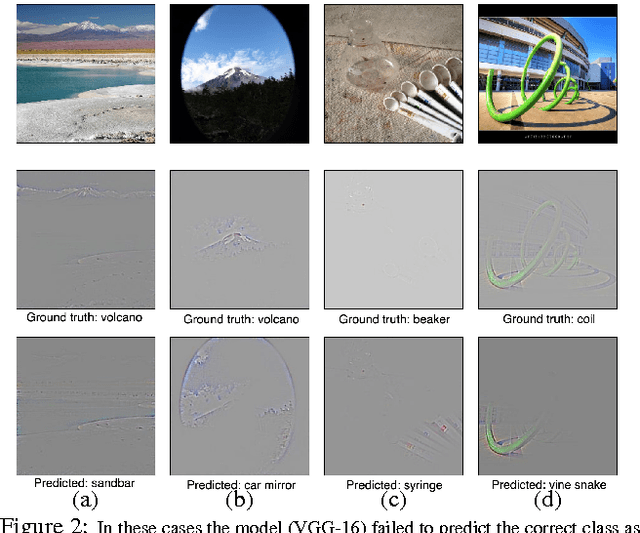
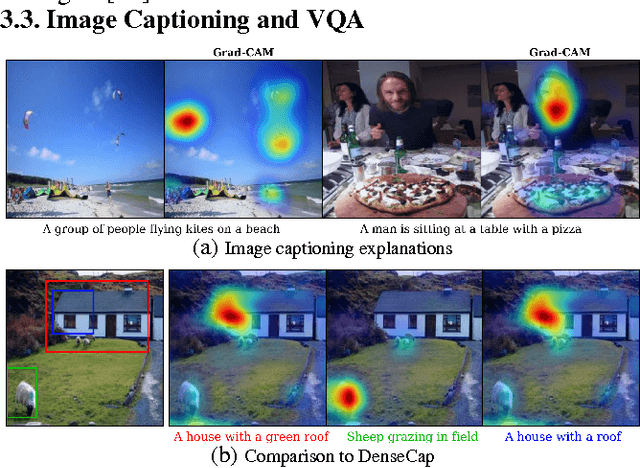
We propose a technique for making Convolutional Neural Network (CNN)-based models more transparent by visualizing input regions that are 'important' for predictions -- or visual explanations. Our approach, called Gradient-weighted Class Activation Mapping (Grad-CAM), uses class-specific gradient information to localize important regions. These localizations are combined with existing pixel-space visualizations to create a novel high-resolution and class-discriminative visualization called Guided Grad-CAM. These methods help better understand CNN-based models, including image captioning and visual question answering (VQA) models. We evaluate our visual explanations by measuring their ability to discriminate between classes, to inspire trust in humans, and their correlation with occlusion maps. Grad-CAM provides a new way to understand CNN-based models. We have released code, an online demo hosted on CloudCV, and a full version of this extended abstract.
Human Attention in Visual Question Answering: Do Humans and Deep Networks Look at the Same Regions?
Jun 17, 2016
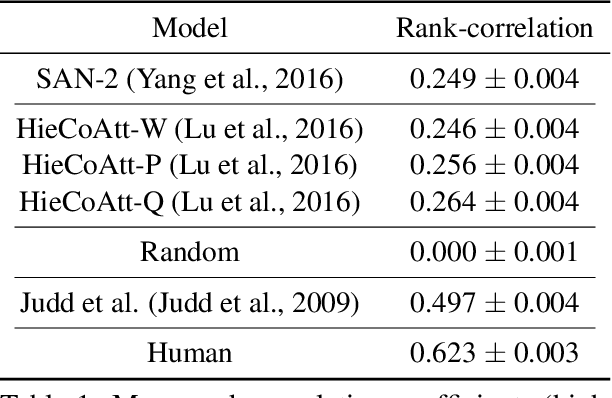


We conduct large-scale studies on `human attention' in Visual Question Answering (VQA) to understand where humans choose to look to answer questions about images. We design and test multiple game-inspired novel attention-annotation interfaces that require the subject to sharpen regions of a blurred image to answer a question. Thus, we introduce the VQA-HAT (Human ATtention) dataset. We evaluate attention maps generated by state-of-the-art VQA models against human attention both qualitatively (via visualizations) and quantitatively (via rank-order correlation). Overall, our experiments show that current attention models in VQA do not seem to be looking at the same regions as humans.
Elimination of Specular reflection and Identification of ROI: The First Step in Automated Detection of Cervical Cancer using Digital Colposcopy
Aug 11, 2011Cervical Cancer is one of the most common forms of cancer in women worldwide. Most cases of cervical cancer can be prevented through screening programs aimed at detecting precancerous lesions. During Digital Colposcopy, Specular Reflections (SR) appear as bright spots heavily saturated with white light. These occur due to the presence of moisture on the uneven cervix surface, which act like mirrors reflecting light from the illumination source. Apart from camouflaging the actual features, the SR also affects subsequent segmentation routines and hence must be removed. Our novel technique eliminates the SR and makes the colposcopic images (cervigram) ready for segmentation algorithms. The cervix region occupies about half of the cervigram image. Other parts of the image contain irrelevant information, such as equipment, frames, text and non-cervix tissues. This irrelevant information can confuse automatic identification of the tissues within the cervix. The first step is, therefore, focusing on the cervical borders, so that we have a geometric boundary on the relevant image area. We have proposed a type of modified kmeans clustering algorithm to evaluate the region of interest.
* IEEE Imaging Systems and Techniques, 2011, Print ISBN: 978-1-61284-894-5, pages 237 - 241
Preprocessing for Automating Early Detection of Cervical Cancer
Aug 11, 2011Uterine Cervical Cancer is one of the most common forms of cancer in women worldwide. Most cases of cervical cancer can be prevented through screening programs aimed at detecting precancerous lesions. During Digital Colposcopy, colposcopic images or cervigrams are acquired in raw form. They contain specular reflections which appear as bright spots heavily saturated with white light and occur due to the presence of moisture on the uneven cervix surface and. The cervix region occupies about half of the raw cervigram image. Other parts of the image contain irrelevant information, such as equipment, frames, text and non-cervix tissues. This irrelevant information can confuse automatic identification of the tissues within the cervix. Therefore we focus on the cervical borders, so that we have a geometric boundary on the relevant image area. Our novel technique eliminates the SR, identifies the region of interest and makes the cervigram ready for segmentation algorithms.
Preprocessing: A Step in Automating Early Detection of Cervical Cancer
Aug 11, 2011This paper has been withdrawn